Artificial Intelligence
Improve AI assistant response accuracy using Knowledge Bases for Amazon Bedrock and a reranking model
AI chatbots and virtual assistants have become increasingly popular in recent years thanks the breakthroughs of large language models (LLMs). Trained on a large volume of datasets, these models incorporate memory components in their architectural design, allowing them to understand and comprehend textual context.
Most common use cases for chatbot assistants focus on a few key areas, including enhancing customer experiences, boosting employee productivity and creativity, or optimizing business processes. For instance, customer support, troubleshooting, and internal and external knowledge-based search.
Despite these capabilities, a key challenge with chatbots is generating high-quality and accurate responses. One way of solving this challenge is to use Retrieval Augmented Generation (RAG). RAG is the process of optimizing the output of an LLM so it references an authoritative knowledge base outside of its training data sources before generating a response. Reranking seeks to improve search relevance by reordering the result set returned by a retriever with a different model. In this post, we explain how two techniques—RAG and reranking—can help improve chatbot responses using Knowledge Bases for Amazon Bedrock.
Solution overview
RAG is a technique that combines the strengths of knowledge base retrieval and generative models for text generation. It works by first retrieving relevant responses from a database, then using those responses as context to feed the generative model to produce a final output. Using a RAG approach for building a chatbot has many advantages. For example, retrieving responses from its database before generating a response could provide more relevant and coherent responses. This helps improve the conversational flow. RAG also scales better with more data compared to pure generative models, and it doesn’t require fine-tuning of the model when new data is added to the knowledge base. Additionally, the retrieval component enables the model to incorporate external knowledge by retrieving relevant background information from its database. This approach helps provide factual, in-depth, and knowledgeable responses.
To find an answer, RAG takes an approach that uses vector search across the documents. The advantage of using vector search is speed and scalability. Rather than scanning every single document to find the answer, with the RAG approach, you turn the texts (knowledge base) into embeddings and store these embeddings in the database. The embeddings are a compressed version of the documents, represented by an array of numerical values. After the embeddings are stored, the vector search queries the vector database to find the similarity based on the vectors associated with the documents. Typically, a vector search will return the top k most relevant documents based on the user question, and return the k results. However, because the similarity algorithm in a vector database works on vectors and not documents, vector search doesn’t always return the most relevant information in the top k results. This directly impacts the accuracy of the response if the most relevant contexts aren’t available to the LLM.
Reranking is a technique that can further improve the responses by selecting the best option out of several candidate responses. The following architecture illustrates how a reranking solution could work.
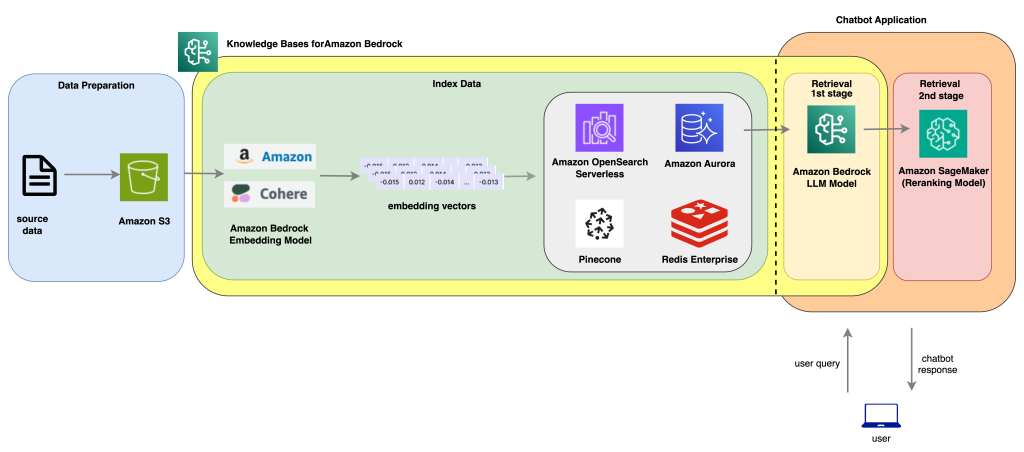
Architecture diagram for Reranking model integration with Knowledge Bases for Bedrock
Let’s create a question answering solution, where we ingest The Great Gatsby, a 1925 novel by American writer F. Scott Fitzgerald. This book is publicly available through Project Gutenberg. We use Knowledge Bases for Amazon Bedrock to implement the end-to-end RAG workflow and ingest the embeddings into an Amazon OpenSearch Serverless vector search collection. We then retrieve answers using standard RAG and a two-stage RAG, which involves a reranking API. We then compare results from these two methods.
The code sample is available in this GitHub repo.
In the following sections, we walk through the high-level steps:
- Prepare the dataset.
- Generate questions from the document using an Amazon Bedrock LLM.
