Artificial Intelligence
Programmatically creating an IDP solution with Amazon Bedrock Data Automation
Intelligent Document Processing (IDP) transforms how organizations handle unstructured document data, enabling automatic extraction of valuable information from invoices, contracts, and reports. Today, we explore how to programmatically create an IDP solution that uses Strands SDK, Amazon Bedrock AgentCore, Amazon Bedrock Knowledge Base, and Bedrock Data Automation (BDA). This solution is provided through a Jupyter notebook that enables users to upload multi-modal business documents and extract insights using BDA as a parser to retrieve relevant chunks and augment a prompt to a foundational model (FM). In this use case, our solution performs retrieval of relevant context for public school districts from a Nation’s Report Card from the U.S Department of Education.
Amazon Bedrock Data Automation can be used as a standalone feature or as a parser when setting up a knowledge base for Retrieval-Augmented Generation (RAG) workflows. BDA can be used to generate valuable insights from unstructured, multi-modal content such as documents, images, video, and audio. With BDA, you can build automated IDP and RAG workflows, quickly and cost-effectively. In building your RAG workflow, you can use Amazon OpenSearch Service to store the vector embeddings of necessary documents. In this post, Bedrock AgentCore utilizes BDA via tools to perform multi-modal RAG for the IDP solution.
Amazon Bedrock AgentCore is a fully managed service that allows you to build and configure autonomous agents. Developers can build and deploy agents using popular frameworks and a suite of models including those from Amazon Bedrock, Anthropic, Google, and OpenAI all without managing the underlying infrastructure or writing custom code.
Strands Agents SDK is a sophisticated open-source toolkit that revolutionizes artificial intelligence (AI) agent development through a model-driven approach. Developers can create a Strands Agent with a prompt (defining agent behavior) and a list of tools. A large language model (LLM) performs the reasoning, autonomously deciding the optimal actions and when to use tools based on the context and task. This workflow supports complex systems, minimizing the code typically needed to orchestrate multi-agent collaboration. Strands SDK is used for creating the agent and defining the tools needed to perform intelligent document processing.
Follow the following prerequisites and step-by-step implementations to deploy the solution in your own AWS environment.
Prerequisites
To follow along with the example use cases, set up the following prerequisites:
- AWS credentials with appropriate permissions
- Access to Github
- Git installed locally; for instructions, see Getting Started – Installing Git
Architecture
The solution uses the following AWS services:
- Amazon S3 for document storage and upload capabilities
- Bedrock Knowledge Bases to convert objects stored in S3 into a RAG-ready workflow
- Amazon OpenSearch for vector embeddings
- Amazon Bedrock AgentCore for the IDP workflow
- Strands Agent SDK for the open source framework of defining tools to perform IDP
- Bedrock Data Automation (BDA) to extract structured insights from your documents
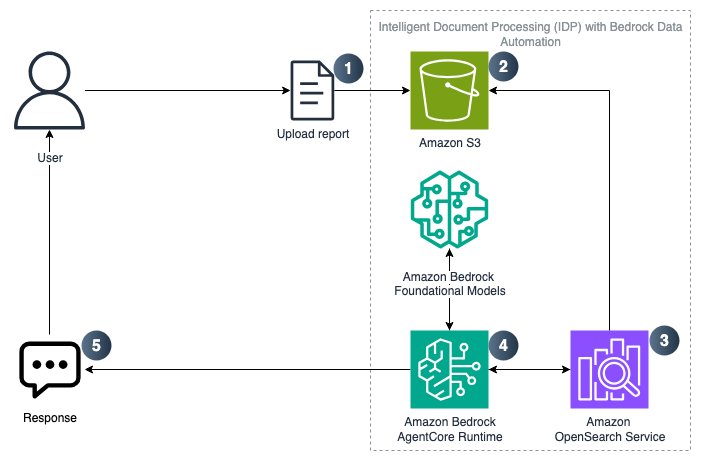
Follow these steps to get started:
- Upload relevant documents to Amazon S3
- Create Amazon Bedrock Knowledge Base and parse S3 data source using Amazon Bedrock Data Automation.
- Document chunks stored as vector embeddings in Amazon OpenSearch
- Strands Agent deployed on Amazon Bedrock AgentCore Runtime performs RAG to answer user questions.
