Artificial Intelligence
Use Amazon SageMaker Canvas to build machine learning models using Parquet data from Amazon Athena and AWS Lake Formation
Data is the foundation for machine learning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. This means that business analysts who want to extract insights from the large volumes of data in their data warehouse must frequently use data stored in Parquet.
To simplify access to Parquet files, Amazon SageMaker Canvas has added data import capabilities from over 40 data sources, including Amazon Athena, which supports Apache Parquet.
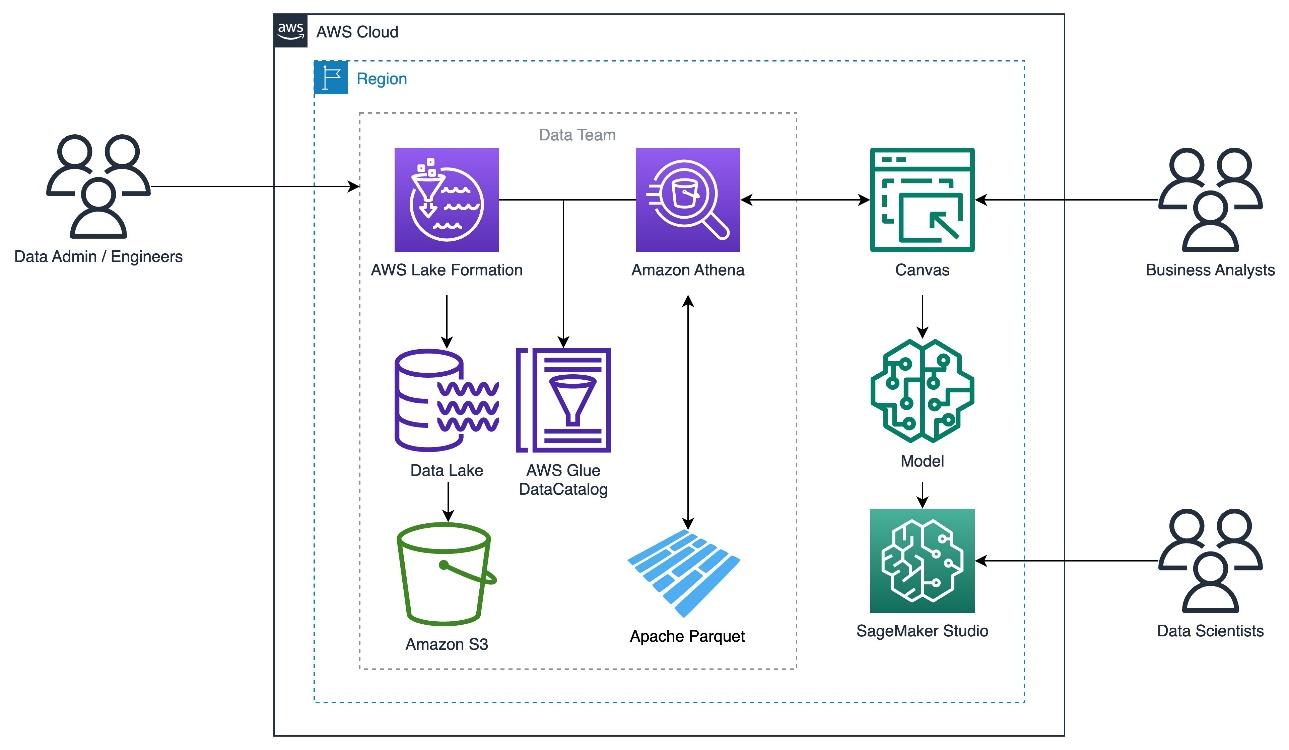
Canvas provides connectors to AWS data sources such as Amazon Simple Storage Service (Amazon S3), Athena, and Amazon Redshift. In this post, we describe how to query Parquet files with Athena using AWS Lake Formation and use the output Canvas to train a model.
Solution overview
Athena is a serverless, interactive analytics service built on open-source frameworks, supporting open table and file formats. Many teams are turning to Athena to enable interactive querying and analyze their data in the respective data stores without creating multiple data copies.
Athena allows applications to use standard SQL to query massive amounts of data on an S3 data lake. Athena supports various data formats, including:
- CSV
- TSV
- JSON
- text files
- Open-source columnar formats, such as ORC and Parquet
- Compressed data in Snappy, Zlib, LZO, and GZIP formats
Parquet files organize the data into columns and use efficient data compression and encoding schemes for fast data storage and retrieval. You can reduce the import time in Canvas by using Parquet files for bulk data imports and with specific columns.
Lake Formation is an integrated data lake service that makes it easy for you to ingest, clean, catalog, transform, and secure your data and make it available for analysis and ML. Lake Formation automatically manages access to the registered data in Amazon S3 through services including AWS Glue, Athena, Amazon Redshift, Amazon QuickSight, and Amazon EMR using Zeppelin notebooks with Apache Spark to ensure compliance with your defined policies.
In this post, we show you how to import Parquet data to Canvas from Athena, where Lake Formation enables data governance.
To illustrate, we use the operations data of a consumer electronics business. We create a model to estimate the demand for electronic products using their historical time series data.
This solution is illustrated in three steps:
- Set up the Lake Formation.
- Grant Lake Formation access permissions to Canvas.
- Import the Parquet data to Canvas using Athena.
- Use the imported Parquet data to build ML models with Canvas.
The following diagram illustrates the solution architecture.
Set up the Lake Formation database
The steps listed here form a one-time setup to show you the data lake hosting the Parquet data, which can be consumed by your analysts to gain insights using Canvas. Either cloud engineers or administrators can best perform these prerequisites. Analysts can go directly to Canvas and import the data from Athena.
The data used in this post consist of two datasets sourced from Amazon S3. These datasets have been generated synthetically for this post.
- Consumer Electronics Target Time Series (TTS) – The historical data of the quantity to forecast is called the Target Time Series (TTS). In this case, it’s the demand for an item.
- Consumer Electronics Related Time Series (RTS) – Other historical data that is known at exactly the same time as every sales transaction is called the Related Time Series (RTS). In our use case, it’s the price of an item. An RTS dataset includes time series data that isn’t included in a TTS dataset and might improve the accuracy of your predictor.
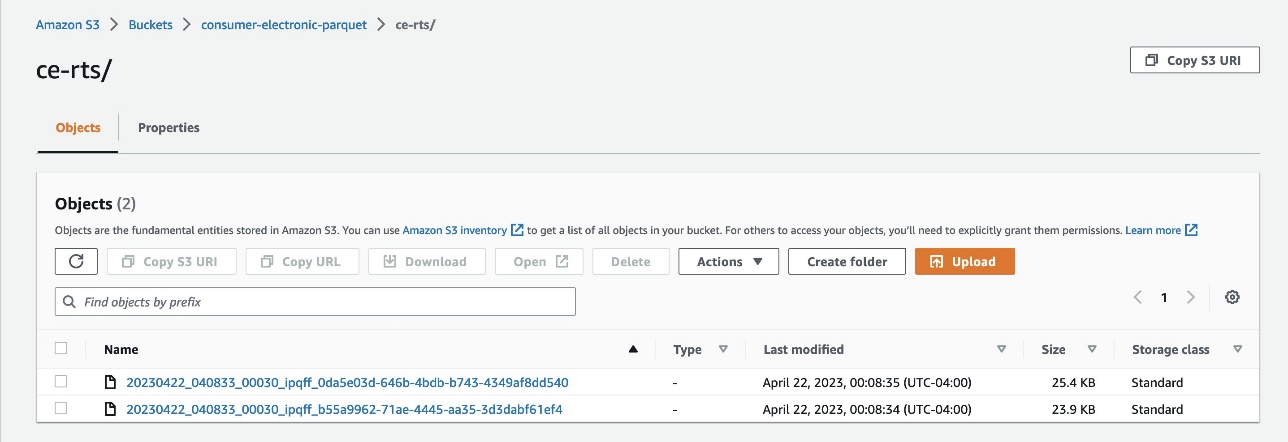
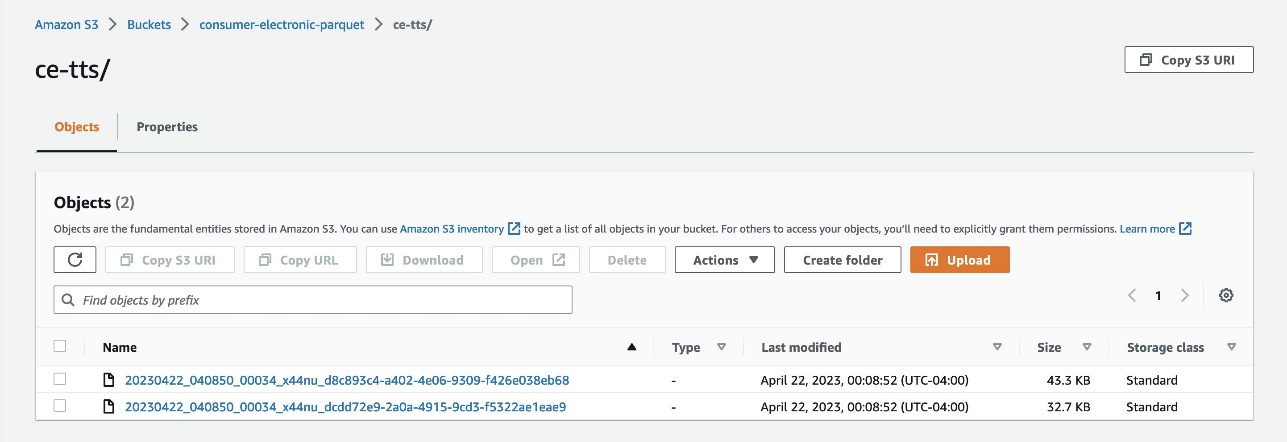
- Upload data to Amazon S3 as Parquet files from these two folders:
- ce-rts – Contains Consumer Electronics Related Time Series (RTS).