- Create a knowledge base that contains this book.
- Retrieve answers using the knowledge base
retrieveAPI - Evaluate the response using the RAGAS
- Retrieve answers again by running a two-stage RAG, using the knowledge base
retrieveAPI and then applying reranking on the context. - Evaluate the two-stage RAG response using the RAGAS framework.
- Compare the results and the performance of each RAG approach.
For efficiency purposes, we provided sample code in a notebook used to generate a set of questions and answers. These Q&A pairs are used in the RAG evaluation process. We highly recommend having a human to validate each question and answer for accuracy.
The following sections explains major steps with the help of code blocks.
Prerequisites
To clone the GitHub repository to your local machine, open a terminal window and run the following commands:
Prepare the dataset
Download the book from the Project Gutenberg website. For this post, we create 10 large documents from this book and upload them to Amazon Simple Storage Service (Amazon S3):
Create Knowledge Base for Bedrock
If you’re new to using Knowledge Bases for Amazon Bedrock, refer to Knowledge Bases for Amazon Bedrock now supports Amazon Aurora PostgreSQL and Cohere embedding models, where we described how Knowledge Bases for Amazon Bedrock manages the end-to-end RAG workflow.
In this step, you create a knowledge base using a Boto3 client. You use Amazon Titan Text Embedding v2 to convert the documents into embeddings (‘embeddingModelArn’) and point to the S3 bucket you created earlier as the data source (dataSourceConfiguration):
Generate questions from the document
We use Anthropic Claude on Amazon Bedrock to generate a list of 10 questions and the corresponding answers. The Q&A data serves as the foundation for the RAG evaluation based on the approaches that we are going to implement. We define the generated answers from this step as ground truth data. See the following code:
Retrieve answers using the knowledge base APIs
We use the generated questions and retrieve answers from the knowledge base using the retrieve and converse APIs:
Evaluate the RAG response using the RAGAS framework
We now evaluate the effectiveness of the RAG using a framework called RAGAS. The framework provides a suite of metrics to evaluate different dimensions. In our example, we evaluate responses based on the following dimensions:
- Answer relevancy – This metric focuses on assessing how pertinent the generated answer is to the given prompt. A lower score is assigned to answers that are incomplete or contain redundant information. This metric is computed using the question and the answer, with values ranging between 0–1, where higher scores indicate better relevancy.
- Answer similarity – This assesses the semantic resemblance between the generated answer and the ground truth. This evaluation is based on the ground truth and the answer, with values falling within the range of 0–1. A higher score signifies a better alignment between the generated answer and the ground truth.
- Context relevancy – This metric gauges the relevancy of the retrieved context, calculated based on both the question and contexts. The values fall within the range of 0–1, with higher values indicating better relevancy.
- Answer correctness – The assessment of answer correctness involves gauging the accuracy of the generated answer when compared to the ground truth. This evaluation relies on the ground truth and the answer, with scores ranging from 0–1. A higher score indicates a closer alignment between the generated answer and the ground truth, signifying better correctness.
A summarized report for standard RAG approach based on RAGAS evaluation:
answer_relevancy: 0.9006225160334027
answer_similarity: 0.7400904157096762
answer_correctness: 0.32703043056663855
context_relevancy: 0.024797687553157175
Two-stage RAG: Retrieve and rerank
Now that you have the results with the retrieve_and_generate API, let’s explore the two-stage retrieval approach by extending the standard RAG approach to integrate with a reranking model. In the context of RAG, reranking models are used after an initial set of contexts are retrieved by the retriever. The reranking model takes in the list of results and reranks each one based on the similarity between the context and the user query. In our example, we use a powerful reranking model called bge-reranker-large. The model is available in the Hugging Face Hub and is also free for commercial use. In the following code, we use the knowledge base’s retrieve API so we can get the handle on the context, and rerank it using the reranking model deployed as an Amazon SageMaker endpoint. We provide the sample code for deploying the reranking model in SageMaker in the GitHub repository. Here’s a code snippet that demonstrates two-stage retrieval process:
Evaluate the two-stage RAG response using the RAGAS framework
We evaluate the answers generated by the two-stage retrieval process. The following is a summarized report based on RAGAS evaluation:
answer_relevancy: 0.841581671275458
answer_similarity: 0.7961827348349313
answer_correctness: 0.43361356731293665
context_relevancy: 0.06049484724216884
Compare the results
Let’s compare the results from our tests. As shown in the following figure, the reranking API improves context relevancy, answer correctness, and answer similarity, which are important for improving the accuracy of the RAG process.