- End user receives response
Configure the AWS CLI
Use the following command to configure the AWS Command Line Interface (AWS CLI) with the AWS credentials for your Amazon account and AWS Region. Before you begin, check AWS Bedrock Data Automation for region availability and pricing:
Clone and build the GitHub repository locally
Open Jupyter notebook called:
Bedrock Data Automation with AgentCore Notebook instructions:
This notebook demonstrates how to create an IDP solution using BDA with Amazon Bedrock AgentCore Runtime. Instead of traditional Bedrock Agents, we’ll deploy a Strands Agent through AgentCore, providing enterprise-grade capabilities with framework flexibility. More specific instructions are included in the Jupyter notebook. Here’s an overview of how you can setup Bedrock Knowledge Bases with data automation as a parser with Bedrock AgentCore.
Steps:
- Import libraries and setup AgentCore capabilities
- Create the Knowledge Base for Amazon Bedrock with BDA
- Upload the academic reports dataset to Amazon S3
- Deploy the Strands Agent using AgentCore Runtime
- Test the AgentCore-hosted agent
- Clean-up all resources
Security considerations
The implementation uses several security guardrails like:
- Secure file upload handling
- Identity and Access Management (IAM) role-based access control
- Input validation and error handling
Note: This implementation is for demonstration purposes. Additional security controls, testing, and architectural reviews are required before deploying in a production environment.
Benefits and use cases
This solution is particularly valuable for:
- Automated document processing workflows
- Intelligent document analysis on large-scale datasets
- Question-answering systems based on document content
- Multi-modal content processing
Conclusion
This solution demonstrates how to use Amazon Bedrock AgentCore’s capabilities to build intelligent document processing applications. By building Strands Agents to support Amazon Bedrock Data Automation, we can create powerful applications that understand and interact with multi-modal document content using tools. With Amazon Bedrock Data Automation, we can enhance the RAG experience for more complex data formats including visual rich documents, images, audios, and video.
Additional resources
For more information, visit Amazon Bedrock.
Service User Guides:
- Amazon Bedrock Knowledge Bases User Guide
- Amazon Bedrock AgentCore User Guide
- Strands Agents: Open Source AI Agents SDK
- Amazon Bedrock Data Automation User Guide
Relevant Samples:
- Amazon Bedrock Data Automation AWS Samples
- Amazon Bedrock AgentCore AWS Samples
- Strands Agents Samples
About the authors
 Raian Osman is a Technical Account Manager at AWS and works closely with Education technology customers based out of North America. He has been with AWS for over 3 years and began his journey working as a Solutions Architect. Raian works closely with organizations to optimize and secure workloads on AWS, while exploring innovative use cases for generative AI.
Raian Osman is a Technical Account Manager at AWS and works closely with Education technology customers based out of North America. He has been with AWS for over 3 years and began his journey working as a Solutions Architect. Raian works closely with organizations to optimize and secure workloads on AWS, while exploring innovative use cases for generative AI.
 Andy Orlosky is a Strategic Pursuit Solutions Architect at Amazon Web Services (AWS) based out of Austin, Texas. He has been with AWS for about 2 years but has worked closely with Education customers across public sector. As a leader in the AI/ML Technical Field Community, Andy continues to dive deep with his customers to design and scale generative AI solutions. He holds 7 AWS certifications and enjoys spending time with his family, playing sports with friends, and cheering for his favorite sports teams in his free time.
Andy Orlosky is a Strategic Pursuit Solutions Architect at Amazon Web Services (AWS) based out of Austin, Texas. He has been with AWS for about 2 years but has worked closely with Education customers across public sector. As a leader in the AI/ML Technical Field Community, Andy continues to dive deep with his customers to design and scale generative AI solutions. He holds 7 AWS certifications and enjoys spending time with his family, playing sports with friends, and cheering for his favorite sports teams in his free time.
 Spencer Harrison is a partner solutions architect at Amazon Web Services (AWS), where he helps public sector organizations use cloud technology to focus on business outcomes. He is passionate about using technology to improve processes and workflows. Spencer’s interests outside of work include reading, pickleball, and personal finance.
Spencer Harrison is a partner solutions architect at Amazon Web Services (AWS), where he helps public sector organizations use cloud technology to focus on business outcomes. He is passionate about using technology to improve processes and workflows. Spencer’s interests outside of work include reading, pickleball, and personal finance.