Artificial Intelligence
Scheduling Jupyter notebooks on SageMaker ephemeral instances
| May 2023: The functionality described in this blog post, is now natively available in SageMaker Studio, and can be installed as an extension into any Jupyter environment. For more information refer to: |
It’s 5 PM on a Friday. You’ve spent all afternoon coding out a complex, sophisticated feature engineering strategy. It just started working on your Amazon SageMaker Studio t3.medium notebook, and all you want to do is plug this onto a massive instance, scale it out over the rest of your dataset, and go home. You could upgrade your notebook instance, but the job would stop as soon as you close your laptop. Why not schedule the job from your notebook directly?
Amazon SageMaker provides a fully-managed solution for building, training, and deploying machine learning (ML) models. In this post, we demonstrate using Amazon SageMaker Processing Jobs to execute Jupyter notebooks with the open-source project Papermill. The combination of Amazon SageMaker with Amazon CloudWatch, AWS Lambda, and the entire AWS stack have always provided the modular backbone you need to scale up jobs, like feature engineering, both on the fly and on a schedule. We’re happy to provide a do-it-yourself toolkit to simplify this process, using AWS CloudFormation to set up permissions, Lambda to launch the job, and Amazon Elastic Container Registry (Amazon ECR) to create a customized execution environment. It includes a library and CLI to initiate notebook execution from any AWS client and a Jupyter plugin for a seamless user experience.
As of this writing, you can write code in a Jupyter notebook and run it on an Amazon SageMaker ephemeral instance with the click of a button, either immediately or on a schedule. With the tools provided here, you can do this from anywhere: at a shell prompt, in JupyterLab on Amazon SageMaker, in another JupyterLab environment you have, or automated in a program you’ve written. We’ve written sample code that simplifies setup by using AWS CloudFormation to handle the heavy lifting and provides convenience tools to run and monitor executions.
For more information about executing notebooks, see the GitHub repo. All the source code is available in aws-samples on GitHub. Read on to learn all about how to use scheduled notebook execution.
When to use this solution
This toolkit is especially useful for running nightly reports. For example, you may want to analyze all the training jobs your data science team ran that day, run a cost/benefit analysis, and generate a report about the business value your models are going to bring after you deploy them into production. That would be a perfect fit for a scheduled notebook—all the graphs, tables, and charts are generated by your code, the same as if you stepped through the notebook yourself, except now they are handled automatically, in addition to persisting in Amazon Simple Storage Service (Amazon S3). You can start your day with the latest notebook, executed overnight, to move your analysis forward.
Or, imagine that you want to scale up a feature engineering step. You’ve already perfected the for-loop to knock out all your Pandas transformations, and all you need is time and compute to run this on the full 20 GB of data. No problem—just drop your notebook into the toolkit, run a job, close your laptop, and you’re done. Your code continues to run on the scheduled instance, regardless of whether or not you’re actively using Jupyter at the moment.
Perhaps you’re on a data science team that still trains models on local laptops or Amazon SageMaker notebooks, and haven’t yet adopted the Amazon SageMaker ephemeral instances for training jobs. With this toolkit, you can easily use the advanced compute options only for the time you’re training a model. You can spin up a p3.xlarge only for the hour your model trains but use your Studio environment all day on the affordable t3.medium. You can easily connect these resources to the Experiments SDK with a few lines of code. Although it’s still fully supported to run Amazon SageMaker notebooks and Amazon SageMaker Studio on p3 instances, developing a habit of using the largest instances only for short periods is a net cost-savings exercise.
You may have an S3 bucket full of objects and need to run a full notebook on each object. These could be dates of phone call records in your call center or Tweet-streams from particular users in your social network. You can easily write a for-loop over those objects by using this toolkit, which schedules a job for each file, runs it on its dedicated instance, and stores the completed notebook in Amazon S3. These could even be model artifacts loaded in from your preferred training environment—package up your inference code in a notebook and use the toolkit to easily deploy them!
Finally, customers tell us that reporting on the performance of their models is a key asset for their stakeholders. With this toolkit, you can implement a human-in-the-loop solution that analyzes feature importance, produces ROC curves, and estimates how your model will perform on the tricky edge cases that are crucial to your final product. You can build a model profiler that all the data scientists on your team can easily access. You can trigger this model profiler to run after every training job is complete, closing the loop on the value of your analysis to your stakeholders.
Three Ways to Execute Notebooks on a Schedule in SageMaker
To execute a notebook in Amazon SageMaker, you use a Lambda function that sets up and runs an Amazon SageMaker Processing job. The function can be invoked directly by the user or added as a target of an Amazon EventBridge rule to run on a schedule or in response to an event. The notebook to run is stored as an Amazon S3 object so it’s available to run even if you’re not online when the execution happens. The following diagram illustrates this architecture.
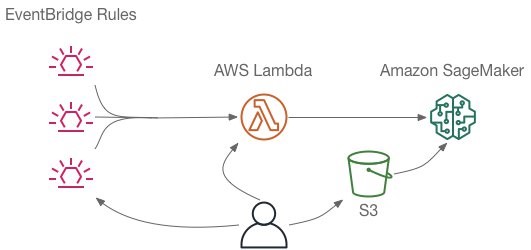
We outline three different ways to install and use this capability that let you work with notebooks and schedules just the way you want.
Using the AWS APIs or CLI directly
You can use the AWS APIs directly to execute and schedule notebooks. To make the process easier, we have provided a CloudFormation template to set up the Lambda function you need and some AWS Identity and Access Management (IAM) roles and policies that you use when running notebooks. We also provided scripts for building and customizing the Docker container images that Amazon SageMaker Processing Jobs uses when running the notebooks.
After you instantiate the CloudFormation template and create a container image, you can run a notebook like this with the following code:
To create a schedule, enter the following code, replacing the Region and account number in the arn, as well as the input_path to your S3 bucket.
With this approach, you manage moving the notebook to Amazon S3, monitoring Amazon SageMaker Processing Jobs, and retrieving the output notebook from Amazon S3.
This is a great solution when you’re a knowledgeable AWS user who wants to craft a solution without taking on extra dependencies. You can even modify the Lambda function we’ve written or the Papermill execution container to meet your exact needs.
For more information about scheduling notebooks with the AWS APIs, see the full setup instructions on the GitHub repo.
Making things easier with a convenience package
To make it easier to schedule notebooks (especially if you aren’t an AWS expert), we’ve created a convenience package that wraps the AWS tools in a CLI and Python library that give you a more natural interface to running and scheduling notebooks. This package lets you build customized execution environments without Docker, via AWS CodeBuild instead, and manages the Amazon S3 interactions and job monitoring for you.
After you run the setup, execute the notebook with the following code:
Schedule a notebook with the following code:
The convenience package also contains tools to monitor jobs and view schedules. See the following code:
For more information about the convenience package, see the GitHub repo.
Executing notebooks directly from JupyterLab with a GUI
For those who prefer an interactive experience, the convenience package includes a JupyterLab extension that you can enable for JupyterLab running locally, in Amazon SageMaker Studio, or on an Amazon SageMaker notebook instance.

After you set up the Jupyter extension for Amazon SageMaker Studio users, you see the new notebook execution sidebar (the rocket ship icon). The sidebar lets you execute or schedule the notebook you’re viewing . You can use the notebook-runner container that was created by the default setup or any other container you built. Enter the ARN for the execution role these jobs utilize and your instance preference, and you’re ready to go!
After you choose Run Now, the Lambda function picks up your notebook and runs it on an Amazon SageMaker Processing job. You can view the status of that job by choosing Runs. See the following screenshot.

When the job is complete, the finished notebook is stored in Amazon S3. Remember, this means your previous runs will persist, so you can easily revert back to them.
Finally, import the output notebook by choosing View Output and Import Notebook. If you don’t import the notebook, it’s never copied to your local directory. This is great when you want to see what happened, but don’t want to clutter things up with lots of extra notebooks.

For instructions on setting up the JupyterLab extension and using the GUI to run and monitor your notebooks, see the GitHub repo.
Summary
This post discussed how you can combine the modular capabilities of Amazon SageMaker and the AWS cloud to give data scientists and ML engineers the seamless experience of running notebooks on ephemeral instances. We are releasing an open-source toolkit to simplify this process, including a CLI, convenience package, and Jupyter widget. We discussed a variety of use cases for this, from running nightly reports to scaling up feature engineering to profiling models on the latest datasets. We shared examples from the various ways of running the toolkit. Feel free to walk through the Quick Start on GitHub and step through even more examples on the GitHub repo.
Author Bios
 Emily Webber is a machine learning specialist SA at AWS, who alternates between data scientist, machine learning architect, and research scientist based on the day of the week. She lives in Chicago, and you can find her on YouTube, LinkedIn, GitHub, or Twitch. When not helping customers and attempting to invent the next generation of machine learning experiences, she enjoys running along beautiful Lake Shore Drive, escaping into her Kindle, and exploring the road less traveled.
Emily Webber is a machine learning specialist SA at AWS, who alternates between data scientist, machine learning architect, and research scientist based on the day of the week. She lives in Chicago, and you can find her on YouTube, LinkedIn, GitHub, or Twitch. When not helping customers and attempting to invent the next generation of machine learning experiences, she enjoys running along beautiful Lake Shore Drive, escaping into her Kindle, and exploring the road less traveled.
 Tom Faulhaber is a Principal Engineer on the Amazon SageMaker team. Lately, he has been focusing on unlocking all the potential uses of the richness of Jupyter notebooks and how they can add to the data scientist’s toolbox in non-traditional ways. In his spare time, Tom is usually found biking and hiking to discover all the wild spaces around Seattle with his kids.
Tom Faulhaber is a Principal Engineer on the Amazon SageMaker team. Lately, he has been focusing on unlocking all the potential uses of the richness of Jupyter notebooks and how they can add to the data scientist’s toolbox in non-traditional ways. In his spare time, Tom is usually found biking and hiking to discover all the wild spaces around Seattle with his kids.