Artificial Intelligence
Part 4: How NatWest Group migrated ML models to Amazon SageMaker architectures
The adoption of AWS cloud technology at NatWest Group means moving our machine learning (ML) workloads to a more robust and scalable solution, while reducing our time-to-live to deliver the best products and services for our customers.
In this cloud adoption journey, we selected the Customer Lifetime Value (CLV) model to migrate to AWS. The model enables us to understand our customers better and deliver personalized solutions. The CLV model consists of a series of separate ML models that are brought together into a single pipeline. This requires a scalable solution, given the amount of data it processes.
This is the final post in a four-part series detailing how NatWest Group partnered with AWS Professional Services to build a scalable, secure, and sustainable MLOps platform. This post is intended for ML engineers, data scientists, and C-suites executives who want to understand how to build complex solutions using Amazon SageMaker. It proves the platform’s flexibility by demonstrating how, given some starter code templates, you can deliver a complex, scalable use case quickly and repeatably.
Read the entire series:
|
Challenges
NatWest Group, on its mission to delight its customers while remaining in line with regulatory obligations, has been working with AWS to build a standardized and secure solution to implement and productionize ML workloads. Previous implementations in the organization led to data silos and long lead times for environments spin up and spin down. This has also led to underutilized compute resources. To help improve this, AWS and NatWest collaborated to develop a series of ML project and environment templates using AWS services.
NatWest Group is using ML to derive new insights so we can predict and adapt to our customers’ future banking needs across the bank’s retail, wealth, and commercial operations. When developing a model and deploying it to production, many considerations need to be addressed to ensure compliance with the bank’s standards. These include requirements on model explainability, bias, data quality, and drift monitoring. The templates developed through this collaboration incorporate features to assess these points, and are now used by NatWest teams to onboard and productionize their use cases in a secure multi-account setup using SageMaker.
The templates embed standards for production-ready ML workflows by incorporating AWS best practices using MLOps capabilities in SageMaker. They also include a set of self-service, secure, multi-account infrastructure deployments for AWS ML services and data services via Amazon Simple Storage Service (Amazon S3).
The templates help use case teams within NatWest to do the following:
- Building capabilities in line with the NatWest MLOps maturity model
- Implement AWS best practices for MLOps capabilities in SageMaker services
- Create and use templated standards to develop production-ready ML workflows
- Provide self-service, secure infrastructure deployment for AWS ML services
- Reduce time to spin up and spin down environments for projects using a managed approach
- Reduce the cost of maintenance due to standardization of processes, automation, and on-demand compute
- Productionize code, which allows for the migration of existing models where code is functionally decomposed to take advantage of on-demand cloud architectures while improving code readability and remove technical debt
- Use continuous integration, deployment, and training for proof of concept (PoC) and use case development, as well as enable additional MLOps features (model monitoring, explainability, and condition steps)
The following sections discuss how NatWest uses these templates to migrate existing projects or create new ones.
Custom SageMaker templates and architecture
NatWest and AWS built custom project templates with the capabilities of existing SageMaker project templates, and integrated these with infrastructure templates to deploy to production environments. This setup already contains example pipelines for training and inference, and allows NatWest users to immediately use multi-account deployment.
The multi-account setup keeps development environments secure while allowing testing in a production-like environment. This enables project teams to focus on the ML workloads. The project templates take care of infrastructure, resource provisioning, security, auditability, reproducibility, and explainability. They also allow for flexibility so that users can extend the template based on their specific use case requirements.
Solution overview
To get started as a use case team at NatWest, the following steps are required based on the templates built by NatWest and provided via AWS Service Catalog:
- The project owner provisions new AWS accounts, and the operations team sets up the MLOps prerequisite infrastructure to these new accounts.
- The project owner creates an Amazon SageMaker Studio data science environment using AWS Service Catalog.
- The data scientist lead starts a new project and creates SageMaker Studio users via the templates provided in AWS Service Catalog.
- The project team works on the project, updating the template’s folder structure to aid their use case.
The following figure shows how we adapted the template architecture to fit our CLV use case needs. It showcases how multiple training pipelines are developed and run within a development environment. The deployed models can then be tested and productionized within pre-production and production environments.
