Artificial Intelligence
Serving deep learning at Curalate with Apache MXNet, AWS Lambda, and Amazon Elastic Inference
Note: Amazon Elastic Inference is no longer available. Please see Amazon SageMaker for similar capabilities.
This is a guest blog post by Jesse Brizzi, a computer vision research engineer at Curalate.
At Curalate, we’re always coming up with new ways to use deep learning and computer vision to find and leverage user-generated content (UGC) and activate influencers. Some of these applications, like Intelligent Product Tagging, require deep learning models to process images as quickly as possible. Other deep learning models must ingest hundreds of millions of images per month to generate useful signals and serve content to clients.
As a startup, Curalate had to find a way to do all of this at scale in a high-performance, cost-effective manner. Over the years, we’ve used every type of cloud infrastructure that AWS has to offer in order to host our deep learning models. In the process, we learned a lot about serving deep learning models in production and at scale.
In this post, I discuss the important factors that Curalate considered when designing our deep learning infrastructure, how API/service types prioritize these factors, and, most importantly, how various AWS products meet these requirements in the end.
Problem overview
Let’s say you have a trained MXNet model that you want to serve in your AWS Cloud infrastructure. How do you build it, and what solutions and architecture do you choose?
At Curalate, we’ve been working on an answer to this question for years. As a startup, we’ve always had to adapt quickly and try new options as they become available. We also roll our own code when building our deep learning services. Doing so allows for greater control and lets us work in our programming language of choice.
In this post, I focus purely on the hardware options for deep learning services. If you’re also looking for model-serving solutions, there are options available from Amazon SageMaker.
The following are some questions we ask ourselves:
- What type of service/API are we designing?
- Is it user-facing and real-time, or is it an offline data pipeline processing service?
- How does each AWS hardware serving option differ?
- Performance characteristics
- How fast can you run inputs through the model?
- Ease of development
- How difficult is it to engineer and code the service logic?
- Stability
- How is the hardware going to affect service stability?
- Cost
- How cost effective is one hardware option over the others?
- Performance characteristics
GPU solutions
GPUs probably seem like the obvious solution. Developments in the field of machine learning are closely intertwined with GPU processing power. GPUs are the reason that true “deep” learning is possible in the first place.
GPUs have played a role in every one of our deep learning services. They are fast enough to power our user-facing apps and keep up with our image data pipeline.
AWS offers many GPU solutions in Amazon EC2, ranging from cost-effective g3s.xlarge instances to powerful (and expensive) p3dn.24xlarge instances.
| Instance type | CPU memory | CPU cores | GPUs | GPU type | GPU memory | On-Demand cost |
| g3s.xlarge | 30.5 GiB | 4 vCPUs | 1 | Tesla M60 | 8 GiB | $0.750 hourly |
| p2.xlarge | 61.0 GiB | 4 vCPUs | 1 | Tesla K80 | 12 GiB | $0.900 hourly |
| g3.4xlarge | 122.0 GiB | 16 vCPUs | 1 | Tesla M60 | 8 GiB | $1.140 hourly |
| g3.8xlarge | 244.0 GiB | 32 vCPUs | 2 | Tesla M60 | 16 GiB | $2.280 hourly |
| p3.2xlarge | 61.0 GiB | 8 vCPUs | 1 | Tesla V100 | 16 GiB | $3.060 hourly |
| g3.16xlarge | 488.0 GiB | 64 vCPUs | 4 | Tesla M60 | 32 GiB | $4.560 hourly |
| p2.8xlarge | 488.0 GiB | 32 vCPUs | 8 | Tesla K80 | 96 GiB | $7.200 hourly |
| p3.8xlarge | 244.0 GiB | 32 vCPUs | 4 | Tesla V100 | 64 GiB | $12.240 hourly |
| p2.16xlarge | 768.0 GiB | 64 vCPUs | 16 | Tesla K80 | 192 GiB | $14.400 hourly |
| p3.16xlarge | 488.0 GiB | 64 vCPUs | 8 | Tesla V100 | 128 GiB | $24.480 hourly |
| p3dn.24xlarge | 768.0 GiB | 96 vCPUs | 8 | Tesla V100 | 256 GiB | $31.212 hourly |
As of August 2019*
There are plenty of GPU, CPU, and memory resource options from which to choose. Out of all of the AWS hardware options, GPUs offer the fastest model runtimes per input and provide memory options sizeable enough to support your large models and batch sizes. For instance, memory can be as large as 32 GB for the instances that use Nvidia V100 GPUs.
