AWS Storage Blog
How GE’s Avio Aero deploys Microsoft SharePoint using AWS Storage solutions
SharePoint is the source of truth for the unstructured data needs of many businesses. Keeping it available, while offering the best performance possible at the most cost-effective price, is critical to ensuring that different parts of an organization can work together. At GE’s Avio Aero, our SharePoint deployment hosts business-critical data from our Finance, Sourcing, and Engineering departments— this means it must be highly available from top to bottom.
In this blog post, we discuss how my company used Amazon FSx for Windows File Server (Amazon FSx) as a high-performance storage repository for our SharePoint needs. Using AWS Storage solutions enabled us to deploy a highly available and cost optimized SharePoint. But first, who are we?
Who we are and where we are going
Avio Aero is a GE aviation business that operates in the design, manufacture, and maintenance of civil and military aeronautics subsystems and systems. Avio Aero offers innovative technological solutions that allow our customers to respond to the continuous changes in the market, such as carbon-neutral aviation. Today 80% of all the commercial flights are equipped with Avio Aero parts.
Redeploying SharePoint on AWS was another step along the road in our journey to the cloud. We have a cloud-first strategy, and have migrated several critical workloads into AWS over the years. In this case the decision was between the installation of new servers, databases, and storage on premises, or deploying that infrastructure entirely as code on AWS.
SharePoint deployment with Amazon FSx for Windows File Server
Amazon FSx for Windows File Server provides high availability, automatic failover, and failback through the use of Server Message Block (SMB) continuous availability and synchronous replication. The built-in synchronous replication, across two Availability Zones, delivers shared file storage that can be put into production in just a few clicks. Scaling the capacity and performance of file shares on this storage can be done in seconds, while volume level backups and file system maintenance can be automated. This combination provides a powerful storage foundation on which we built a modern SharePoint deployment.
While volume level backups are available as a feature, our database recovery model calls for the use of full and differential database backups. To support that, we integrated Amazon S3 into the solution. We use S3 for durable storage of inactive SharePoint data, and also as a backup target for our Microsoft SQL Server database backups.
This combination of AWS services allowed us not only to deliver the availability our users expect, but also to meet the Recovery Point Objectives (RPO) our business needs. But what is our business?
Breaking it down
As we considered our design, we had four main objectives:
- Set up a highly available SharePoint environment
- Focus on ease of management
- Minimize the total cost of the solution
- Store the data for the long term
To achieve these objectives, we:
- Set up a high available Microsoft SQL Server cluster
- Deployed highly available shared file storage using Amazon FSx
- Set up a highly available SharePoint deployment on AWS
- Connected Microsoft SQL Server and SharePoint tour Microsoft Active Directory domain in AWS
- Stored unstructured and database backup data in Amazon S3
- Created a backup strategy to meet our recovery needs
Creating a highly available Microsoft SQL Server cluster on AWS
Working with our AWS solutions architect Antonio Aga Rossi, we decided to implement SQL Server Always On Failover Cluster Instances (FCI). The FCI model delivers an RPO of zero and a Recovery Time Objective (RTO) of a few seconds, meeting the availability needs of our business. This design also facilitates the use of less expensive Standard Edition SQL Server licenses and protects the entire SQL infrastructure deployment, not just the database.
AWS Availability Zones are fully isolated partitions of AWS infrastructure. They are physically separated by a meaningful distance, but network performance is such that synchronous replication between them is supported. For the compute layer, we set up a cluster of two Microsoft Windows servers in two Availability Zones. We started from a hardened Windows baseline image to which we added the Microsoft SQL Server components. After we installed the database, we created a new baseline Amazon Machine Image (AMI). This provided us with the ability to deploy any number of server instances, running our configuration, at any time.
With the application layer configured, and the compute images ready to be launched on demand, we moved to solving the shared storage requirement. There were multiple options available for shared storage but the one that was the easiest to manage and fastest to deploy was Amazon FSx for Windows File Server.
Moving to fully managed shared storage
A Failover Cluster Instance design needs shared storage accessible to all of the cluster nodes. Knowing that Server Message Block (SMB) is supported as a transport protocol in FCI designs, we believed that Amazon FSx for Windows File Server could meet our availability needs with its support for continuously available shares.
Amazon FSx is an AWS Storage service that provides fully managed, reliable, and scalable file storage that is accessible over the SMB protocol. Two file system deployment types are supported: Single-AZ and Multi-AZ, and the file system supports both SSD and HDD storage.
Since we were looking to host a database, we went for a Multi-AZ option running on SSD storage. This combined high availability using synchronous replication, in an active/passive configuration, with SSD storage performance. Since the file system’s storage and throughput capacities can be scaled independently, Amazon FSx gave us the flexibility to achieve the right balance of cost and performance.
Since Amazon FSx is built on Windows Server, there was full support for Active Directory integration. This would have been a deal breaker when it came to ensuring this deployment would meet our security and authentication requirements. As we will discuss later in this blog, Active Directory support being built in made Active Directory integration a simple matter.
