Artificial Intelligence
Swann provides Generative AI to millions of IoT Devices using Amazon Bedrock
If you’re managing Internet of Things (IoT) devices at scale, alert fatigue is probably undermining your system’s effectiveness. This post shows you how to implement intelligent notification filtering using Amazon Bedrock and its gen-AI capabilities. You’ll learn model selection strategies, cost optimization techniques, and architectural patterns for deploying gen-AI at IoT scale, based on Swann Communications deployment across millions of devices.
Smart home security customers now expect systems that can tell the difference between a delivery person and a potential intruder—not just detect motion. Customers were being overwhelmed with lot of daily notifications or false positives, with a lot of alerts being triggered by events that were irrelevant to the customers, such as passing cars, pets moving around, and so on. Users became frustrated with constant false alerts and started ignoring notifications entirely, including real security threats.
As a pioneer in do-it-yourself (DIY) security solutions, Swann Communications has built a global network of more than 11.74 million connected devices, serving homeowners and businesses across multiple continents. Swann partnered with Amazon Web Services (AWS) to develop a multi-model generative AI notification system to evolve their notification system from a basic, reactive alert mechanism into an intelligent, context-aware security assistant.
Business challenges driving the solution
Before implementing the new solution, Swann faced several critical challenges that required a fundamentally different approach to security notifications.
Swann’s previous system had basic detection that could only identify human or pet events without contextual awareness—treating a delivery person the same as a potential intruder—while offering no customization options for users to define what constituted a meaningful alert for their unique security needs. These technical constraints, compounded by scalability challenges in managing notifications cost-efficiently across tens of millions of devices, made it clear that incremental improvements wouldn’t suffice—Swann needed a fundamentally smarter approach.
Approximately 20 daily notifications per camera—most of them irrelevant—caused customers to miss critical security events, with many users disabling notifications within the first few months. This significantly reduced system effectiveness, demonstrating the need for intelligent filtering that delivered only meaningful alerts. Rather than managing multiple vendors and custom integrations, Swann used different AWS cloud services that work together. By using AWS integrated services, Swann’s engineering team could concentrate on creating new security features.
Why AWS and Amazon Bedrock were selected
When evaluating AI partners, Swann prioritized enterprise-grade capabilities that could reliably scale. AWS stood out for several key reasons:
Enterprise-grade AI capabilities
Swann chose AWS for its comprehensive, integrated approach to deploying generative AI at scale. Amazon Bedrock, a fully managed service, provided access to multiple foundation models through a single API, handling GPU provisioning, model deployment, and scaling automatically, so that Swann could test and compare different model families (such as Claude and Nova) without infrastructure changes while optimizing for either speed or accuracy based on each scenario, such as high-volume routine screening, threat verification requiring detailed analysis, time-sensitive alerts, and complex behavioral assessment. With approximately 275 million monthly inferences, the AWS pay-per-use pricing model, and the ability to use cost-effective models such as Nova Lite for routine analysis resulted in cost optimization. AWS services delivered low-latency inference across North America, Europe, and Asia-Pacific while providing data residency compliance and high availability for mission-essential security applications.
The AWS environment used by Swann included AWS IoT Core for device connectivity, Amazon Simple Storage Service (Amazon S3) for scalable storage and storing video feeds, and AWS Lambda to run code in response to events without managing servers, scaling from zero to thousands of executions and charging only for compute time used. Amazon Cognito is used to manage user authentication and authorization with secure sign-in, multi-factor authentication, social identity integration, and temporary AWS credentials. Amazon Simple Query Service (Amazon SQS) is used to manage message queuing, buffering requests during traffic spikes, and helping to ensure reliable processing even when thousands of cameras trigger simultaneously.
By using these capabilities to remove the effort of managing multiple vendors and custom integrations, Swann could focus on innovation rather than infrastructure. This cloud-centred integration accelerated time-to-market by 2 months while reducing operational overhead, an enabled the cost-effective deployment of sophisticated AI capabilities across millions of devices.