However, GPUs are also the most expensive option. Even the cheapest GPU could cost you $547 per month in On-Demand Instance costs. When you start scaling up your service, these costs add up. Even the smallest GPU instances pack a lot of compute resources into a single unit, and they are more expensive as a result. There are no micro, medium, or even large EC2 GPU options.
Consequently, it can be inefficient to scale your resources. Adding another GPU instance can cause you to go from being under-provisioned and falling slightly behind to massively over-provisioned, which is a waste of resources. It’s also an inefficient way to provide redundancy for your services. Running a minimum of two instances brings your base costs to over $1,000. For most service loads, you likely will not even come close to fully using those two instances.
In addition to runtime costs, the development costs and challenges are what you would expect from creating a deep learning–based service. If you are rolling your own code and not using a model server like MMS, you have to manage access to your GPU from all the incoming parallel requests. This can be a bit challenging, as you can only fit a few models on your GPU at one time.
Even then, running inputs simultaneously through multiple models can lead to suboptimal performance and cause stability issues. In fact, at Curalate, we only send one request at a time to any of the models on the GPU.
In addition, we use computer vision models. Consequently, we have to handle the downloading and preprocessing of input images. When you have hundreds of images coming in per second, it’s important to build memory and resource management considerations into your code to prevent your services from being overwhelmed.
Setting up AWS with GPUs is fairly trivial if you have previous experience setting up Elastic Load Balancing, Auto Scaling groups, or EC2 instances for other applications. The only difference is that you must ensure that your AMIs have the necessary Nvidia CUDA and cuDNN libraries installed for the code and MXNet to use. Beyond that consideration, you implement it on AWS just like any other cloud service or API.
Amazon Elastic Inference accelerator solution
What are these new Elastic Inference accelerators? They’re low-cost, GPU-powered accelerators that you can attach to an EC2 or Amazon SageMaker instance. AWS offers Elastic Inference accelerators from 4 GB all the way down to 1 GB of GPU memory. This is a fantastic development, as it solves the inefficiencies and scaling problems associated with using dedicated GPU instances.
| Accelerator type | FP32 throughput (TFLOPS) | FP16 throughput (TFLOPS) | Memory (GB) |
| eia1.medium | 1 | 8 | 1 |
| eia1.large | 2 | 16 | 2 |
| eia1.xlarge | 4 | 32 | 4 |
You can precisely pair the optimal Elastic Inference accelerator for your application with the optimal EC2 instance for the compute resources that it needs. Such pairing allows you to, for example, use 16 CPU cores to host a large service that uses a small model in a 1 GB GPU. This also means that you can scale with finer granularity and avoid drastically over-provisioning your services. For scaling to your needs, a cluster of c5.large + eia.medium instances is much more efficient than a cluster of g3s.xlarge instances.
Using the Elastic Inference accelerators with MXNet currently requires the use of a closed fork of the Python API or Scala API published by AWS and MXNet. These forks and other API languages will eventually merge with the open-source master branch of MXNet. You can load your MXNet model into the context of Elastic Inference accelerators, as with the GPU or CPU contexts. Consequently, the development experience is similar to developing deep learning services on a GPU-equipped EC2 instance. The same engineering challenges are there, and the overall code base and infrastructure should be nearly identical to the GPU-equipped options.
Thanks to the new Elastic Inference accelerators and access to an MXNet EIA fork in our API language of choice, Curalate has been able to bring our GPU usage down to zero. We moved all of our services that previously used EC2 GPU instances to various combinations of eia.medium/large accelerators and c5.large/xlarge EC2 instances. We made this change based on specific service needs, requiring few to no code changes.
Setting up the infrastructure was a little more difficult, given that the Elastic Inference accelerators are fairly new and did not interact well with some of our cloud management tooling. However, if you know your way around the AWS Management Console, the cost savings are worth dealing with any challenges you may encounter during setup. After switching over, we’re saving between 35% and 65% on hosting costs, depending on the service.
The overall model and service processing latency has been just as fast as, or faster than, the previous EC2 GPU instances that we were using. Having access to the newer-generation C5 EC2 instances have made for significant improvements in network and CPU performance. The Elastic Inference accelerators themselves are just like any other AWS service that you can connect to over the network.