As mentioned earlier, the combination of SQL Server, FCIs, and the continuously available shares provided by Amazon FSx allowed us to lower licensing cost by avoiding Microsoft SQL enterprise licenses. While we lowered our costs, we were still able to deliver a highly available solution. This design also made our Microsoft SQL Server nodes more efficient in relation to the cost spent on transaction processing. The nodes no longer had to burn cycles on data replication — it is all handled now at the storage layer.
The implementation of our Microsoft SQL cluster looked like this:
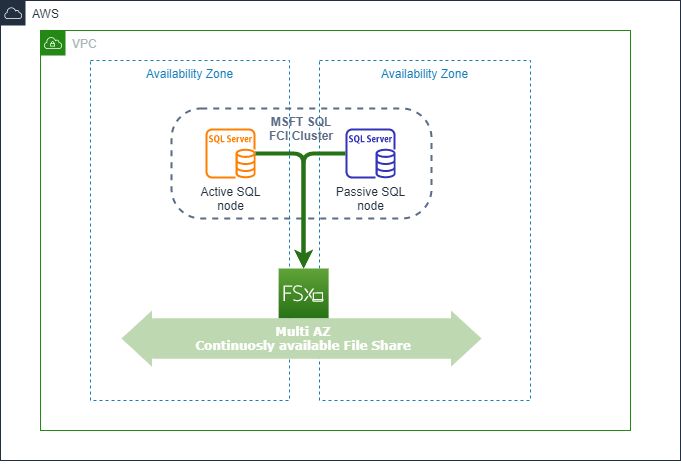
Figure 1: Microsoft SQL cluster based on Amazon FSx for Windows File Server
You can find more details on how to set up a SQL cluster with Amazon FSx for Windows File Server in this blog post.
Setting up a highly available SharePoint on AWS
Once the database was up and running, the SharePoint setup was straightforward. An Application Load Balancer was placed in front of two Amazon EC2 instances each running in different Availability Zones. These instances provided the web front end and caching layers of our installation. On the backend, we set up two additional EC2 instances, across the same two Availability Zones, to host the SharePoint application and its search feature. The Office Web Application, not being a mission critical component, was deployed in a single EC2 instance.
Having the various SharePoint components spread across Availability Zones allows us to have servers running in different locations many kilometers apart. When we tested the latency, we found it was within a two to four-msec range, which was acceptable for our needs.
At this point in the deployment, our architecture looked like this:

Figure 2: Microsoft SharePoint architecture
Connectivity and Active Directory permissions
For authentication and administration, Microsoft SharePoint, SQL Server, and Amazon FSx for Windows File Server require connectivity to an Active Directory. At GE, we do not extend our internal Active Directory to the cloud, instead we have an Active Directory exclusively for our cloud environment. A one-way trust between these Active Directory domains has allowed us to segregate all cloud resources into a separate domain but it still makes them available to the users of our on-premises directory.
Setting up this cloud.avio.net domain was easy. We spun up two Amazon EC2 instances and installed the Windows Domain Controllers and Active Directory integrated DNS. As per best practice, controllers were deployed on different Availability Zones to ensure service in case of an error or an outage.
With respect to connectivity, GE has multiple AWS Direct Connect links, which are dedicated private connections between our data centers and AWS. The main advantages are speed, reduced latency, and the links are for our use only. In Europe, we have two Direct Connect links and all traffic between AWS and GE run through these. Having connected to our Active Directory server in the cloud and made our SharePoint deployment available to our on-premises users through our Direct Connect links our architecture looked like this:
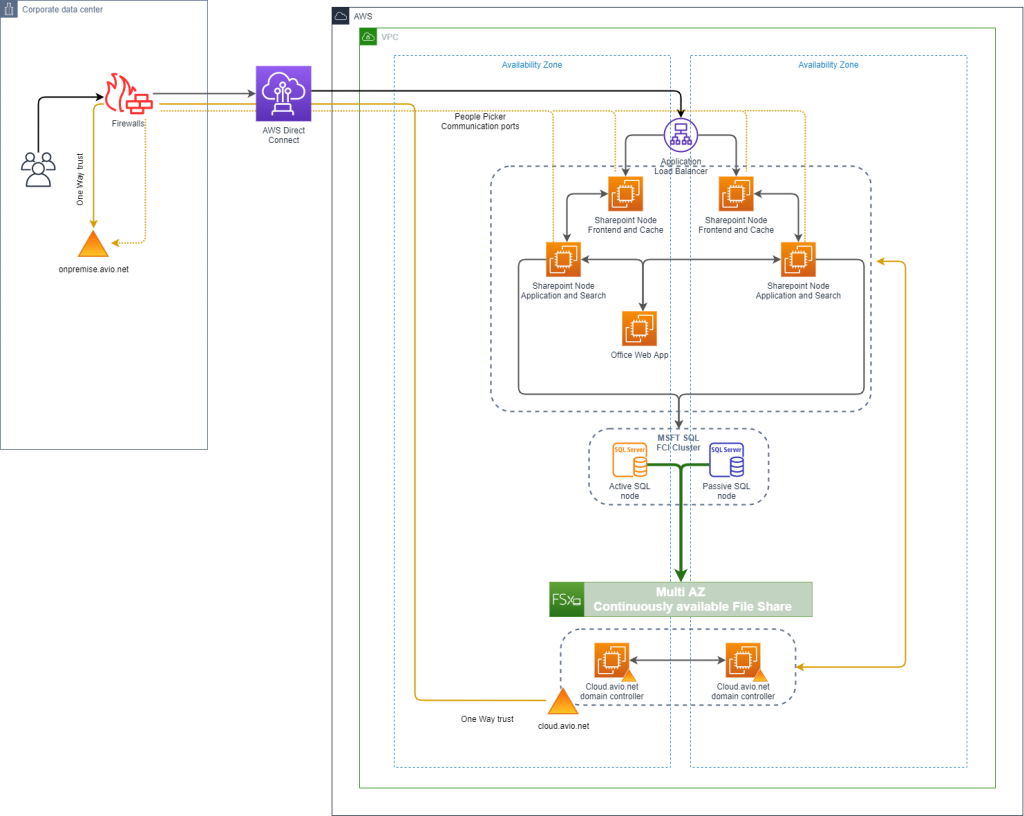
Figure 3: Connectivity and Active Directory integration
Moving document data from SQL to Amazon S3 with AWS Storage Gateway
With SharePoint now operational, highly available, and running fast, we started thinking about the future. Storing a lot of unstructured data inside of a SQL database over the long term is not a good idea. As the database grows larger database transactions will take more time and the majority of the data inside the database will be inactive.
