Artificial Intelligence
Use integrated explainability tools and improve model quality using Amazon SageMaker Autopilot
Whether you are developing a machine learning (ML) model for reducing operating cost, improving efficiency, or improving customer satisfaction, there are no perfect solutions when it comes to producing an effective model. From an ML development perspective, data scientists typically go through stages of data exploration, feature engineering, model development, and model training and tuning with the objective of achieving the optimal model given the available data. However, finding the best model often requires experimenting with different combinations of input, algorithms, hyperparameters, and so on. This process is very iterative, time-consuming, and resource intensive, as shown in the following figure (the arrows to point to repetitive tasks, typically performed manually).

To address these challenges, a process called automated machine learning, or AutoML, was introduced to automate the repeated processes in ML development, with the vision of producing high-quality models to deliver the desired business value faster and lower cost. At AWS re:Invent 2019, we announced Amazon SageMaker Autopilot, an AutoML implementation that uses the white box approach to automate the ML model development lifecycle, with full control and visibility to data scientists and developers.
You can bring your own dataset and use Autopilot to build the best model and deploy ML in production to solve business challenges. Based on customers’ feedback, we delivered additional features in 2021. These features focus on model explainability through integration with Amazon SageMaker Clarify, and a cross-validation method for improving model quality on smaller datasets up to 35%. The following diagram shows an Autopilot workflow integration with model explainability and cross-validation.

The purple lines represent 10 candidate pipelines run in parallel with 250 automatic hyperparameter tuning jobs incorporating cross-validation to achieve best results. A model explainability report is created based on the best model identified in the pipeline.
Model explainability
As the field of ML and AI matures, we’re seeing an increased demand across industries to use AI as part of the decision-making processes that may have an impact on individuals. For instance, automating loan application approvals, making health-related diagnoses, and using self-driving vehicles. It’s important to understand how ML models make predictions so that we can continue to advance the AI field with better prediction quality, fairness, and tools to identify and mitigate bias. This led to the study of explainable AI, with a vision to understand biases and provide explainability to the ML models. Clarify provides data scientists and developers a tool that enables greater visibility into training data and models, so they can identify potential bias in training data and trained models across the ML lifecycle, and address bias metrics identified in the report. Autopilot integrates with Clarify to incorporate model explainability analysis and report generation for the best model obtained through candidate pipeline runs.
K-fold cross-validation
K-fold cross-validation is a standard model validation method for assessing ML model performances. This method is commonly used in regression or classification algorithms to overcome overfitting issues when working with a small number of training samples. In general, it works by sampling the dataset into groups of similar sizes, where each group contains a subnet of data dedicated for training and model evaluation respectively. After the data has been grouped, an ML algorithm fits and scores a model using the data in each group independently. The final score of the model is defined by the average score across all the trained models for performance metric representation. Autopilot automatically incorporates the k-fold cross-validation method for datasets up to 50,000 rows.
Solution overview
Now that we understand the new features in more detail, let’s dive deeper to see how to use these features to achieve better model visibility and quality.
In a high level, the solution breaks down into the following steps:
- Define the ML model objective.
- Prepare the dataset.
- Create an Autopilot experiment.
- Evaluate the Autopilot model:
- Explore the model explainability report.
- Evaluate the cross-validation configuration in the candidate notebook and
- cross-validation output via Amazon CloudWatch Logs.
Prerequisites
To follow along with this post, you need the following prerequisites:
- Access to Amazon SageMaker Studio.
- An AWS Identity and Access Management (IAM) role that allows Studio to access Amazon Simple Storage Service (Amazon S3) and to create a SageMaker experiment, hyperparameter tuning and training jobs, model objects, and endpoints. For instructions on setting up the appropriate permissions, see SageMaker Roles.
Define the ML model objective
The main objective is to build a binary classification model that predicts the target income for individuals based on the given census data. Given the small sample size, we use the k-fold cross-validation method in Autopilot to help us improve model scoring metrics. Additionally, we use the model explainability report generated through the Autopilot job to help us understand how each feature in the dataset contributes to the model outcome.
Public census data
For this experiment, we use the public census data (Dua, D. and Graff, C. (2019). UCI Machine Learning Repository. Irvine, CA: University of California, School of Information and Computer Science) for training and validation data. The prediction task is to determine whether a person makes over $50,000 a year.
This dataset contains 14 features that cover the diversity of demographic characteristics, with 45,222 rows (32,561 for training and 12,661 for testing). The following is a summary of the features and target labels:
- Age – Age of the participant
- Workclass – Type of working class
- Fnlwgt – Number of people the census takers believe that observation represents
- Education – Education levels
- Education-num – Years of education
- Marital-status – Marital status
- Occupation – Occupation
- Relationship – Relationship
- Ethnic group – The ethnic group of the participant
- Sex – Gender
- Capital-gain – Capital gain
- Capital-loss – Capital loss
- Hours-per-week – Work hours per week
- Country – Country of origin
- Target – <=$50,000, >$50,000
Prepare the dataset
To prepare your dataset, complete the following steps:
- On the Studio Control Panel, on the File menu, choose New and Notebook.
- Choose Python 3 (Data Science) for your kernel.