Scalability and performance requirements
Swann’s solution needed to handle millions of concurrent devices (more than 11.74 million cameras generating frames 24/7), variable workload patterns with peak activity during evening hours and weekends, real-time processing to provide sub-second latency for critical security events, global distribution with consistent performance across multiple geographic regions, and cost predictability through transparent pricing that scales linearly with usage. Swann found that Amazon Bedrock and AWS services gave them the best of both worlds: a global network that could handle their massive scale, plus smart cost controls that let them pick exactly the right model for each situation.
Solution architecture overview and implementation
Swann’s dynamic notifications system uses Amazon Bedrock, strategically using four foundation models (Nova Lite, Nova Pro, Claude Haiku, and Claude Sonnet) across two key features to balance performance, cost, and accuracy. This architecture, shown in the following figure, demonstrates how AWS services can be combined to create a scalable, intelligent video analysis solution using generative AI capabilities while optimizing for both performance and cost:
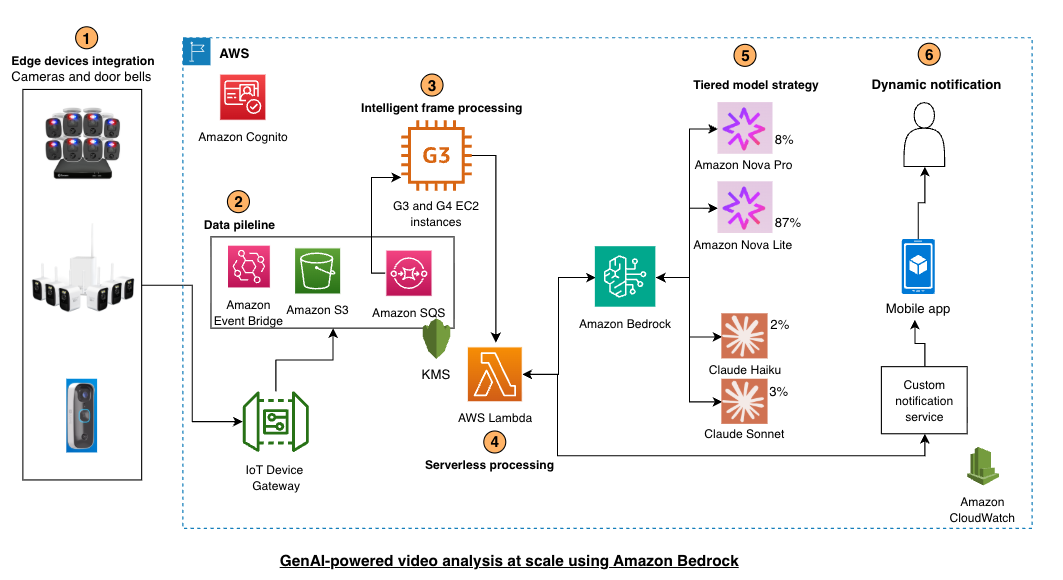
- Edge device integration: Smart cameras and doorbells connect through the AWS IoT Device Gateway, providing real-time video feeds for analysis.
- Data pipeline: Video content flows through Amazon EventBridge, Amazon S3, and Amazon SQS for reliable storage and message queuing.
- Intelligent frame processing: Amazon Elastic Compute Cloud (Amazon EC2) instances (G3 and G4 family) use computer vision libraries to segment video’s into frames and handle frame selection and filtering to optimize processing efficiency. G3 and G4 instances are GPU-powered virtual servers designed for parallel processing workloads such as video analysis and AI inference. Unlike traditional CPUs that process tasks sequentially, GPUs contain thousands of cores that can analyze multiple video frames simultaneously. This means that Swann can process frames from thousands of cameras concurrently without latency bottlenecks, providing near real-time security monitoring.
- Serverless processing: Lambda functions invoke Amazon Bedrock and implement model selection logic based on use case requirements.
