AWS Public Sector Blog
Unlock enterprise data for generative AI by integrating structured sources with Amazon Bedrock in AWS GovCloud (US)

Public sector organizations building on Amazon Web Services (AWS) are increasingly using generative AI to modernize operations, improve service delivery, and transform citizen experience. Whether through intelligent virtual assistants, automated insights, or faster access to institutional knowledge, generative AI is emerging as a strategic enabler of digital transformation. The true value of these AI-powered solutions emerges when connected to the rich enterprise data already housed in data warehouses within organizations’ AWS environments.
Although generative AI presents significant opportunities, integrating it with structured data remains a major hurdle. Data warehouses and relational databases within AWS—such as Amazon Redshift and Amazon Relational Database Service (Amazon RDS) for PostgreSQL—aren’t inherently accessible to most generative AI applications in AWS GovCloud (US). This limitation not only hampers innovation, but also forces organizations to duplicate data—which can lead to inefficiencies and increased costs. As public sector organizations strive to take advantage of their existing enterprise data while building innovative generative AI applications using Amazon Bedrock, a solution that bridges this gap becomes essential. By addressing this challenge, public sector organizations can unlock the full potential of their enterprise data, accelerate generative AI, and deliver more intelligent, data-driven services to citizens. What once required hours of data analysis can now be accomplished in minutes, allowing organizations to derive insights from their enterprise data using natural language queries.
In this blog post, we will demonstrate how public sector organizations can overcome the challenges that emerge when integrating Amazon Redshift and other AWS relational databases with Amazon Bedrock. You’ll learn how to utilize enterprise data to generate AI-powered analytical insights by using natural language queries through Amazon Bedrock Agents and Amazon Bedrock Knowledge Bases. This custom solution enables seamless connectivity between your structured data sources and generative AI applications, eliminating the need for data duplication and significantly reducing development effort. By the end of this blog post, you’ll understand how to implement this solution and discover how public sector organizations can harness their enterprise data for more accurate, comprehensive, and powerful generative AI applications.
What you’ll accomplish:
By following the steps discussed in this blog post, you will:
- Build a bridge between Amazon Redshift and Amazon Bedrock in the AWS GovCloud (US).
- Enable natural language queries against your structured enterprise data.
- Create an Amazon Bedrock multi-agent framework that converts questions to SQL and execute them automatically.
- Deploy a scalable solution that can extend to other AWS relations databases.
Prerequisites
You will need the following prerequisites to get started with the implementation of the solution discussed in this post:
- An AWS account with AWS Identity and Access Management (IAM) permissions to the required resources mentioned in this post .
- Familiarity with Amazon Bedrock and foundation models (FMs)
- Access to Amazon Bedrock models for Anthropic’s Claude Sonnet 3.5 or higher and Amazon Titan Text Embeddings V2. Note that, to enable model access in AWS GovCloud (US), you might need to use your associated standard AWS account to establish a model access agreement.
- Access to an Amazon Redshift database and Amazon Simple Storage Service (Amazon S3)
Solution overview
You can build and run this solution by following the steps described in this section.
Build a knowledge base with proprietary data
- Build an Amazon Bedrock knowledge base with an Amazon Simple Storage Service (Amazon S3) bucket as the source to store database schema files. Amazon Bedrock knowledge base serves as the reference for discovering tables definitions and data relationships, enabling conversion of natural language into SQL queries.
- Amazon Bedrock facilitates the use of vector embeddings, which are numerical representation of data that encapsulates its semantic meaning. Use the Amazon OpenSearch service to store vector embeddings generated from schema file chunks, which converts them to text embeddings using foundation models like Amazon Titan Text Embeddings V2.
Use a Bedrock multi-agent framework to invoke models
Amazon Bedrock multi-agent collaboration empowers you to orchestrate multiple AI agents working together on complex tasks. This feature allows for the creation of specialized agents that handle different aspects of a process, coordinated by a supervisor agent that breaks down requests, delegates tasks, and consolidates outputs. Each agent in the framework, including the supervisor agent, has full access to Amazon Bedrock agent’s capabilities, including tools, action groups, knowledge bases, and guardrails.