A few minutes later, the kernel should be started and ready to go.
- Import the Python libraries and define the S3 bucket and prefix for storing the CSV file:
- In the next cell, download the census dataset from the UCI repository:
- Apply the column names to the dataset:
The following screenshot shows our results.

- Verify the number of rows in the database by getting the dimension of the dataset:
![]()
- Save the dataset as a CSV file and upload it to the S3 bucket:
Create an Autopilot experiment
Depending on your preference, you can either create an Autopilot job through the Studio user interface without writing a single line of code, or use the SageMaker SDK in a SageMaker notebook. The following notebook uses the SageMaker SDK to create an Autopilot job. For simplicity, we explore the no code approach using the Studio console to demonstrate these new features.
At a high level, you perform the following steps in Studio to create an Autopilot job:
- Create an experiment name.
- Configure an input data location in an S3 bucket.
- Select the target column to use as the label column.
- Configure an output path in the S3 bucket for storing the output artifacts.
- Configure the ML problem type. Both regression and classification are supported.
- Configure Autopilot to either run a complete AutoML pipeline with training, tuning, and an explainability report, or simply run the job to produce candidate definitions and data exploration notebooks.
- Configure IAM role, encryption key, and VPC for the Autopilot job.
- Configure the Autopilot maximum runtime for an individual training job, maximum runtime for an Autopilot job, and maximum number of training jobs the Autopilot is allowed to run.
Studio UI walkthrough
To create an Autopilot experiment using Studio, complete the following steps:
- On the Studio Control Panel, choose the Components and registries icon in the navigation pane.
- Choose Experiments and trials on the drop-down menu.
- Choose Create Experiment.

- Enter a name for the experiment, such as
MyAutopilotExperiment. - Under Connect your data, select Enter S3 bucket location.
- Enter the location for the CSV file uploaded to the S3 bucket in the previous step:
s3://<sagemaker-default-bucket>/examples/sagemaker-autopilot-experiment/input/adult.data.csv - Choose Target for your target column, then select the column.