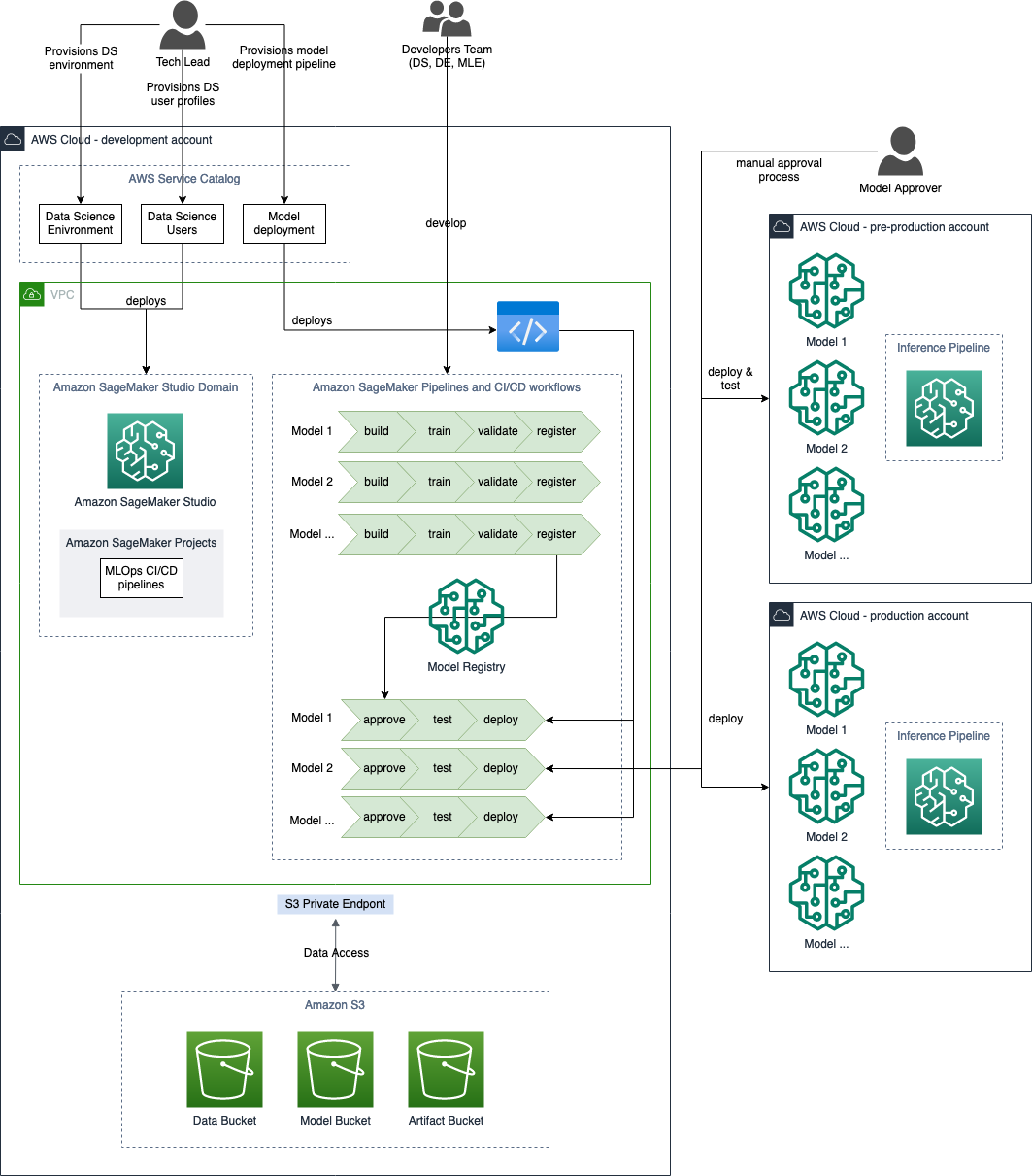
The CLV model is a sequence of different models, which includes different tree-based models and an inference setup that combines all the outputs from these. The data used in this ML workload is collected from various sources and amounts to more than half a billion rows and nearly 1,900 features. All processing, feature engineering, model training, and inference tasks on premises were done using PySpark or Python.