Compared to local GPU hardware, using Elastic Inference accelerators can lead to possible issues and potentially introduce more overhead. That said, the increased stability has proven highly beneficial and has been equal to what we would expect out of any other AWS service.
AWS Lambda solution
You might think that because a single AWS Lambda function lacks a GPU and has tiny compute resources, it would be a poor choice for deep learning. While it’s true that Lambda functions are the slowest option available for running deep learning models on AWS, they offer many other advantages when working with serverless infrastructure.
When you break down the logic of your deep learning service into a single Lambda function for a single request, things become much simpler—even performant. You can forget all about the resource handling needed for the parallel requests coming into your model. Instead, a single Lambda function loads its own instance of your deep learning models, prepares the single input that comes in, then computes the output of the model and returns the result.
As long as traffic is high enough, the Lambda instance is kept alive to reuse for the next request. Keeping the instance alive stores the model in memory, meaning that the next request only has to prep and compute the new input. Doing so greatly simplifies the procedure and makes it much easier to deploy a deep learning service on Lambda.
In terms of performance, each Lambda function is only working with up to 3 GB of memory and one or two vCPUs. Per-input latency is slower than a GPU but is largely acceptable for most applications.
However, the performance advantage that Lambda offers lies in its ability to automatically scale widely with the number of concurrent calls you can make to your Lambda functions. Each request always takes roughly the same amount of time. If you can make 50, 100, or even 500 parallel requests (all returning in the same amount of time), your overall throughput can easily surpass GPU instances with even the largest input batches.
These scaling characteristics also come with efficient cost-saving characteristics and stability. Lambda is serverless, so you only pay for the compute time and resources that you actually use. You’re never forced to waste money on unused resources, and you can accurately estimate your data pipeline processing costs based on the number of expected service requests.
In terms of stability, the parallel instances that run your functions are cycled often as they scale up and down. This means that there’s less of a chance that your service could be taken down by something like native library instability or a memory leak. If one of your Lambda function instances does go down, you have plenty of others still running that can handle the load.
Because of all of these advantages, we’ve been using Lambda to host a number of our deep learning models. It’s a great fit for some of our lower volume, data-pipeline services, and it’s perfect for trying out new beta applications with new models. The cost of developing a new service is low, and the cost of hosting a model is next to nothing because of the lower service traffic requirements present in beta.
Cost threshold
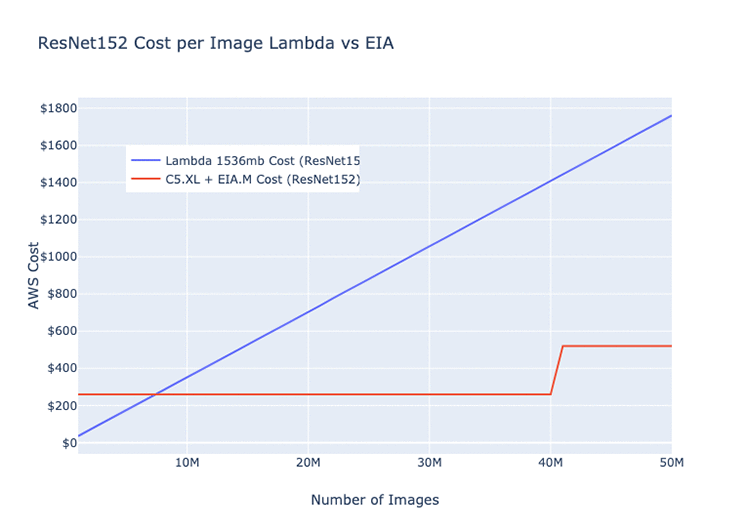
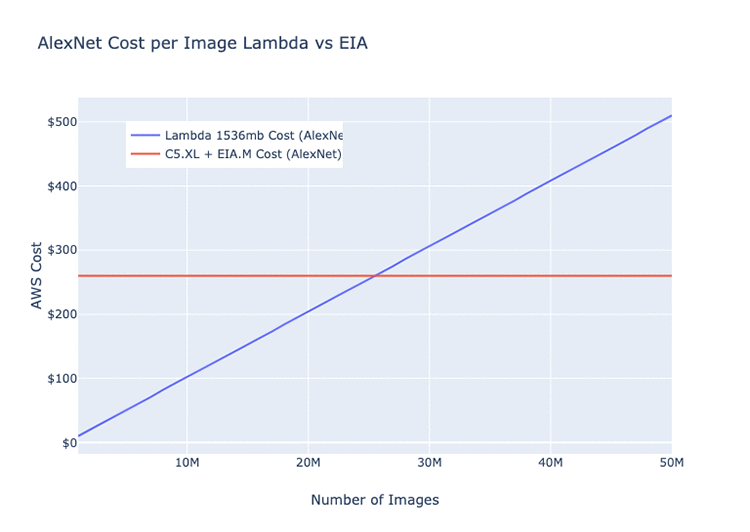