All data has a lifecycle and while unstructured data may need to be retained for a long time, the chances are that after an initial flurry of activity, the data will not be accessed again. We decided to archive this cold data to Amazon S3. Amazon S3 has a number of low-cost storage classes and it offers intelligent lifecycle management. Once the data is placed in Amazon S3 the lifecycle rules will ensure it is placed on a class of storage that meets its availability, durability, and access time needs.
Our internal DevOps team wrote a script to extract data to be archived from the database every 24 hours. The script then writes that data to an SMB share provided by AWS Storage Gateway. We deployed an Amazon FSx File Gateway, creating an SMB share that is backed by Amazon S3 on AWS.
Having moved all inactive data out of the database, we needed something that people could use to retrieve that data if it was required. Since our DevOps teams love serverless technologies, they created a simple data retrieval application built with AWS Lambda and Amazon API Gateway. This application provides a web interface where users can download their requested files out of Amazon S3.
Backup using native tools and AWS Storage Gateway
Having deployed our application, we needed to protect it. For the SQL database backups, we used the approach outlined in this blog post on SQL backups. Native tools in SQL Server producing backup files that are stored on an AWS Storage File Gateway SMB share.
Our corporate compliance requirement states that we store backup data for up to five years. Amazon S3 Lifecycle automatically moves our data older than 30 days to Amazon S3 Glacier. Amazon S3 Glacier and Amazon S3 Glacier Deep Archive storage classes are ideal for long term data retention at an extremely low cost.
All EC2 server instances in this deployment use Amazon EBS volumes for storage. Here, we used native EBS snapshot functionality to take incremental snapshots for fast rollback in case a recovery was required. Completing our design, from load balancers to Lambda, the deployed architecture now looks like this:

Figure 4: Final architecture
Conclusion
In this post, we showed how we were able to install a highly available Microsoft SharePoint environment on AWS. We optimized our costs, thanks to Amazon FSx for Windows File Server, and kept our Microsoft SQL database optimized for the longer term by moving unstructured data and backups to the appropriate Amazon S3 storage classes for our needs.
Managing storage on premises has always been challenging for us with applications devouring even more storage space year after year. Things have not always been as flexible or as agile as we have been aiming for. With these AWS Storage solutions, flexibility and business agility have been among the top benefits we have gained. We recently moved an additional 700 GB of data into this SharePoint, and it took just a few clicks to resize our Amazon FSx file shares to meet that demand. Knowing that we can easily scale up and scale out without having to worry about storage or compute provisioning is a huge benefit. For backups and multi-year retention, Amazon S3 being a global-scale, object storage system, eliminated the challenge we faced in keeping years of backups to meet our legal requirements. Life is easier now.
The AWS Storage portfolio consists of many other great services and we have put many of them to use. Aside from the project we discussed in this blog, we moved all our on-premises backups to Amazon S3, shifted our Splunk infrastructure to AWS, and replaced our SharePoint workflows with a combination of AWS Lambda and Amazon DynamoDB.
Without AWS Managed Services, we would not have reached our goal of providing the best experience for our users. That is the most important result for us. Our success on this project and with the other projects is a credit to the collaboration between our internal teams and various teams at AWS.
Thank you for reading. If you have any comments or questions, please don’t hesitate to leave them in the comment.