- Tiered model strategy: A cost-effective approach using multiple models with varying capabilities. Amazon Nova Lite for speed and cost efficiency in routine high-volume screening, Nova Pro for balanced performance in threat verification, Claude Haiku for ultra-low latency in time-critical alerts, and Claude Sonnet for advanced reasoning in complex behavioral analysis requiring nuanced reasoning.
- Dynamic notifications: The custom notification service delivers real-time alerts to mobile applications based on detection results.
Best practices for generative AI implementation
The following best practices can help organizations optimize cost, performance, and accuracy when implementing similar generative AI solutions at scale:
- Understanding RPM and token limits: Requests per minute (RPM) limits define the number of API calls allowed per minute, requiring applications to implement queuing or retry logic to handle high-volume workloads. Tokens are the basic units AI models use to process text and images with costs calculated per thousand tokens, making concise prompts essential for reducing expenses at scale.
- Business logic optimization: Swann reduced API calls by 88% (from 17,000 to 2,000 RPM) by implementing intelligent pre-filtering (motion detection, zone-based analysis, and duplicate frame elimination) before invoking AI models.
- Prompt engineering and token optimization: Swann achieved 88% token reduction (from 150 to 18 tokens per request) through three key strategies:
- optimizing image resolution to reduce input tokens while preserving visual quality.
- Deploying a custom pre-filtering model on GPU based EC2 instances to eliminate 65% of false detections (swaying branches, passing cars) before reaching Amazon Bedrock.
- Engineering ultra-concise prompts with structured response formats that replaced verbose natural language with machine-parseable key-value pairs (for example,
threat:LOW|type:person|action:delivery). Swann’s customer surveys revealed that these optimizations not only reduced latency and cost but also improved threat detection accuracy from 89% to 95%.
- Prompt versioning, optimization, and testing: Swann versioned prompts with performance metadata (accuracy, cost, and latency) and A/B tested on 5–10% of traffic before rollout. Swann also uses Amazon Bedrock prompt optimization.
- Model selection and tiered strategy: Swann selected models based on activity type.
- Nova Lite (87% of requests): Handles fast screening of routine activity, such as passing cars, pets, and delivery personnel. Its low cost, high throughput, and sub-millisecond latency make it essential for high-volume, real-time analysis where speed and efficiency matter more than precision.
- Nova Pro (8% of requests): Escalates from Nova Lite when potential threats require verification with higher accuracy. Distinguishes delivery personnel from intruders and identifies suspicious behavior patterns.
- Claude Haiku (2% of requests): Powers the Notify Me When feature for immediate notification of user-defined criteria. Provides ultra-low latency for time-sensitive custom alerts.
- Claude Sonnet (3% of requests): Handles complex edge cases requiring sophisticated reasoning. Analyzes multi-person interactions, ambiguous scenarios, and provides nuanced behavioral assessment.
- Results: This intelligent routing achieves 95% overall accuracy while reducing costs by 99.7% compared to using Claude Sonnet for all requests from a projected $2.1 million to $6 thousand monthly. The key insight was that matching model capabilities to task complexity enables cost-effective generative AI deployment at scale, with business logic pre-filtering and tiered model selection delivering far greater savings than model choice alone.
- Model distillation strategy: Swann taught smaller, faster AI models to mimic the intelligence of larger ones—like creating a lightweight version that’s almost as smart but works much faster and costs less than large models. For new features, Swann is exploring Nova model distillation techniques. It allows knowledge transfer from larger advanced models to smaller efficient ones. It also helps optimize model performance for particular use cases without requiring extensive labelled training data.
- Implement comprehensive monitoring: Use Amazon CloudWatch to track critical performance metrics including latency percentiles—p50 (median response time), p95 (95th percentile, capturing worst-case for most users), and p99 (99th percentile, identifying outliers and system stress)—alongside token consumption, cost per inference, accuracy rates, and throttling events. These percentile metrics are crucial because average latency can mask performance issues; for example, a 200 ms average might hide that 5% of requests take more than 2 seconds, directly impacting customer experience.