- ce-tts – Contains Consumer Electronics Target Time Series (TTS).
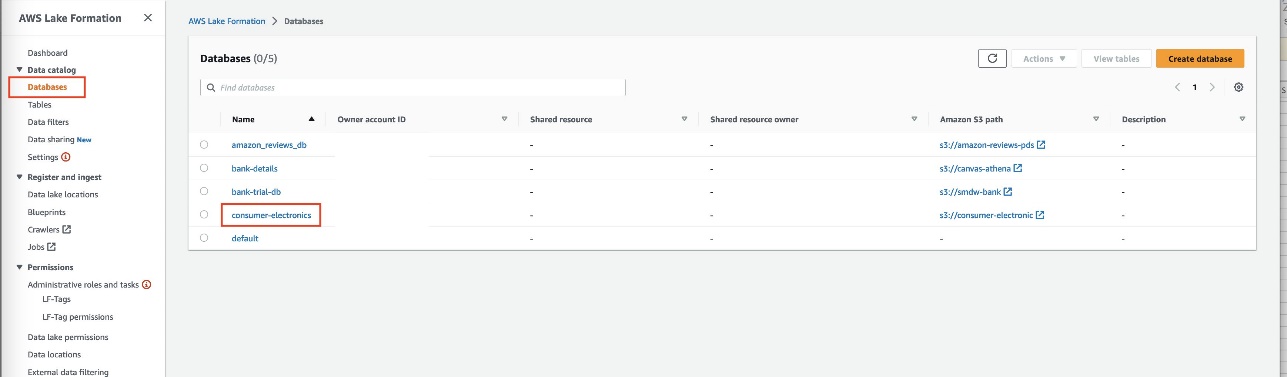
- Create a data lake with Lake Formation.
- On the Lake Formation console, create a database called
consumer-electronics.
- Create two tables for the consumer electronics dataset with the names
ce-rts-Parquetandce-tts-Parquetwith the data sourced from the S3 bucket.
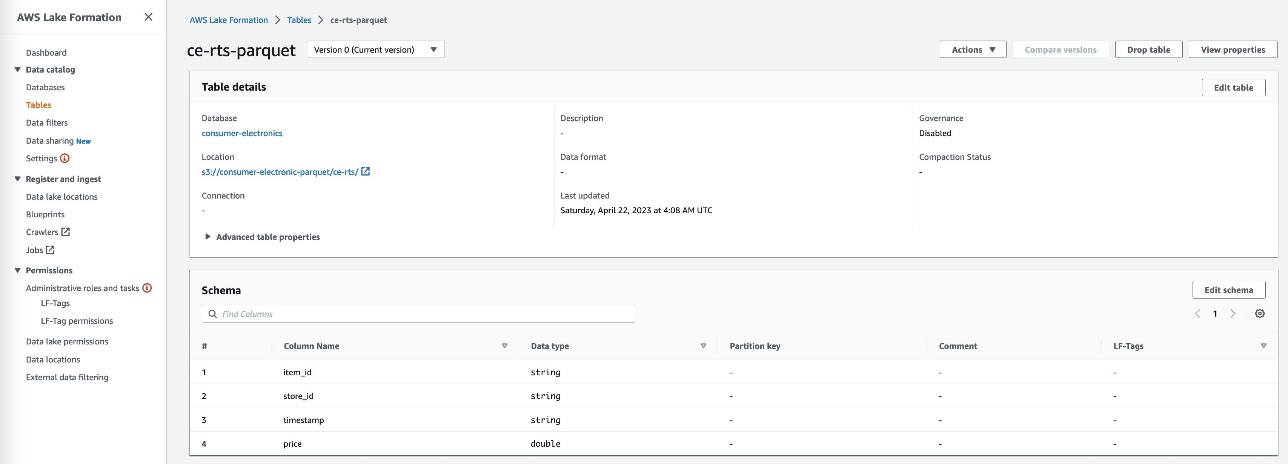
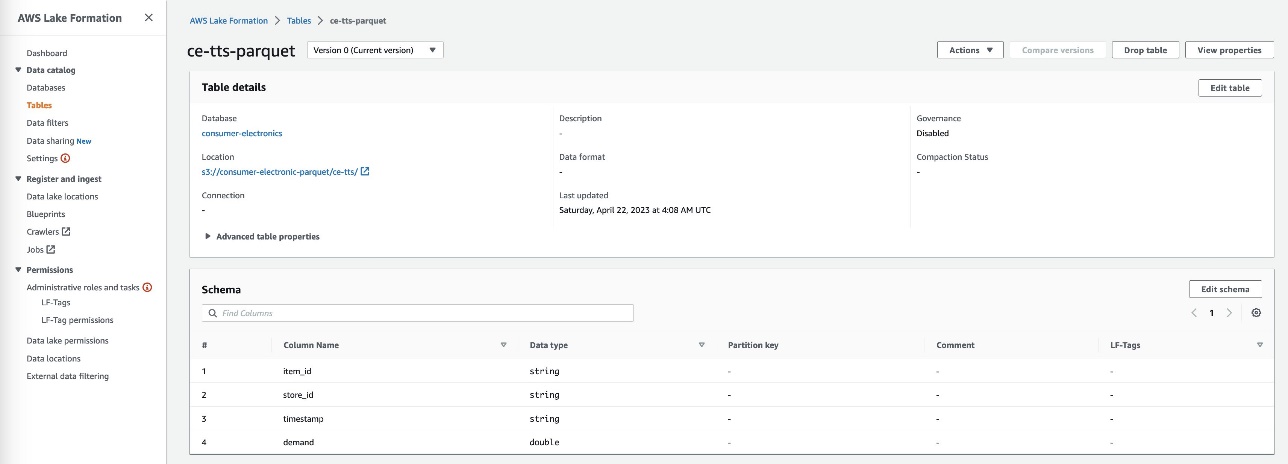
We use the database we created in this step in a later step to import the Parquet data into Canvas using Athena.
Grant Lake Formation access permissions to Canvas
This is a one-time setup to be done by either cloud engineers or administrators.
- Grant data lake permissions to access Canvas to access the consumer-electronics Parquet data.
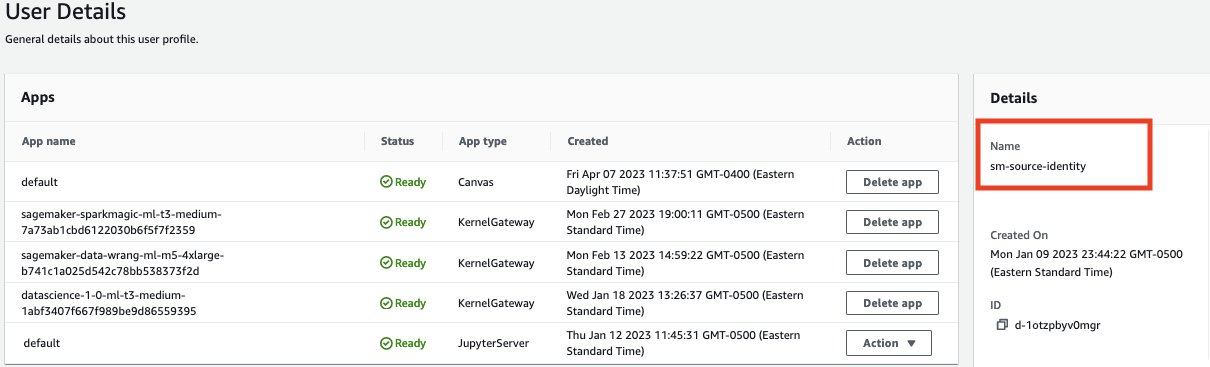
- In the SageMaker Studio domain, view the Canvas user’s details.