SageMaker pipeline templates
CLV is composed of multiple models that are built in a sequence. Each model feeds into another, so we require a dedicated training pipeline for each one. Amazon SageMaker Pipelines allows us to train and register multiple models using the SageMaker model registry. For each pipeline, existing NatWest code was refactored to fit into SageMaker Pipelines, while ensuring the logical components of processing, feature engineering, and model training stayed the same.
In addition, the code for applying the models to perform inference consecutively was refactored into one pipeline dedicated for inference. Therefore, the use case required multiple training pipelines but only one inference pipeline.
Each training pipeline results in the creation of an ML model. To deploy this model, approval from the model approver (a role defined for ML use cases in NatWest) is required. After deployment, the model is available to the SageMaker inference pipeline. The inference pipeline applies the trained models in sequence to the new data. This inference is performed in batches, and the predictions are combined to deliver the final customer lifetime value for each customer.
The template contains a standard MLOps example with the following steps:
- PySpark Processing
- Data Quality Check and Data Bias Check
- Model Training
- Condition
- Create Model
- Model Registry
- Transform
- Model Bias Check, Explainability Check, and Quality Check
This pipeline is described in more detail in Part 3: How NatWest Group built audible, reproducible, and explainable ML models with Amazon SageMaker.
The following figure shows the design of the example pipeline provided by the template.
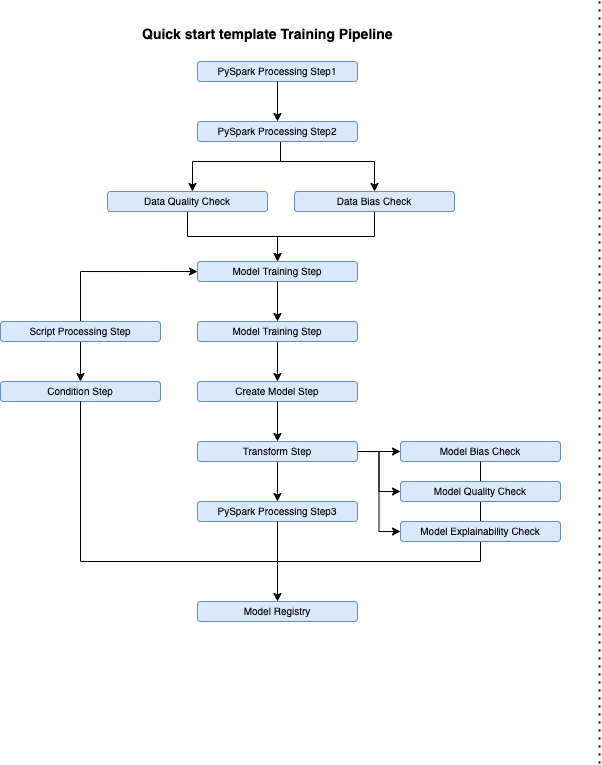
Data is preprocessed and split into train, test, and validation sets (Processing step) before training the model (Training). After the model is deployed (Create Model), it is used to create batch predictions (Transform). The predictions are then postprocessed and stored in Amazon S3 (Processing).
Data quality and data bias checks provide baseline information on the data used for training. Model bias, explainability, and quality checks use predictions on the test data to investigate the model behavior further. This information as well as model metrics from the model evaluation (Processing) are later displayed within the model registry. The model is only registered when a certain condition with regards to previous best models is met (Condition step).
Any artifacts and datasets created when a pipeline is run are saved in Amazon S3 using the buckets that are automatically created when provisioning the template.
Customizing the pipelines
We needed to customize the template to ensure the logical components of the existing codebase were migrated.
We used the LightGBM framework in building our models. The first of the models built in this use case is a simple decision tree to enforce certain feature splits during model training. Furthermore, we split the data based on a given feature. This procedure effectively resulted in training two separate decision tree models.
We can use trees to apply two kinds of predictions: value and leaf. In our case, we use value predictions on the test set to calculate custom metrics for model evaluation, and we use leaf prediction for inference.