Execute tasks using Amazon Bedrock agent action groups
Amazon Bedrock agent action groups serve as the bridge between your AI agents and your data infrastructure.
- Define the AWS Lambda functions to establish connections with your database such as Amazon Redshift.
- Execute generated SQL queries on the database through these AWS Lambda functions.
- Process and return the query results to the agent framework.
The following diagram illustrates the solution architecture.
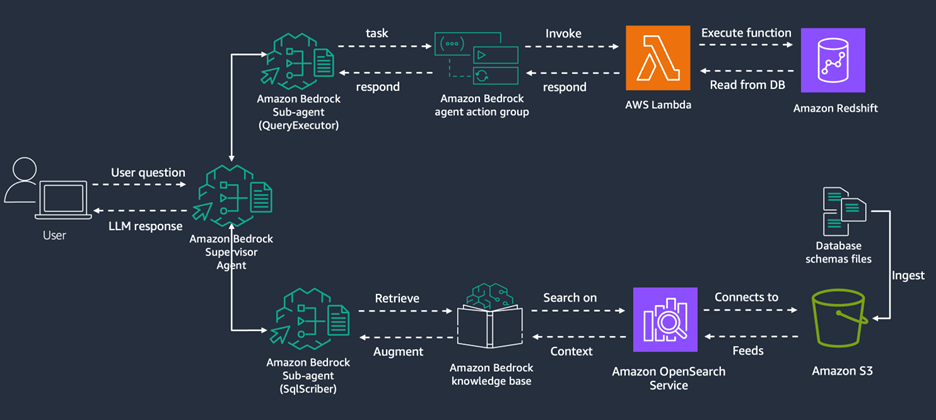
Figure 1: High-level architecture diagram of the solution
Solution walkthrough
Build your knowledge base with proprietary data
To implement the solution, we use a sample financial dataset that is for demonstration purposes only. You can use the same approach to your specific use case. Download database DDL scripts and sample financial dataset and unzip the zip folder.
Create an S3 bucket and upload the downloaded files to Amazon S3 bucket by organizing into separate folders. Upload unzipped sample financial dataset (.csv) files under the financial-data-set folder and DDL scripts (.sql) files under the ddls folder.
Note: when dealing with your enterprise data, it is recommended to modify your database schema definition files to:
- Remove database view definitions, if any, to avoid column name conflict
- Add a description against the column name, to minimize hallucination from model responses.
Run the DDL scripts (.sql file) to create sample financial tables on Amazon Redshift using Amazon Redshift Query Editor V2. Load the sample financial dataset to the newly created tables on Amazon Redshift using following COPY command statements. Replace <<your_s3_bucket>> with the name of your S3 bucket and <<redshift_IAM_role_ARN>> with your Amazon Redshift IAM role ARN and <<your_region>> with your AWS region. Make sure redshift_IAM_role has appropriate S3 permissions to read sample financial dataset from the bucket.
Create an Amazon Bedrock knowledge base with vector store. Associate your S3 bucket to the knowledge base pointing to 's3://<<your_s3_bucket>>/ddls/' folder. Replace <<your_s3_bucket>> with your S3 bucket. Choose Amazon Titan Text Embeddings V2 as embeddings model and Amazon OpenSearch Serverless service as the vector store. After successful creation, sync the S3 bucket with your knowledge base so the data can be queried.
Use an Amazon Bedrock multi-agent framework to invoke models
In this solution, we implemented a three-agent architecture consisting of one supervisor agent and two collaborative agents.
Create three Amazon bedrock agents and designate each agent to perform specific tasks:
- SqlScriber agent to convert the user’s natural language questions to SQL queries. This agent requires knowledge of database schemas to generate accurate SQL queries, which can be provided by associating a knowledge base containing schema information.