- Copy the execution role name.
- Make sure the execution role has enough permissions to access the following services:
- Canvas.
- The S3 bucket where Parquet data is stored.
- Athena to connect from Canvas.
- AWS Glue to access the Parquet data using the Athena connector.
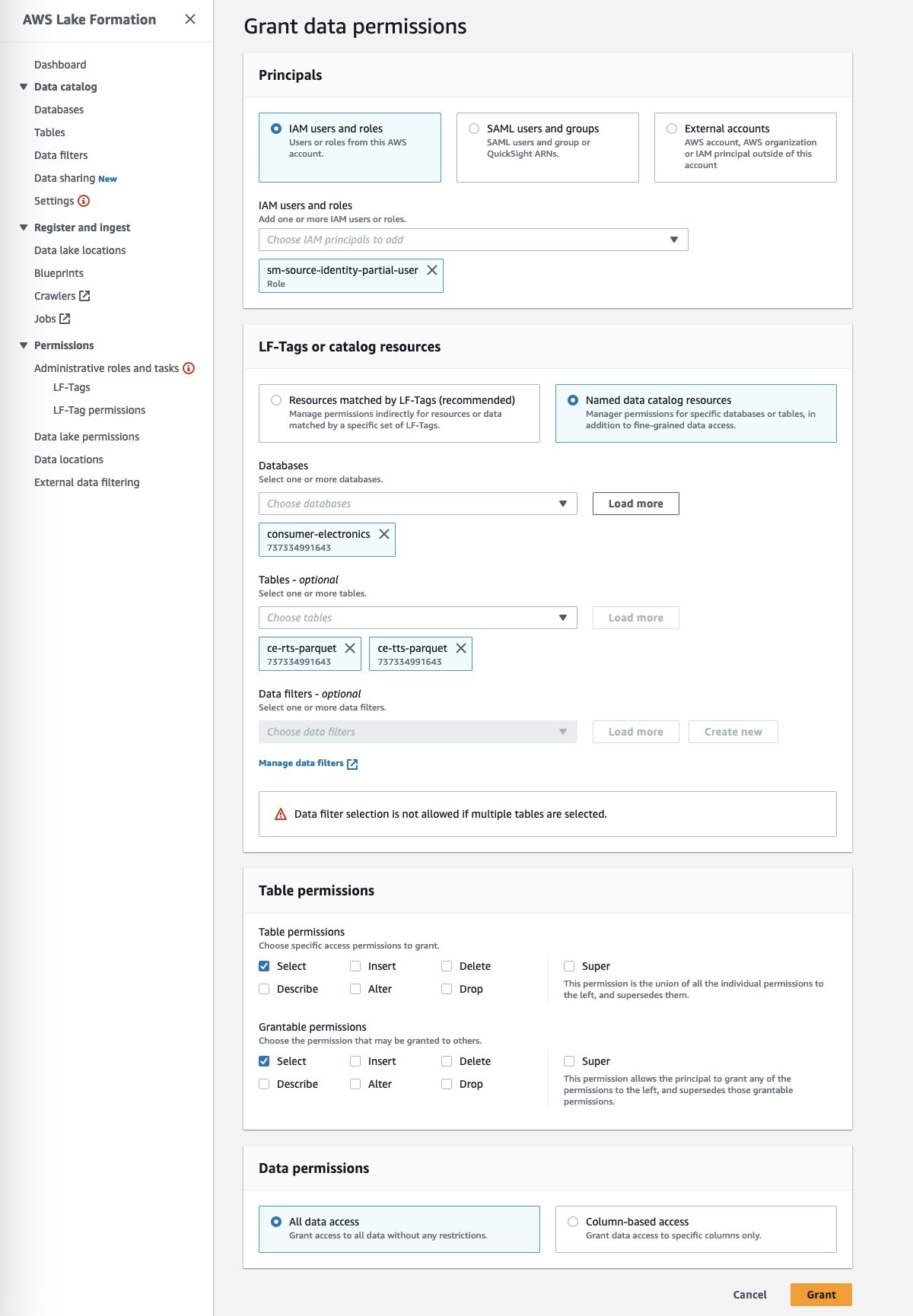
- In Lake Formation, choose Data Lake permissions in the navigation pane.
- Choose Grant.
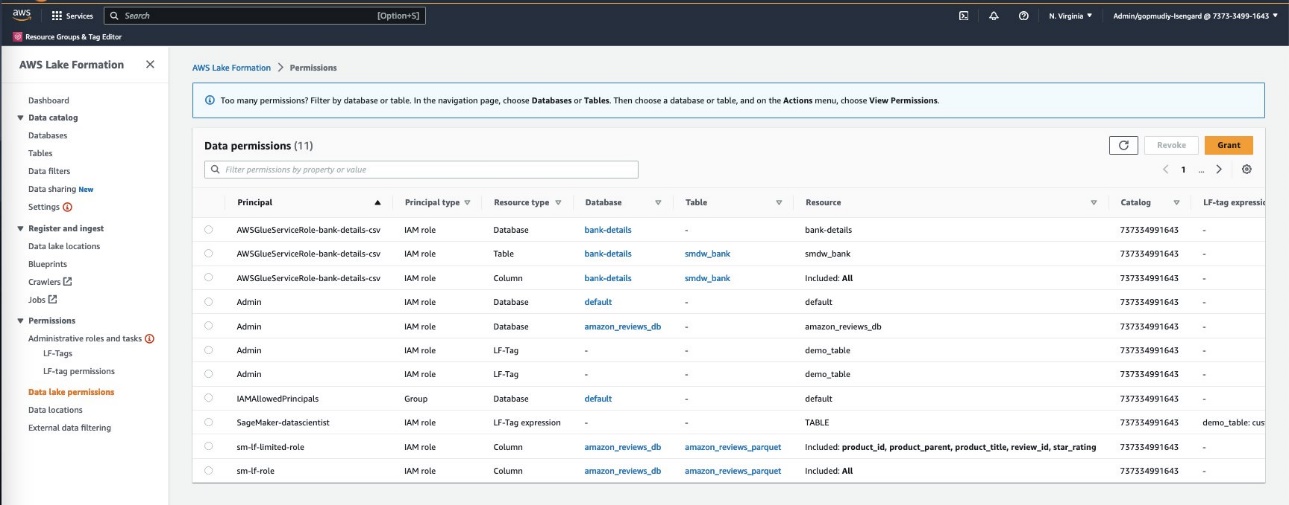
- For Principals, select IAM users and roles to provide Canvas access to your data artifacts.
- Specify your SageMaker Studio domain user’s execution role.
- Specify the database and tables.
- Choose Grant.
You can grant granular actions on the tables, columns, and data. This option provides granular access configuration of your sensitive data by the segregation of roles you have defined.
After you set up the required environment for the Canvas and Athena integration, proceed to the next step to import the data into Canvas using Athena.