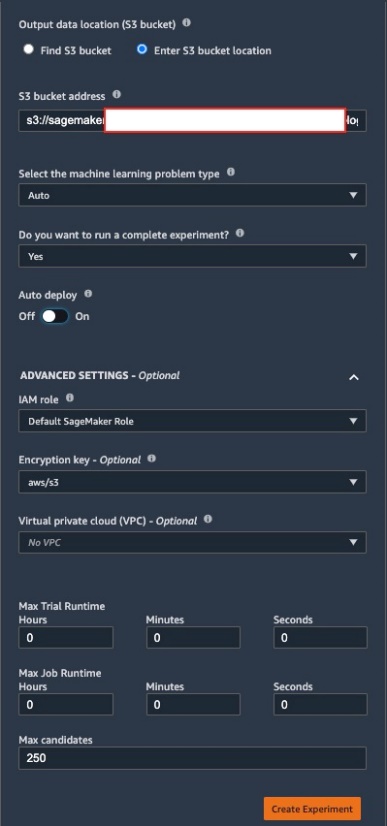
- Under Output data location (S3 bucket), select Enter S3 bucket location.
- Enter an appropriate S3 bucket location for storing the output artifacts:
s3://<sagemaker-default-bucket>/examples/sagemaker-autopilot-experiment/output - Turn Auto deploy off to disable automatic model deployment.
- Choose an appropriate encryption key to encrypt the input and output S3 buckets if applicable.
- Choose Create Experiment.
After SageMaker triggers an Autopilot job, you can track and monitor the progress directly from within Studio, as shown in the following screenshot. Depending on the volume of input data, the Autopilot job may take a few hours to complete. In my experiment with the dataset in this post, the Autopilot job took about 4 hours to complete.

Evaluate the Autopilot model
You can view the job details, including the status and metrics for all training jobs triggered by Autopilot, after submission. Autopilot automatically ranks the trained models by the objective metrics selected by Autopilot based on the problem type.
- After the Autopilot job is complete, expand Experiment and trials on the Studio Control Panel.
- Choose (right-click) the specified Autopilot experiment job.
- Choose Describe AutoML job.

In the new Experiment tab, you can see a leaderboard that consists of names, statuses, start time, and objective metrics sorted in descending order. In this example, F1_binary was the objective metric based on the binary classification problem type.

Model explainability
Autopilot integrates with Clarify to provide visibility into trained models to help you explain how models make predictions and help identify biases. Clarify implements SHAP, based on the concept of Shapley value with a theoretical background in game theory. SHAP values can help explain how many ML models make predictions by identifying feature importance.
Autopilot calculates feature importance using SHAP values for all the features used in training, and produces a visual report that highlights the top 10 most important features in terms of SHAP values. The visual report can also be downloaded as a PDF. Additionally, Autopilot generates and stores the analysis result in JSON format in the specified S3 bucket.
To view the explainability report from within Studio, choose the best model (right-click) on the Experiment tab, and choose Open in model details.

On the Model details tab, we see the Model explainability bar chart, which demonstrates the feature importance generated by Clarify through Autopilot. In my example, the analysis showed that age is the most important feature in determining the target income based on the given dataset.

You can also access a complete list of SHAP values in JSON format for all the features by choosing Download raw data and downloading the data to your local machine. The downloaded file is named analysis.json.
The following code is the full content of the analysis in JSON. We can also observe that country is the least important feature in predicting the target income.
All generated reports are automatically uploaded to the S3 bucket in the location relative to the output path specified for the Autopilot job. In my example, the reports are stored in the the following S3 path: s3://<sagemaker-default-bucket>/examples/sagemaker-autopilot-experiment/output/MyAutopilotExperiment/documentation/explainability/output/<experiment job id>/
K-fold cross-validation
When developing a regression or classification model, it’s typical to split the input dataset into independent training and validation sets using the standard 90/10, 80/20, or 70/30 split ratios. This approach works as long as there is a reasonable amount of data available to train and validate a model accurately. However, this standard approach works against model performance for smaller datasets because it reduces the data available to perform training and validation. The cross-validation method is designed to address the problem by allowing all data to be used in both training and evaluation through k training iterations. This method leads to highly accurate model performance metrics, and a reduced chance of overfitting. Given the challenges working with small datasets, Autopilot automatically applies cross-validation method for datasets under 50,000 rows without any additional work required on you end.
With 48,842 total rows in our sample dataset, Autopilot triggers the cross-validation method for model training.
Thanks to the white box AutoML approach, we can examine the cross-validation method used in the Autopilot job in great detail.
Autopilot job generates two notebooks: candidate generation and data exploration. For this post, we focus on the candidate generation notebook to validate cross-validation configuration. On the Autopilot Experiment tab, choose Open candidate generation notebook to open the notebook.