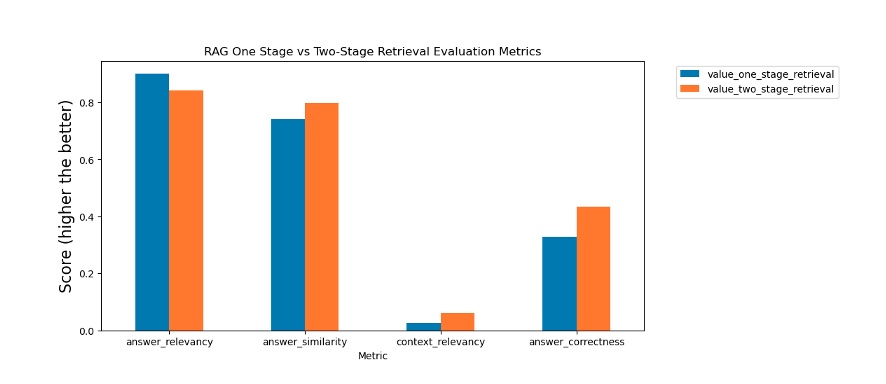
RAG vs Two Stage Retrieval evaluation metrics
Similarly, we also measured the RAG latency for both approaches. The results can be shown in the following metrics and the corresponding chart:
Standard RAG latency: 76.59s
Two Stage Retrieval latency: 312.12s
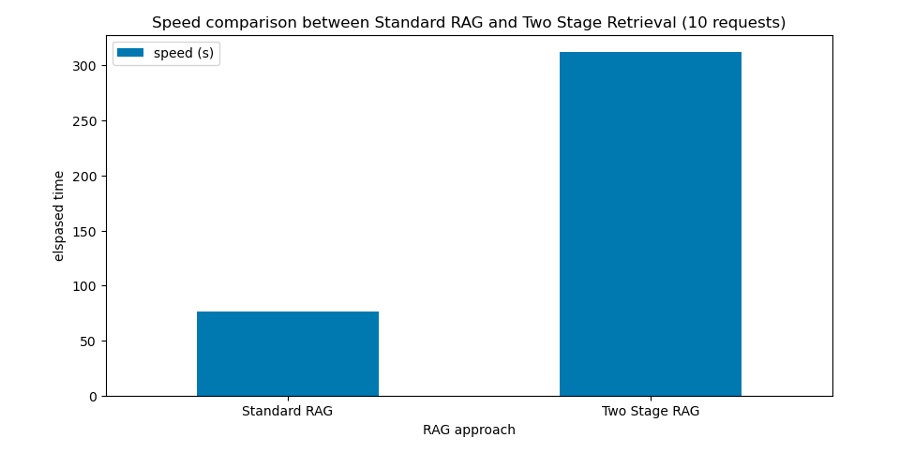
Latency metric for RAG and Two Stage Retrieval process
In summary, using a reranking model (tge-reranker-large) hosted on an ml.m5.xlarge instance yields approximately four times the latency compared to the standard RAG approach. We recommend testing with different reranking model variants and instance types to obtain the optimal performance for your use case.
Conclusion
In this post, we demonstrated how to implement a two-stage retrieval process by integrating a reranking model. We explored how integrating a reranking model with Knowledge Bases for Amazon Bedrock can provide better performance. Finally, we used RAGAS, an open source framework, to provide context relevancy, answer relevancy, answer similarity, and answer correctness metrics for both approaches.
Try out this retrieval process today, and share your feedback in the comments.
About the Author
 Wei Teh is an Machine Learning Solutions Architect at AWS. He is passionate about helping customers achieve their business objectives using cutting-edge machine learning solutions. Outside of work, he enjoys outdoor activities like camping, fishing, and hiking with his family.
Wei Teh is an Machine Learning Solutions Architect at AWS. He is passionate about helping customers achieve their business objectives using cutting-edge machine learning solutions. Outside of work, he enjoys outdoor activities like camping, fishing, and hiking with his family.
 Pallavi Nargund is a Principal Solutions Architect at AWS. In her role as a cloud technology enabler, she works with customers to understand their goals and challenges, and give prescriptive guidance to achieve their objective with AWS offerings. She is passionate about women in technology and is a core member of Women in AI/ML at Amazon. She speaks at internal and external conferences such as AWS re:Invent, AWS Summits, and webinars. Outside of work she enjoys volunteering, gardening, cycling and hiking.
Pallavi Nargund is a Principal Solutions Architect at AWS. In her role as a cloud technology enabler, she works with customers to understand their goals and challenges, and give prescriptive guidance to achieve their objective with AWS offerings. She is passionate about women in technology and is a core member of Women in AI/ML at Amazon. She speaks at internal and external conferences such as AWS re:Invent, AWS Summits, and webinars. Outside of work she enjoys volunteering, gardening, cycling and hiking.
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
 Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Mani Khanuja is a Tech Lead – Generative AI Specialists, author of the book Applied Machine Learning and High Performance Computing on AWS, and a member of the Board of Directors for Women in Manufacturing Education Foundation Board. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.