Therefore, we needed to add specifications to the training and inference pipeline provided by the template. To account for the complexity provided by the use case model as well as to showcase the flexibility of the template, we added additional steps to the pipeline and customized the steps to apply the required code.
The following figure shows our updated template. It also demonstrates how you can have as many deployed models as you need, which you can pass to the inference pipeline.
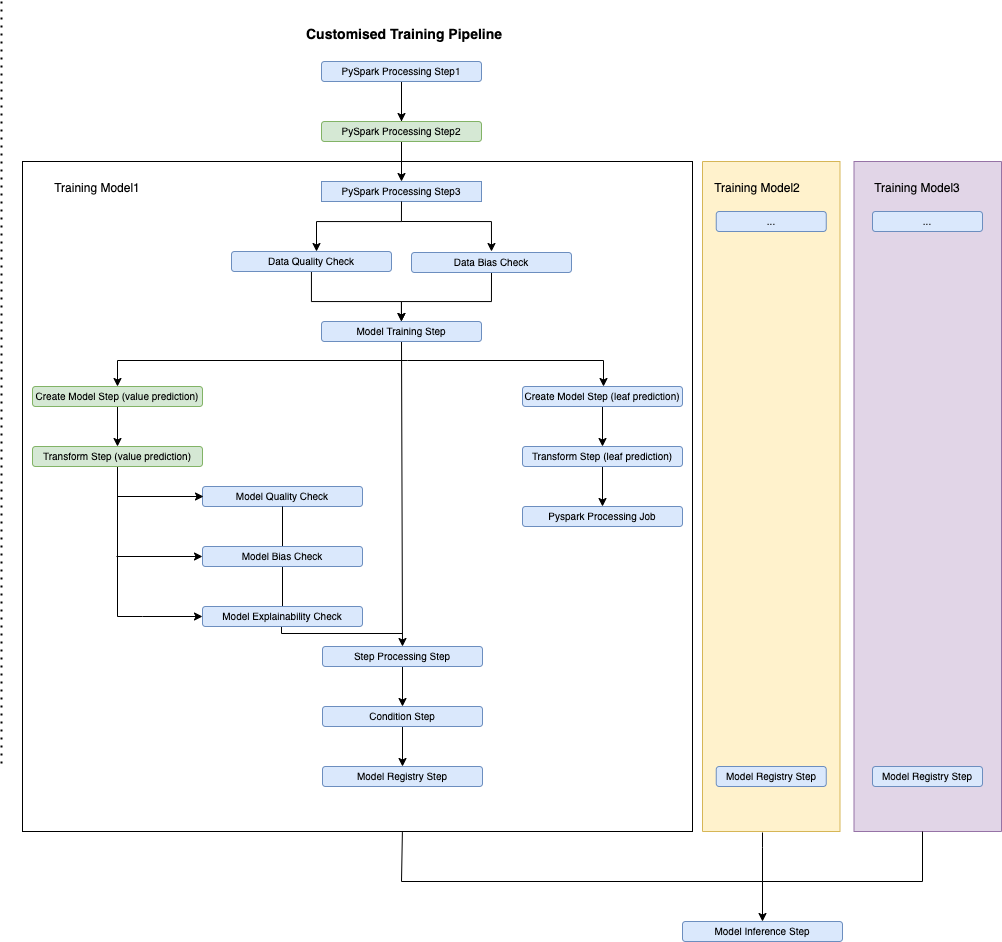
Our first model enforces business knowledge and splits the data on a given feature. For this training pipeline, we had to register two different LightGBM models for each dataset.
The steps involved in training them were almost identical. Therefore, all steps were carried out twice for each data split compared to the standard template—except the first processing steps. A second processing step is applied to cater to different models with unique datasets.
In the following sections, we discuss the customized steps in more detail.
Processing
Each processing step is provided with a processor instance, which handles the SageMaker processing tasks. This use case uses two kinds of processors to run Python code:
- PySpark processor – Each processing job with a PySpark processor uses its own set of Spark configurations to optimize the job.
- Script processor – We use the existing Python code from the use case to generate custom metrics based on the predictions and actual data provided, and format the output to be viewed later in the model registry (JSON). We use a custom image created by the template.