All cross-validation related configurations are defined as hyperparameter values in the Automatic Model Tuning section of the notebook. To find it, search for “Multi Algorithm Hyperparameter Tuning” in the notebook to see the configurations, as shown in the following code:
Autopilot calculates the optimized hyperparameter values based on the size of the input dataset and the chosen algorithm. Given our configuration, the cross-validation method is applied in both the XGBoost and MLP algorithms with kfold = 5 and num_cv_rounds = 3. These values are configured as training job definitions in a multi-algorithm hyperparameter tuning job for model training and optimization processes.
By default, SageMaker streams training job logs to CloudWatch Logs, making it easy for data scientists and developers to find, debug, and troubleshoot training-related issues. Given the visibility to these log messages, we can easily verify cross-validation steps performed in the training jobs. To locate the CloudWatch Logs messages for the training job that produced the best result, complete the following steps:
- On the Autopilot Experiment tab, choose the best model (right-click the model on the first row).
- Choose Copy cell contents to copy the trial component name associated with the best model for later use.

- In the Experiments and trials pane, choose the Autopilot experiment (right-click).
- Choose Open in trial component list.

- On the Trial components tab, in the search bar, enter Trial Component Name, then enter the cell content copied to your clipboard in step 2 into the search text field.
- Because we’re using the best model on the Experiment tab, we must remove the prefix Best: from the search box so that a matching record can be found.
- Choose Apply.

One row should be returned from the search result.
If the search didn’t return anything, verify the component name again. Make sure the prefix Best: is completely removed, including an extra space in between.
- Choose the trial component (right-click).
- Choose Open in trial details to open a new tab called Describe Trial Component.

- On the Describe Trial Component tab, choose the AWS settings tab.

- Scroll down to the bottom and choose View logs to open a new browser tab with the CloudWatch Logs for the specific training job.
- On the CloudWatch console, choose the latest log stream of the specified CloudWatch Logs group.
- In the search box, enter
cross validationto filter the messages related to cross-validation.

You can remove the search filter to see the complete log messages for the training job. The following screenshot shows the overall metrics from running three rounds of cross-validation.

Conclusion
In this post, we showed you how to use Autopilot to help with model visibility and improve performance for your AutoML models. Autopilot integrates with Clarify to provide model explainability for the best model so you can better understand how your model makes predictions. You can view the generated model explainability report directly on the Studio console, or access the report in a PDF, HTML, Python notebook, or raw JSON file in the S3 bucket location that you specified. Additionally, Autopilot analyzes your input dataset and automatically applies the k-fold cross-validation method to train the models with a dataset up to 50,000 rows. Because the cross-validation method uses all the data for model training and validation, it can help address the challenges of overfitting and produce better model accuracy assessments.
Best of all, Autopilot enables these features by default, so there are no extra steps needed to improve your ML development experience. Go ahead and give it a try today, and we’d love to hear your feedback in the comments. To learn more about Amazon SageMaker Autopilot, visit our webpage!
About the Author
 Wei Teh is an AWS Solutions Architect who specializes in artificial intelligence and machine learning. He is passionate about helping customers advance their AWS journey, focusing on Amazon Machine Learning services and machine learning-based solutions. Outside of work, he enjoys outdoor activities like camping, fishing, and hiking with his family.
Wei Teh is an AWS Solutions Architect who specializes in artificial intelligence and machine learning. He is passionate about helping customers advance their AWS journey, focusing on Amazon Machine Learning services and machine learning-based solutions. Outside of work, he enjoys outdoor activities like camping, fishing, and hiking with his family.