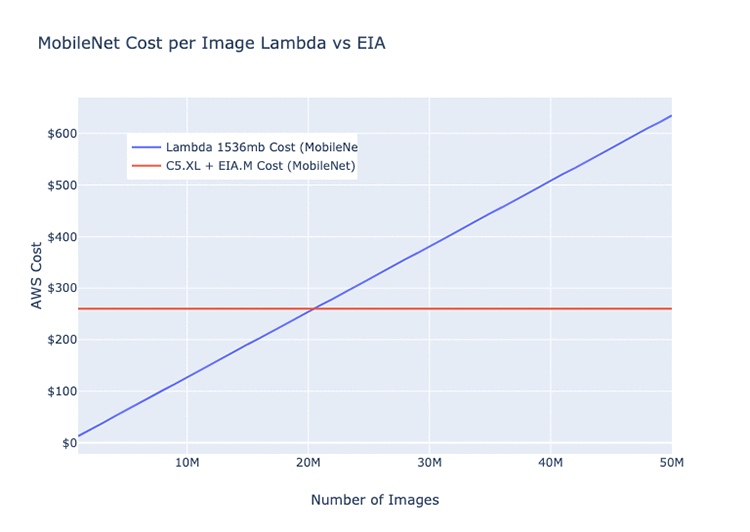
The following graphs display our nominal performance of images through a single Elastic Inference accelerator-hosted model per month. They include the average runtime and cost of the same model on Lambda (ResNet 152, AlexNet, and MobileNet architectures).
The graphs should give you a rough idea of the circumstances during which it’s more efficient to run on Lambda than the Elastic Inference accelerators, and vice versa. These values are all dependent on your network architecture.
Given the differences in model depth and the overall number of parameters, certain model architectures can run more efficiently on GPUs or Lambda than others. The following three examples are all basic image classification models. The monthly cost estimate for the EC2 instance is for a c5.xlarge + eia.medium = $220.82.
As an example, for the ResNet152 model, the crossover point is around 7,500,000 images per month, after which the C5 + EIA option becomes more cost-effective. We estimate that after you pass the bump at 40,000,000, you would require a second instance to meet demand and handle traffic spikes. If the load was perfectly distributed across the month, that rate would come out to about 15 images per second. Assuming you are trying to run as cheaply as possible, one instance could easily handle this with plenty of headroom, but real-world service traffic is rarely uniform.
Realistically, for this type of load, our C5 + Elastic Inference accelerator clusters automatically scale anywhere from 2 to 6 instances. That’s dependent on the current load on our processing streams for any single model—the largest of which processes ~250,000,000 images per month.
Conclusion
To power all of our deep learning applications and services on AWS, Curalate uses a combination of AWS Lambda and Elastic Inference accelerators.
In our production environment, if the app or service is user-facing and requires low latency, we power it with an Elastic Inference accelerator-equipped EC2 instance. We have seen hosting cost savings of 35-65% compared to GPU instances, depending on the service using the accelerators.
If we’re looking to do offline data-pipeline processing, we first deploy our models to Lambda functions. It’s best to do so while traffic is below a certain threshold or while we’re trying something new. After that specific data pipeline reaches a certain level, we find that it’s more cost-effective to move the model back onto a cluster of Elastic Inference accelerator-equipped EC2 instances. These clusters smoothly and efficiently handle streams of hundreds of millions of deep learning model requests per month.
About the author
 Jesse Brizzi is a Computer Vision Research Engineer at Curalate where he focuses on solving problems with machine learning and serving them at scale. In his spare time, he likes powerlifting, gaming, transportation memes, and eating at international McDonald’s. Follow his work at www.jessebrizzi.com.
Jesse Brizzi is a Computer Vision Research Engineer at Curalate where he focuses on solving problems with machine learning and serving them at scale. In his spare time, he likes powerlifting, gaming, transportation memes, and eating at international McDonald’s. Follow his work at www.jessebrizzi.com.