Conclusion
After implementing Amazon Bedrock, Swann saw immediate improvements—customers received fewer but more relevant alerts. Alert volume dropped 25% while notification relevance increased 89%, and customer satisfaction increased by 3%. The system scales across 11.74 million devices with sub-300 ms p95 latency, demonstrating that sophisticated generative AI capabilities can be deployed cost-effectively in consumer IoT products. Dynamic notifications (shown in the following image) deliver context-aware security alerts.
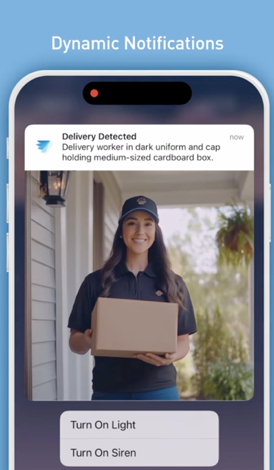
The Notify Me When feature (shown in the following video) demonstrates intelligent customization. Users define what matters to them using natural language, such as “notify me if a dog enters the backyard” or “notify me if a child is near the swimming pool,” enabling truly personalized security monitoring.
Next steps
Organizations considering generative AI at scale should start with a clear, measurable business problem and pilot with a subset of devices before full deployment, optimizing for cost from day one through intelligent business logic and tiered model selection. Invest in comprehensive monitoring to enable continuous optimization and design architecture for graceful degradation to verify reliability even during service disruptions. Focus on prompt engineering and token optimization early to help deliver performance and cost improvements. Use managed services like Amazon Bedrock to handle infrastructure complexity and build flexible architecture that supports future model improvements and evolving AI capabilities.
Explore additional resources
- Get Started with Amazon Bedrock
- Amazon Bedrock Nova Models
- Amazon Bedrock pricing
- Prompt engineering concepts
- Submit a model distillation job in Amazon Bedrock
About the authors
 Aman Sharma is an Enterprise Solutions Architect at AWS, where he works with enterprise retail and supply chain customers across ANZ. With more than 21 years of experience in consulting, architecting, and solution design, passionate about democratizing AI and ML, helping customers design data and ML strategies. Outside of work, he enjoys exploring nature and wildlife photography.
Aman Sharma is an Enterprise Solutions Architect at AWS, where he works with enterprise retail and supply chain customers across ANZ. With more than 21 years of experience in consulting, architecting, and solution design, passionate about democratizing AI and ML, helping customers design data and ML strategies. Outside of work, he enjoys exploring nature and wildlife photography.
 Surjit Reghunathan is the Chief Technology Officer at Swann Communications, where he leads technology innovation and strategic direction for the company’s global IoT security platform. With expertise in scaling connected device solutions, Surjit drives the integration of AI and machine learning capabilities across Swann’s product portfolio. Outside of work, he enjoys long motorcycle rides and playing guitar.
Surjit Reghunathan is the Chief Technology Officer at Swann Communications, where he leads technology innovation and strategic direction for the company’s global IoT security platform. With expertise in scaling connected device solutions, Surjit drives the integration of AI and machine learning capabilities across Swann’s product portfolio. Outside of work, he enjoys long motorcycle rides and playing guitar.
 Suraj Padinjarute is a Technical Account Manager at AWS, helping retail and supply chain customers maximize the value of their cloud investments. With over 20 years of IT experience in database administration, application support, and cloud transformation, he is passionate about enabling customers on their cloud journey. Outside of work, Suraj enjoys long-distance cycling and exploring the outdoors.
Suraj Padinjarute is a Technical Account Manager at AWS, helping retail and supply chain customers maximize the value of their cloud investments. With over 20 years of IT experience in database administration, application support, and cloud transformation, he is passionate about enabling customers on their cloud journey. Outside of work, Suraj enjoys long-distance cycling and exploring the outdoors.