In each case, we can modify the instance type, instance count, and size in GB of the Amazon Elastic Block Store (Amazon EBS) volume to adjust to the training pipeline needs. In addition, we apply custom container images created by the template, and we can extend the default libraries if needed.
Model training
SageMaker training steps support managed training and inference for a variety of ML frameworks. In our case, we use the custom Scikit-learn image provided using Amazon ECR in combination with the Scikit-learn estimator to train our two LightGBM models.
The previous design for the decision tree model involved a custom class, which was complicated and had to be simplified by fitting separate decision trees to filtered slices of the data. We accomplished this by implementing two training steps with different parameter and data inputs required for each model.
Condition
Conditional steps in SageMaker Pipelines support conditional branching in the running of steps. If all the conditions in the condition list evaluate to True, the “if” steps are marked as ready to run. Otherwise, the “else” steps are marked as ready to run. For our use case, we use two condition steps (ConditionLessThan) to determine if the current custom metrics for each model (for example the mean absolute error calculated on a test set) are below a performance threshold. This way, we only register models when the model quality is acceptable.
Create model
The create model step helps make models available for inference tasks and also inherits the code to be used to create predictions. Because our use case needs value and leaf predictions for two different models, the training pipelines have four different create model steps.
Each step is given an entry point file depending whether the consecutive transform step is to predict a leaf or value on given data.
Transform
Each transform step uses a model (created by the create model step) to return predictions. In our case, we have one for each created model, resulting in a total of four transform steps. Each of these steps returns either leaf or value predictions for each of the models. The output is customized depending on the next step in the pipeline. For example, a transform step for value predictions has different output filters to create a specific input required for the following model check steps in the pipeline.
Model registry
Finally, both model branches within the training pipeline have a unique model registry step. Like the standard setup, each model registry step takes the model-specific information from all the check steps (quality, explainability, and bias) as well as custom metrics and model artefacts. Each model is registered with a unique model package group.
While applying the use case-specific changes to the example code base, pipelines ran using the cache configurations for each pipeline step to enhance the debugging experience. Caching steps are useful when developing SageMaker pipelines because it reduces cost and saves time when testing pipelines.
We can optimize the settings of each step that requires an instance type and count (and if applicable EBS volume) for on-demand instances according to the use case needs.
Benefits
The AWS-NatWest collaboration has brought innovation to the implementation of ML models via SageMaker pipelines and MLOps best practices. NatWest Group now uses a standardized and secure solution to implement and productionize ML workloads on AWS, via flexible custom templates. Additionally, the model migration detailed in this post created multiple immediate and ongoing business benefits.
Firstly, we reduced complexity via standardization:
- We can integrate custom third-party models to SageMaker in a highly modular way to build a reusable solution
- We can create non-standard pipelines using templates, and these templates are supported in a standardized MLOps production environment
We saw the following benefits in software and infrastructure engineering:
- We can customize templates based on individual use cases
- Functionally decomposing and refactoring the original model code allows us to rearchitect, remove a significant technical debt caused by legacy code, and move our pipelines to a managed on-demand execution environment
- We can use the added capabilities available via the standardized templates to upgrade and standardize model explainability, as well as check data and model quality and bias
- The NatWest project team is empowered to provision environments, implement models, and productionize models in an almost completely self-service environment
Finally, we achieved improved productivity and lower cost of maintenance:
- Reduced time-to-live for ML projects – We can now start projects with generic templates that implement code standards, unit tests, and CI/CD pipelines for production-ready use case development from the beginning of a project. The new standardization means that we can expect reduced time to onboard future use cases.
- Reduced cost for running ML workflows in the cloud – Now we can run data processing and ML workflows with a managed architecture and adapt the underlying infrastructure to use case requirements using standardized templates.
- Increased collaboration between project teams – The standardized development of models means that we’ve increased the reusability of model functions developed by individual teams. This creates an opportunity to implement continuous improvement strategies in both development and operations.
- Boundaryless delivery – This solution allows us to make our elastic on-demand infrastructure available 24/7.
- Continuous integration, delivery, and testing – Reduced deployment times between development completion and production availability lead to the following benefits:
- We can optimize the configuration of our infrastructure and software for model training and inference runtime.
- The ongoing cost of maintenance is reduced due to standardization of processes, automation, and on-demand compute. Therefore, in production, we only incur runtime costs once a month during retraining and inference.
Conclusion
With SageMaker and the assistance of AWS innovation leadership, NatWest has created an ML productivity virtuous circle. The templates, modular and reusable code, and standardization freed up the project team from existing delivery constraints. Furthermore, the MLOps automation freed up support effort to enable the team to work on other use cases and projects, or to improve existing models and processes.
This is the fourth post of a four-part series on the strategic collaboration between NatWest Group and AWS Professional Services. Check out the rest of the series for the following topics:
- Part 1 explains how NatWest Group partnered with AWS Professional Services to build a scalable, secure, and sustainable MLOps platform
- Part 2 describes how NatWest Group used AWS Service Catalog and SageMaker to deploy their compliant and self-service MLOps platform
- Part 3 provides an overview of how NatWest Group uses SageMaker services to build auditable, reproducible, and explainable ML models
About the Authors
 Pauline Ting is Data Scientist in the AWS Professional Services team. She supports customers in the financial and sports & media industries in achieving and accelerating their business outcome by developing AI/ML solutions. In her spare time, Pauline enjoys traveling, surfing, and trying new dessert places.
Pauline Ting is Data Scientist in the AWS Professional Services team. She supports customers in the financial and sports & media industries in achieving and accelerating their business outcome by developing AI/ML solutions. In her spare time, Pauline enjoys traveling, surfing, and trying new dessert places.
 Maren Suilmann is a data scientist at AWS Professional Services. She works with customers across industries unveiling the power of AI/ML to achieve their business outcomes. In her spare time, she enjoys kickboxing, hiking to great views and board game nights.
Maren Suilmann is a data scientist at AWS Professional Services. She works with customers across industries unveiling the power of AI/ML to achieve their business outcomes. In her spare time, she enjoys kickboxing, hiking to great views and board game nights.
 Craig Sim is a Senior Data Scientist at NatWest Group with a passion for data science research, particularly within graph machine learning domain, and model development process optimisation using MLOps best practices. Craig additionally has extensive experience in software engineering and technical program management within financial services. Craig has an MSc in Data Science, PGDip in Software Engineering and a BEng(Hons) in Mechanical and Electrical Engineering. Outside of work Craig is a keen golfer, having played at junior and senior county level. Craig was fortunate to be able to incorporate his golf interest, with data science, by collaborating with the PGA European Tour and World Golf Rankings for his MSc Data Science thesis. Craig also enjoys tennis and skiing and is a married father of three, now adult, children.
Craig Sim is a Senior Data Scientist at NatWest Group with a passion for data science research, particularly within graph machine learning domain, and model development process optimisation using MLOps best practices. Craig additionally has extensive experience in software engineering and technical program management within financial services. Craig has an MSc in Data Science, PGDip in Software Engineering and a BEng(Hons) in Mechanical and Electrical Engineering. Outside of work Craig is a keen golfer, having played at junior and senior county level. Craig was fortunate to be able to incorporate his golf interest, with data science, by collaborating with the PGA European Tour and World Golf Rankings for his MSc Data Science thesis. Craig also enjoys tennis and skiing and is a married father of three, now adult, children.
 Shoaib Khan is a Data Scientist at NatWest Group. He is passionate for solving business problems particularly in the domain of customer lifetime value and pricing using MLOps best practices. He is well equipped with managing a large machine learning codebase and is always excited to test new tools and packages. Loves to educate others around him as he runs a YouTube channel called convergeML. In his spare time, enjoys taking long walks and travel.
Shoaib Khan is a Data Scientist at NatWest Group. He is passionate for solving business problems particularly in the domain of customer lifetime value and pricing using MLOps best practices. He is well equipped with managing a large machine learning codebase and is always excited to test new tools and packages. Loves to educate others around him as he runs a YouTube channel called convergeML. In his spare time, enjoys taking long walks and travel.