Import data using Athena
Complete the following steps to import the Lake Formation-managed Parquet files:
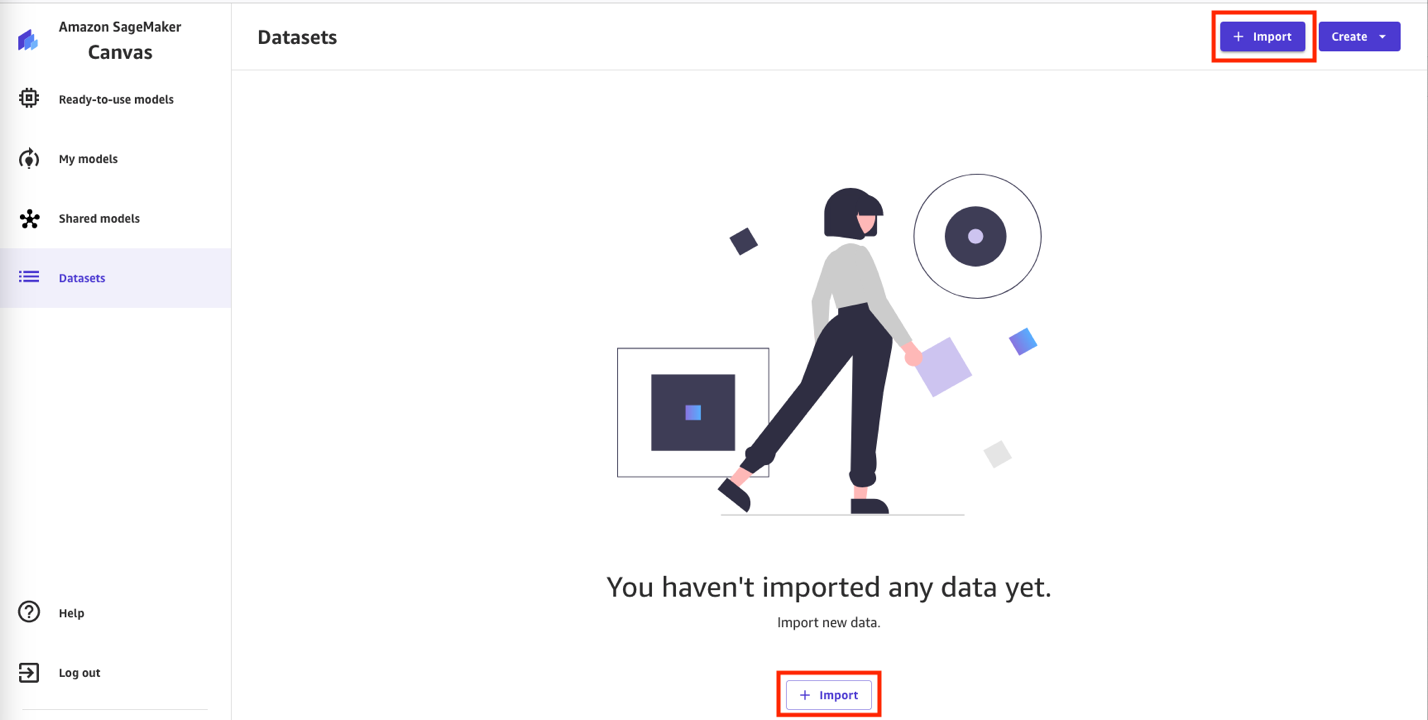
- In Canvas, choose Datasets in the navigation pane.
- Choose + Import to import the Parquet datasets managed by Lake Formation.
- Choose Athena as the data source.
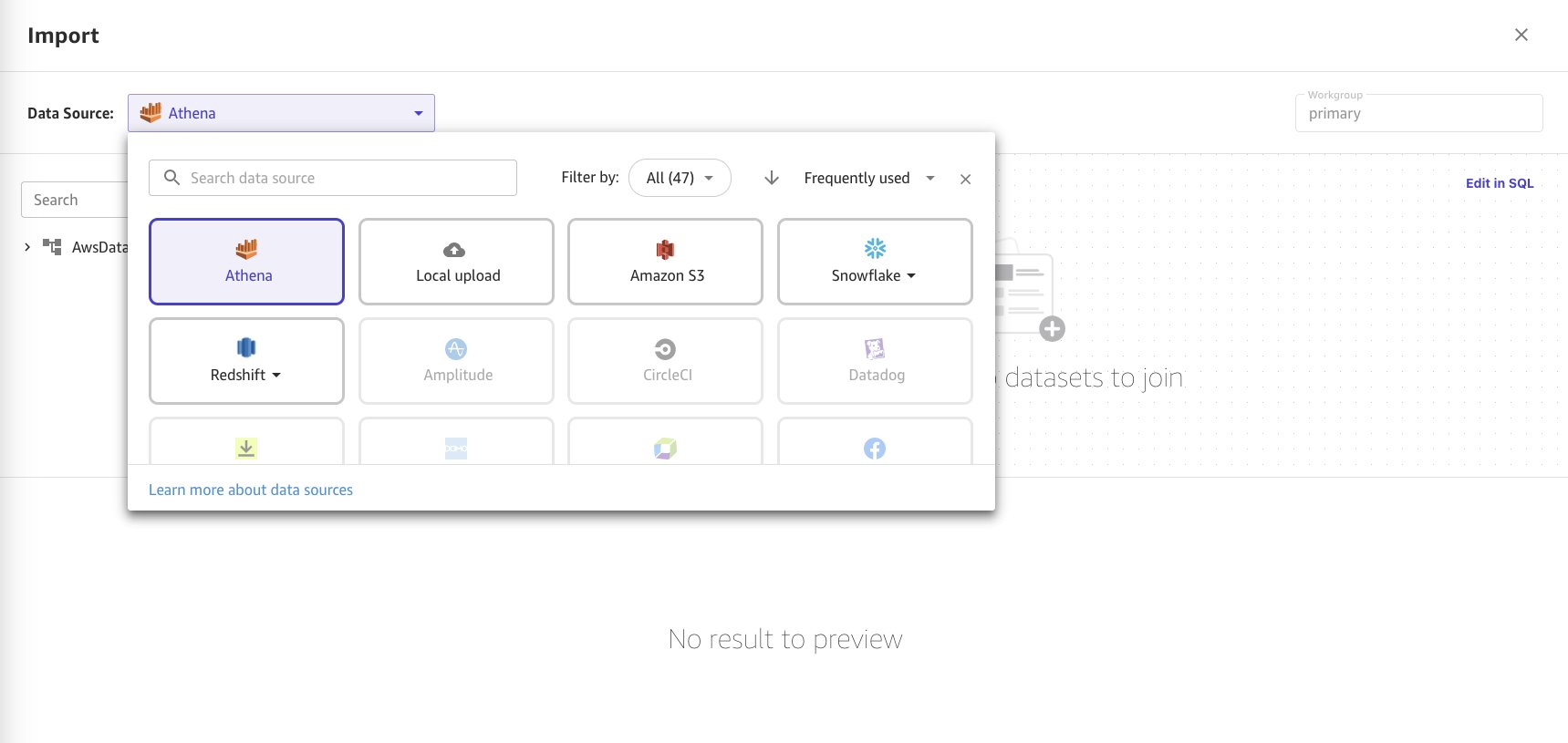
- Choose the
consumer-electronicsdataset in Parquet format from the Athena data catalog and table details in the menu. - Import the two datasets. Drag and drop the data source to select the first one.

When you drag and drop the dataset, the data preview appears in the bottom frame of the page.
- Choose Import data.
- Enter
consumer-electronics-rtsas the name for the dataset you’re importing.
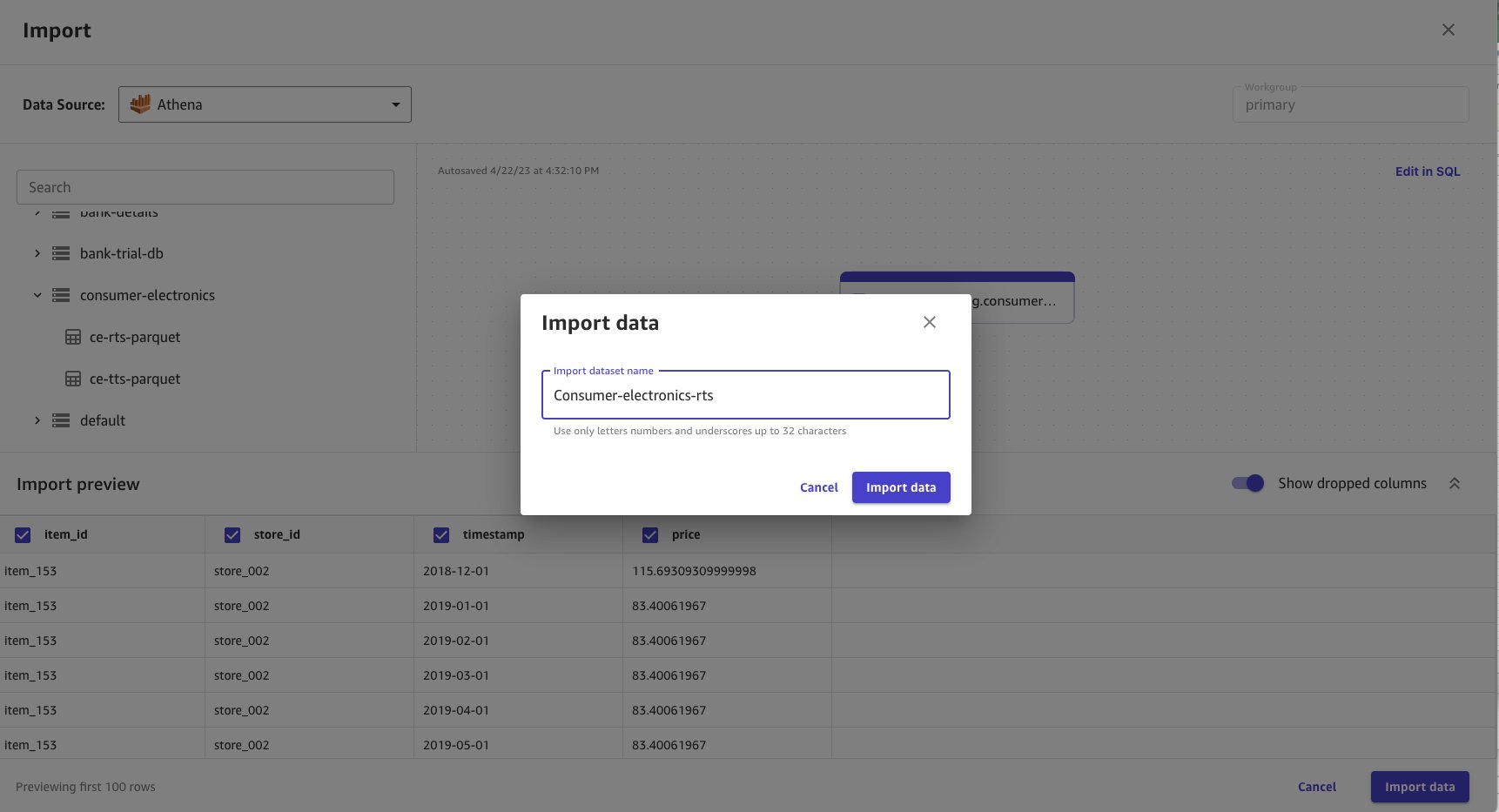
Data import takes time based on the data size. The dataset in this example is small, so the import takes a few seconds. When the data import is completed, the status turns from Processing to Ready.
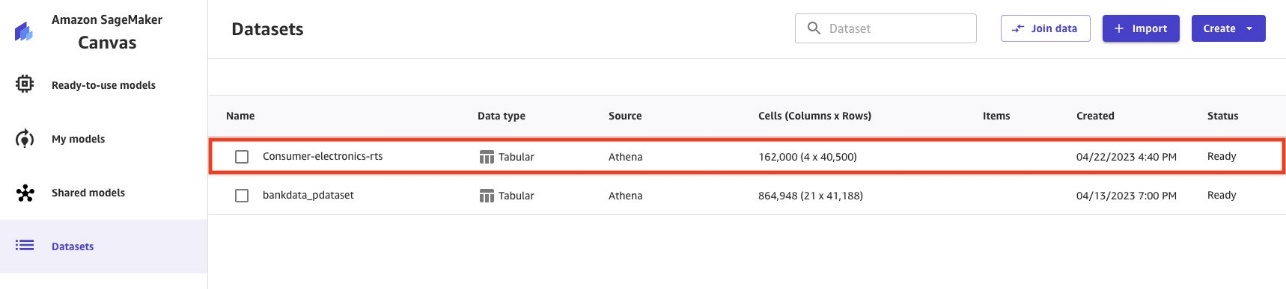
- Repeat the import process for the second dataset (
ce-tts).
When the ce-tts Parquet data is imported, the Datasets pageshow both datasets.
The imported datasets contain targeted and related time series data. The RTS dataset can help deep learning models improve forecast accuracy.
Let’s join the datasets to prepare for our analysis.
- Select the datasets.
- Choose Join data.
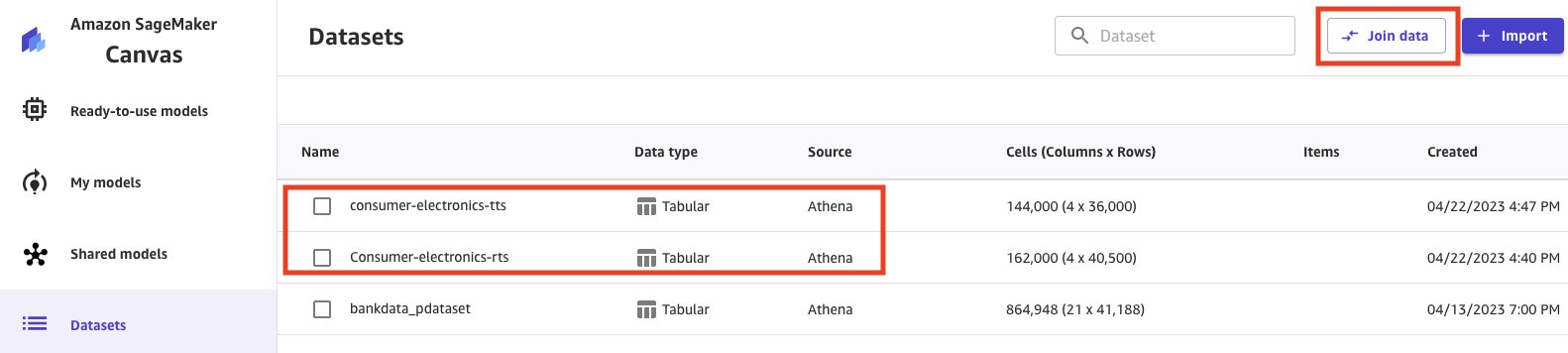
- Select and drag both the datasets to the center pane, which applies an inner join.
- Choose the Join icon to see the join conditions applied and to make sure the inner join is applied and the right columns are joined.
- Choose Save & close to apply the join condition.
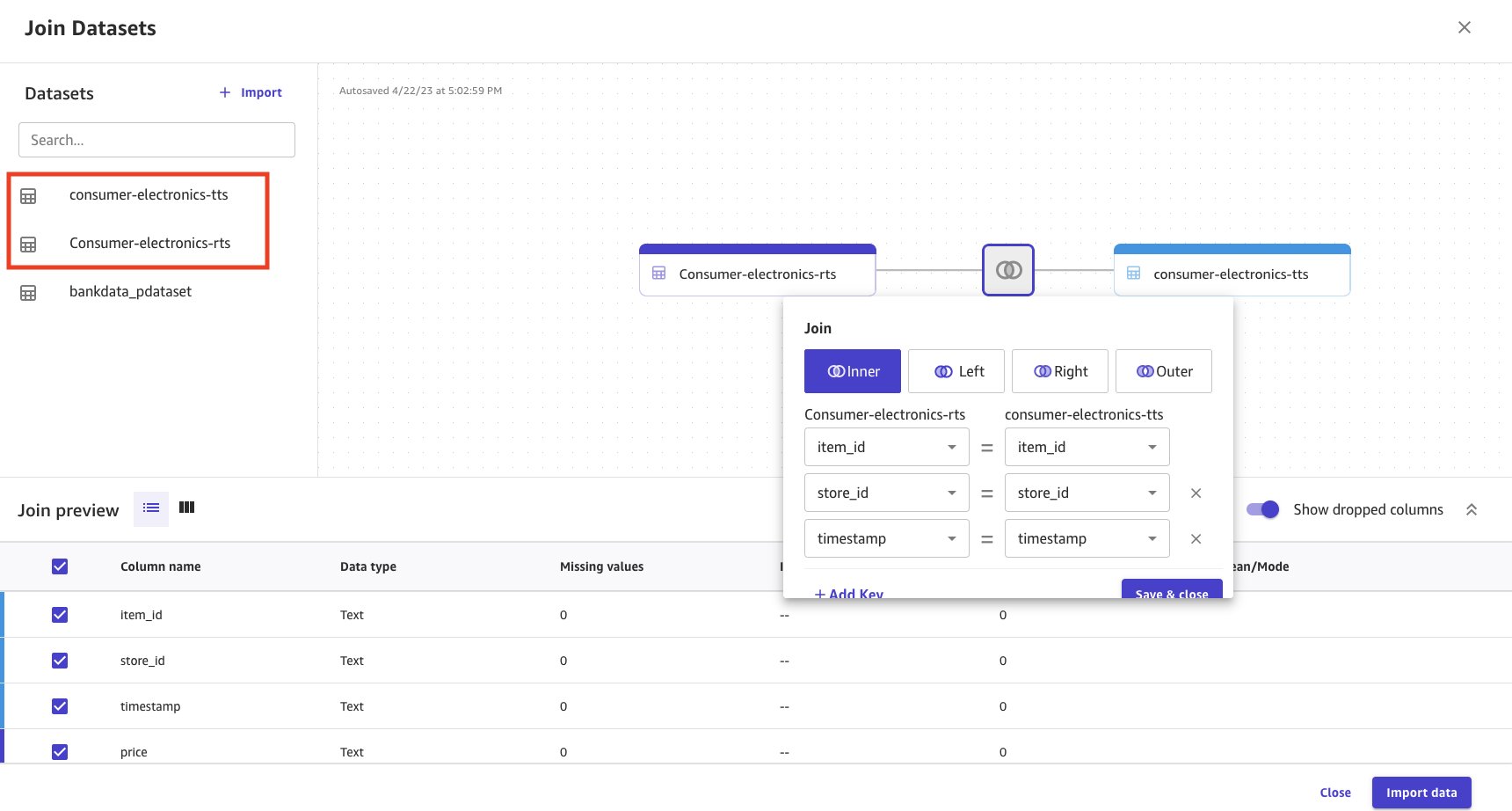
- Provide a name for the joined dataset.
- Choose Import data.
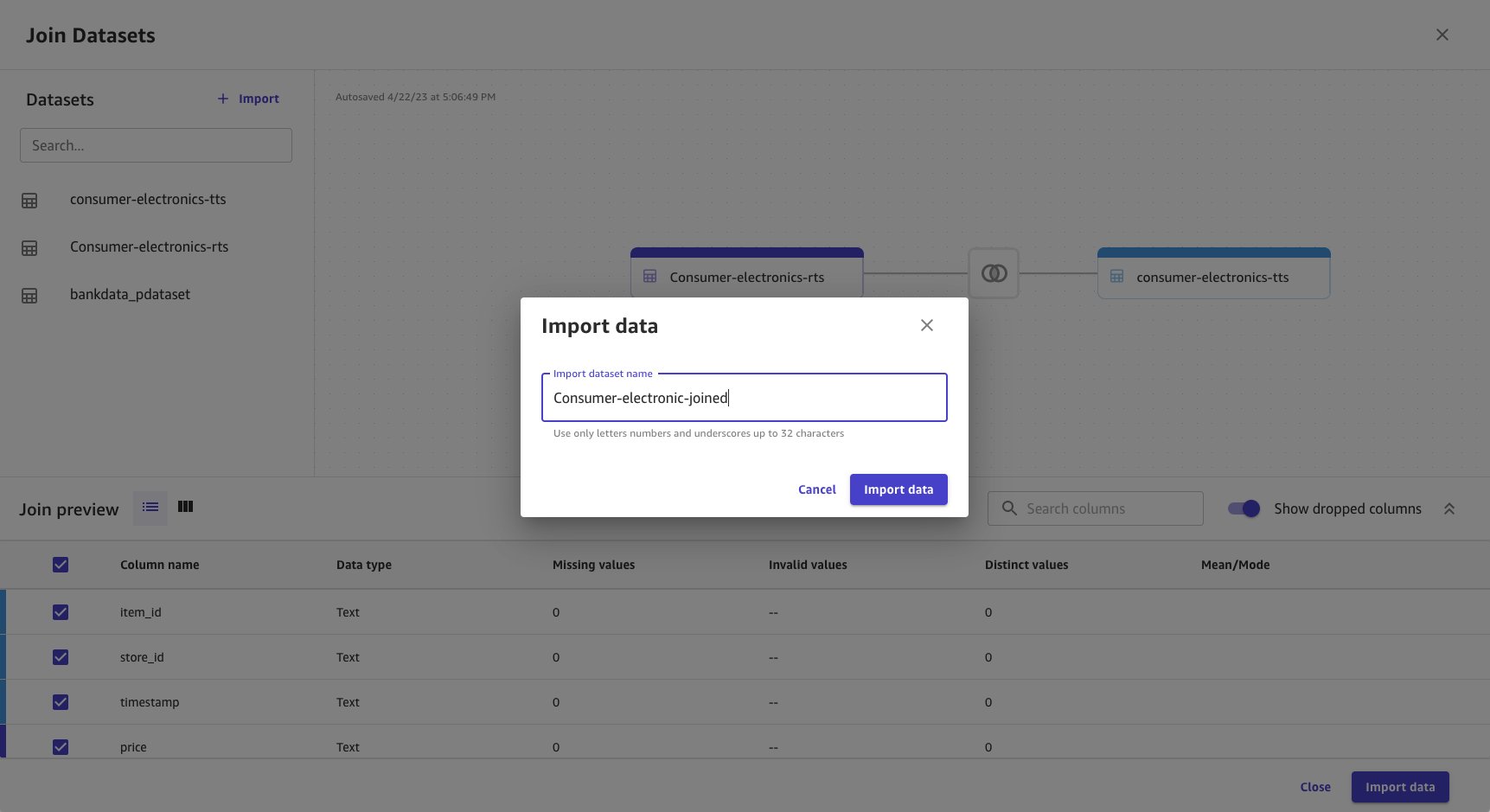
Joined data is imported and created as a new dataset. The joined dataset source is shown as Join.
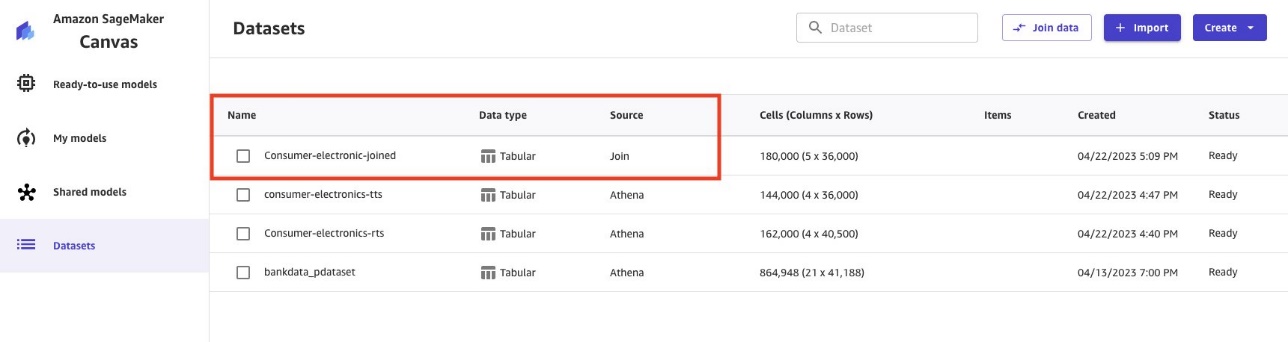
Use the Parquet data to build ML models with Canvas
The Parquet data from Lake Formation is now available on Canvas. Now you can run your ML analysis on the data.
- Choose Create a custom model in Ready-to-use models from Canvas after successfully importing the data.
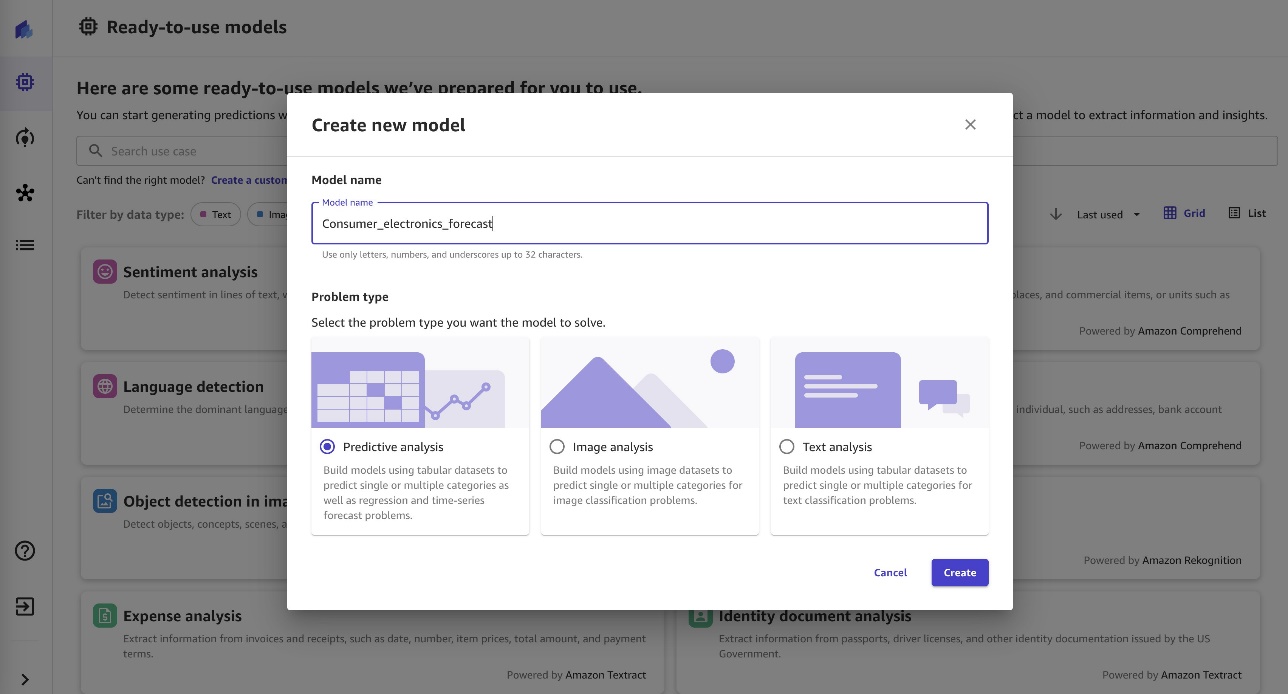
- Enter a name for the model.
- Select your problem type (for this post, Predictive analysis).
- Choose Create.
- Select the
consumer-electronic-joineddataset to train the model to predict the demand for electronic items.
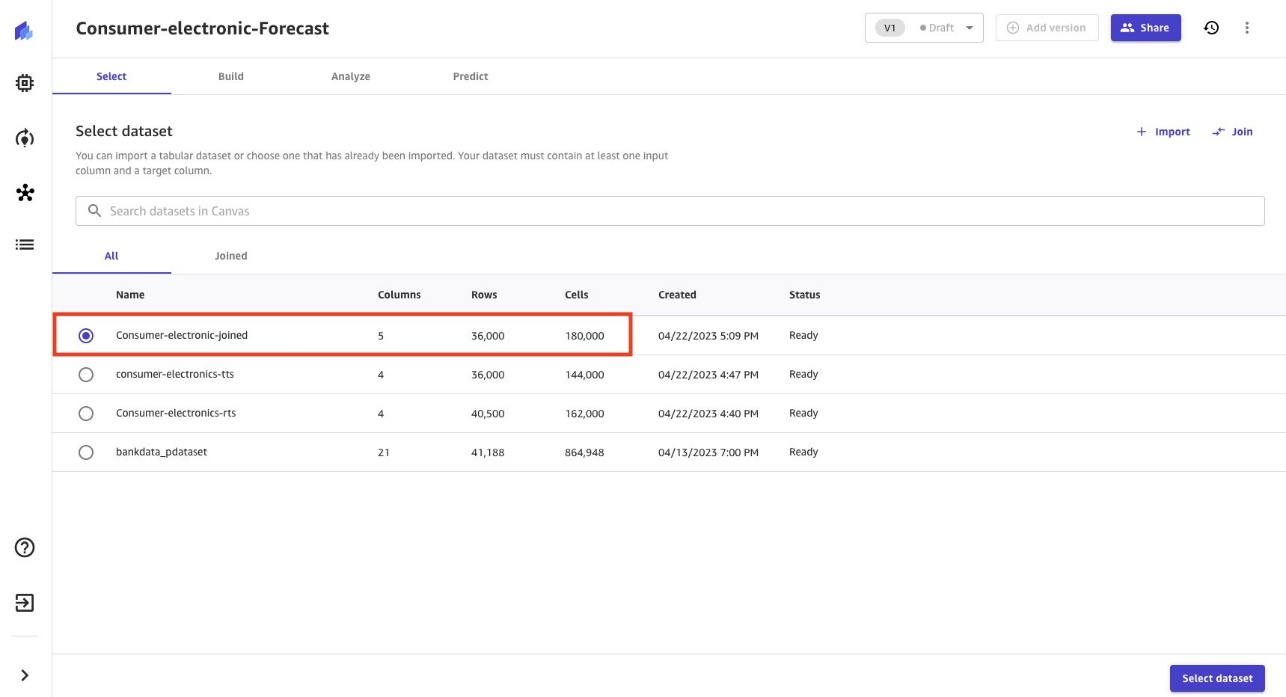
- Select demand as the target column to forecast demand for consumer electronic items.
Based on the data provided to Canvas, the Model type is automatically derived as Time series forecasting and provides a Configure time series model option.
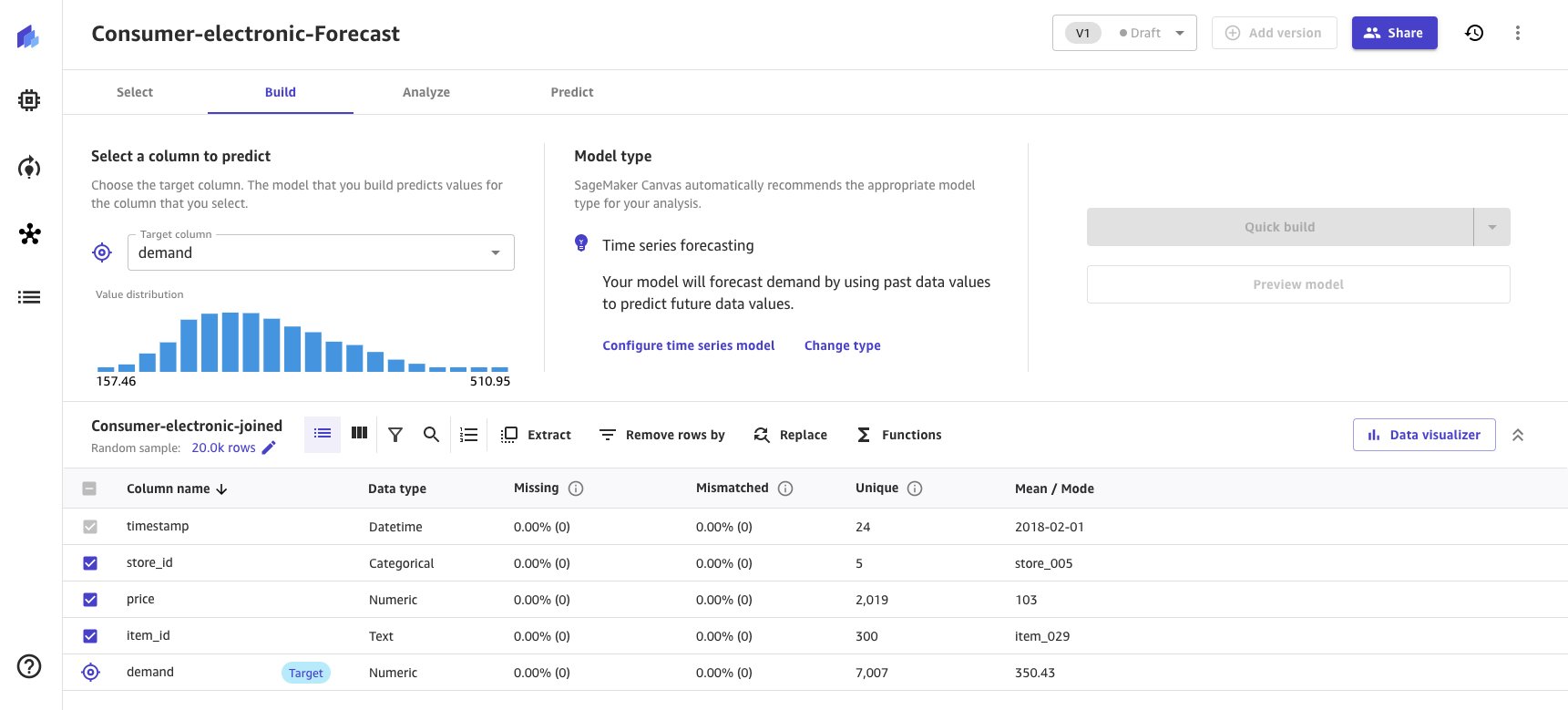
- Choose the Configure time series model link to provide time series model options.
- Enter forecasting configurations as shown in the following screenshot.
- Exclude group column because no logical grouping is executed for the dataset.
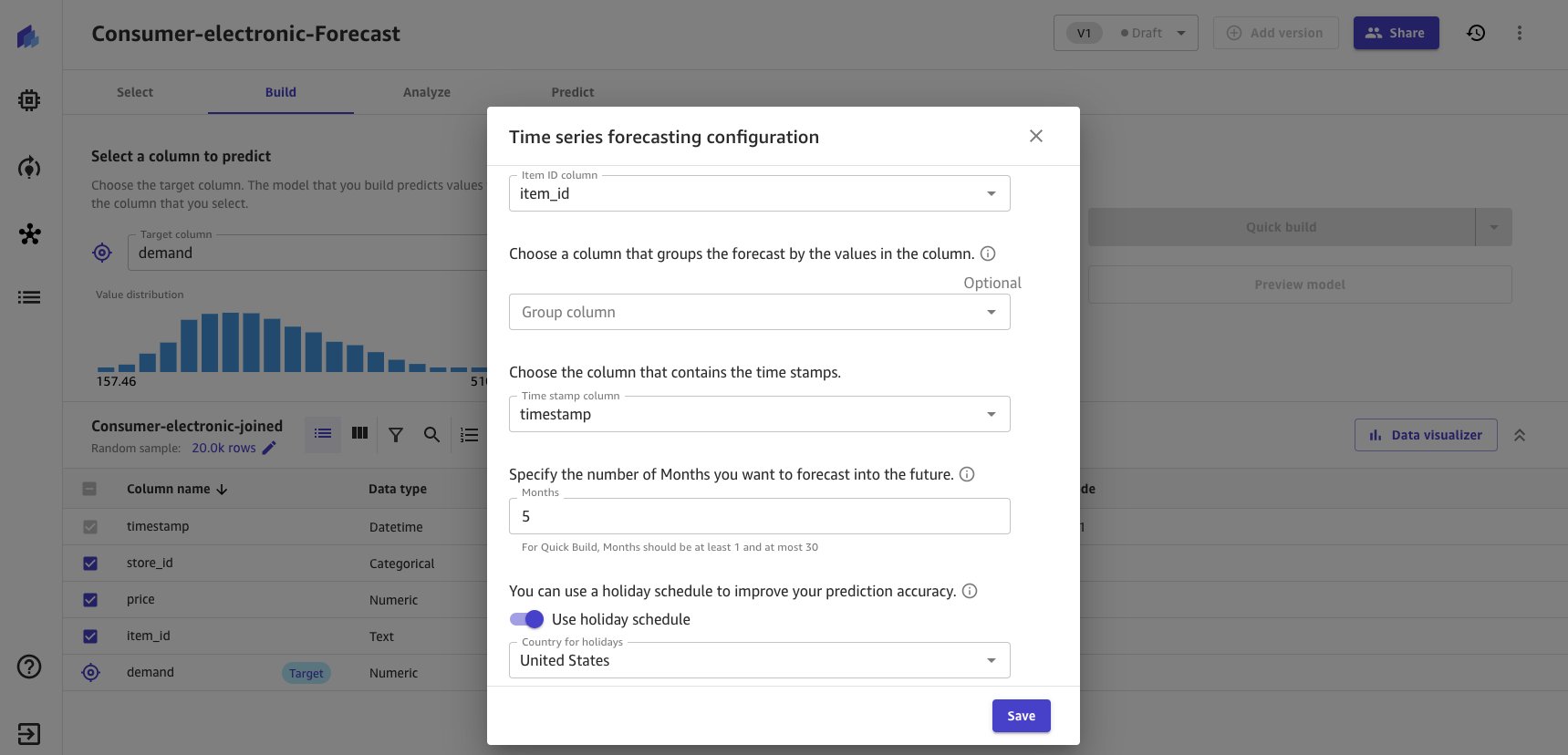
For building the model, Canvas offers two build options. Choose the option as per your preference. Quick build generally takes around 15–20 minutes, whereas Standard takes around 4 hours.
-
- Quick build – Builds a model in a fraction of the time compared to a standard build; potential accuracy is exchanged for speed
- Standard build – Builds the best model from an optimized process powered by AutoML; speed is exchanged for greatest accuracy
- For this post, we choose Quick build for illustrative purposes.

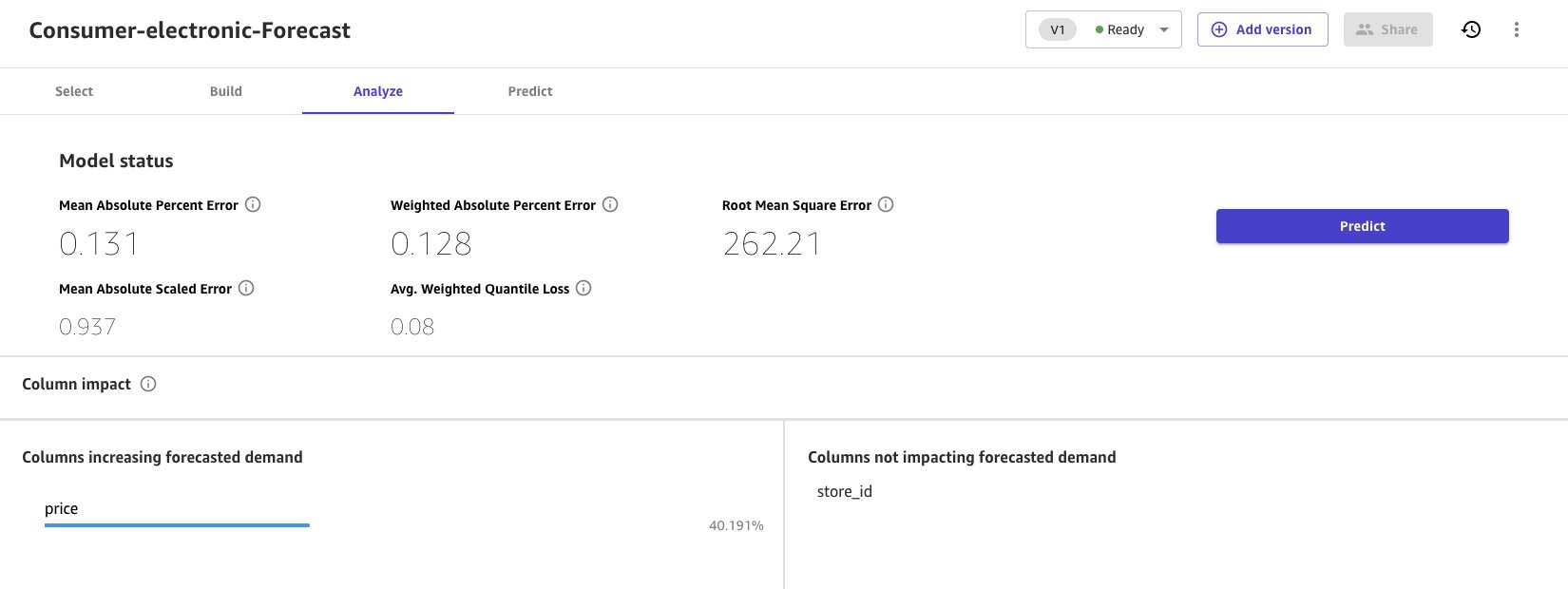
When the quick build is completed, the model evaluation metrics are presented in the Analyze section.
- Choose Predict to run a single prediction or batch prediction.
Clean up
Log out from Canvas to avoid future charges.
Conclusion
Enterprises have data in data lakes in various formats, including the highly efficient Parquet format. Canvas has launched more than 40 data sources, including Athena, from which you can easily pull data in various formats from data lakes. To learn more, refer to Import data from over 40 data sources for no-code machine learning with Amazon SageMaker Canvas.
In this post, we took Lake Formation-managed Parquet files and imported them into Canvas using Athena. The Canvas ML model forecasted the demand of consumer electronics using historical demand and price data. Thanks to a user-friendly interface and vivid visualizations, we completed this without writing a single line of code. Canvas now allows business analysts to use Parquet files from data engineering teams and build ML models, conduct analysis, and extract insights independently of data science teams.
To learn more about Canvas, refer to Predict types of machine failures with no-code machine learning using Canvas. Refer to Announcing Amazon SageMaker Canvas – a Visual, No Code Machine Learning Capabilities for Business Analysts for more information on creating ML models with a no-code solution.
About the authors
 Gopi Mudiyala is a Senior Technical Account Manager at AWS. He helps customers in the Financial Services industry with their operations in AWS. As a machine learning enthusiast, Gopi works to help customers succeed in their ML journey. In his spare time, he likes to play badminton, spend time with family, and travel.
Gopi Mudiyala is a Senior Technical Account Manager at AWS. He helps customers in the Financial Services industry with their operations in AWS. As a machine learning enthusiast, Gopi works to help customers succeed in their ML journey. In his spare time, he likes to play badminton, spend time with family, and travel.
 Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.
Hariharan Suresh is a Senior Solutions Architect at AWS. He is passionate about databases, machine learning, and designing innovative solutions. Prior to joining AWS, Hariharan was a product architect, core banking implementation specialist, and developer, and worked with BFSI organizations for over 11 years. Outside of technology, he enjoys paragliding and cycling.