- QueryExecutor agent to execute generated SQL queries on the target database. This agent performs SQL execution action, requiring a defined action group.
- AgentSupervisor is a supervisor agent that serves as the orchestration hub for user interactions, breaking down complex requests into subtasks, delegating work to appropriate specialized agents, and consolidating outputs into coherent, unified responses. To configure an agent as a supervisor agent, enable “supervisor” collaboration mode within the “multi-agent collaboration” configuration.
Specify instructions for each agent as below:
SqlScriber agent – Responsible for understanding table schemas and relations to convert natural language to SQL. Add these instructions for the SqlScriber agent:
Add your knowledge base to the agent and specify following instructions for knowledge base instructions for agent:
This knowledge base contains database schema files
QueryExecutor agent – Responsible for executing generated sql on a structured data source such as Amazon Redshift. Add these instructions for the QueryExecutor agent:
Add your action group with action group type“define with function details” and action group invocation to
“Quick create a new Lambda function – recommended”. You will update the newly generated Lambda function with the sample code provided in the later section of this blog. Add the parameter to the action group with the following details:
| Parameter | Description | Type | Required |
| Sql | Agent generated SQL query | String | False |
The AgentSupervisor agent needs to know how you want it to handle information across multiple collaborator agents. Turn on multi-agent collaboration on the supervisor agent and add the SqlScriber agent and QueryExecutor agent as collaborator agents. For collaborator instructions, use same agent instructions.
Execute tasks using Amazon Bedrock agent action groups
Now it’s time to execute generate SQL queries on Amazon Redshift. Before the agent takes action on the Amazon Redshift database, configure secure way to access database credentials and prepare Lambda to access database.
- Retrieve the Amazon Redshift database credentials from AWS Secrets Manager and specify as an environment variable in the Lambda function. For details on creating a secret, visit Creating a secret for database connection credentials. The following screenshot shows the AWS Secrets Manager:
- Edit the AWS Lambda function that was created during “QueryExecutor agent” creation by adding database secret as an environment variable. And replace AWS Lambda code with the sample python code below. The following screenshot shows the AWS Lambda environment variables:
AWS Lambda function sample code:
Now open supervisor agent to ask natural language queries to generate AI-powered analytics on your enterprise data.
Enable and monitor Amazon Bedrock model invocation logs
Amazon Bedrock model invocation logs provide detailed visibility into the inputs and outputs of foundation model API calls, which can be invaluable for detecting potential prompt injection attempts. By analyzing the full request and response data in these logs, you can identify suspicious or unexpected prompts that may be attempting to manipulate or override the model’s behavior. To detect these attempts, you could analyze Amazon Bedrock model invocation logs for sudden changes in input patterns, unexpected content in prompts, or anomalous increases in token usage. To detect anomalous increases in token usage, you can track metrics like input token counts over time. You could also set up automated monitoring to flag inputs that contain certain keywords or patterns associated with prompt injection techniques.
For more details, see the AWS documentation topic Monitor model invocation using CloudWatch Logs.
Cleanup
To avoid incurring future charges, delete AWS resources that are provisioned to implement this solution.
Conclusion
The integration of Amazon Bedrock with enterprise data warehouses represents a transformative opportunity for public sector organizations. The key benefits of this solution include:
- Enhanced decision-making capabilities – Enabling organizations to generate AI-powered insights directly from enterprise structured data without data duplication or complex integrations.
- Simplified enterprise data integration – Supporting growing data volumes, giving you the capability to accommodate demand by adding more data sources
- Maintaining security and compliance – Adhering to existing data governance requirements while enabling AI-powered analytics in secure AWS GovCloud (US) environments
In this blog post, we demonstrated how integrating Amazon Bedrock with Amazon Redshift unlocks enterprise data through natural language query interactions. This solution provides a scalable foundation that extends to other structured data sources, making it particularly valuable for the public sector and federal organizations operating on AWS GovCloud (US).
Getting started
Ready to begin your generative AI applications development journey on AWS? Here are some resources to help you get started: