Amazon Glue 是一项无服务器数据集成服务,它简化了发现、准备和合并数据以进行分析、机器学习和应用程序开发的工作。Glue 为您提供可视化界面和基于代码的界面来简化数据集成。用户使用Glue 数据目录可以轻松找到并访问数据。数据工程师和 ETL(即提取、转换和加载)开发人员只需在 Amazon Glue Studio 中点击几次,便能够以可视化的方式创建、运行和监控 ETL 工作流程。
使用Glue可以通过配置向导界面可以自动生成代码加载多种数据源的数据到S3、Redshift等目标存储,Glue作业的配置界面可以帮你自动的生成数据抽取代码,无需修改代码即可完成数据从关系型数据库抽取到S3对象存储或Redshift,完成数据入湖、入仓的动作,大大提升开发效率。在实际的项目开发过程中,我们不仅需要全表的数据抽取,也需要实现增量的数据抽取,如:仅抽取新增的数据而非每次都全表全量数据抽取;源数据库表存在更新,需要在目标存储实现UPSERT加载。本文将讲解利用Glue实现从关系型数据库增量抽取数据的实现方式。
部署方案
在一般的业务场景中,应用程序写入线上业务库,为了对数据进行OLAP分析,会将业务库中的数据按需增量导入到S3或者Redshift中以对接BI工具和提供跟运营人员进行数据的统计分析。本文使用Glue作为ETL工具,Glue可以访问VPC内部的数据库服务器,同时也可以通过DX专线或者SD-Wan等链路访问IDC的数据库,在混合架构组网的环境下,可以通过Glue来构建统一的数据处理分析平台。在大型企业用户,多部门,多团队的情况下Glue的Serverless特性可以方便的解决ETL处理容量的问题,运维的问题及安全的问题。

前提条件
本提前在环境中准备RDS for MySQL数据库实例、,Redshift数据库实例和Amazon S3存储桶,本文对于数据库的创建部分内容不做详细描述。
数据准备
我们在MySQL中模拟创建四张数据表,前三张表需要增量导入到Amazon S3数据湖中,第四张表源表数据会有更新,需要UPSERT导入到Amazon Redshift中,针对不同的需求和源表的结构,我们在Glue中采取不同的增量加载方式。
第一张表USERINFO有自增主键,并且主键是连续增长的数字,例如ID
| ID |
USERNAME |
AGE |
COUNTRY |
REGISTERDAY |
| 1 |
Tom |
20 |
China |
2020-11-03 |
| 2 |
Jerry |
15 |
China |
2020-10-03 |
| 3 |
Bob |
18 |
China |
2020-11-03 |
| 4 |
Quan |
18 |
China |
2020-11-04 |
| 5 |
XiaoLiu |
20 |
China |
2020-11-05 |
USERINFO 建表语句如下
create table USERINFO
(
ID INT not null auto_increment,
USERNAME varchar(255),
AGE int,
COUNTRY varchar(255),
REGISTERDAY date not null,
primary key (ID)
);
第二张表 ORDERINFO 没有自增字段,有ORDERID整数主键列,但列值存在不连续有间隔的情况
| ORDERID |
ORDERDETAIL |
CREATETIMESTAMP |
| 1 |
sam’s order |
2021-11-03 07:49:38 |
| 3 |
tom’s order |
2021-11-03 07:49:38 |
| 5 |
jerry’s order |
2021-11-03 07:49:38 |
| 6 |
quan’s order |
2021-11-03 07:49:38 |
| 9 |
bob’s order |
2021-11-03 07:49:38 |
ORDERINFO建表语句如下
create table ORDERINFO
(
ORDERID int not null,
ORDERDETAIL varchar(255),
CREATETIMESTAMP timestamp default CURRENT_TIMESTAMP
);
第三张表PAYLOG既没有自增主键,也没有其它递增字段,但表设计有时间字段。
| TRADE_NO |
ORDER_ID |
AMOUNT |
PAYMENT_DATE |
| a4edb81a-3825-29f2-d390-3c7070f42fda |
1 |
5 |
2021-10-17 |
| ef451a58-72c2-c3e6-e3cf-95855ec167c1 |
5 |
10 |
2021-10-17 |
| 21509028-6a7c-4480-3894-9381b61abdf2 |
3 |
3 |
2021-10-18 |
| 2d642018-3511-fc8d-c915-e9dc8c7c6154 |
2 |
2 |
2021-10-18 |
| f4fbe988-0596-78d5-5cd3-0f85ad984b87 |
4 |
3 |
2021-10-19 |
PAYLOG建表语句如下
create table PAYLOG
(
TRADE_NO varchar(255),
ORDER_ID int,
AMOUNT int,
PAYMENT_DATE date
);
第四张表ITEM,源表的PRICE字段会进行调整变更。
| ITEM_ID |
ITEM_NAME |
PRICE |
UPDATE_DATE |
| 1 |
book01 |
3 |
2021-10-17 |
| 2 |
book02 |
2 |
2021-10-17 |
| 5 |
book05 |
2 |
2021-10-18 |
| 4 |
book04 |
5 |
2021-10-18 |
| 8 |
book08 |
10 |
2021-10-19 |
ITEM建表语句如下
create table ITEM
(
ITEM_ID int,
ITEM_NAME varchar(255),
PRICE int,
UPDATE_DATE date
);
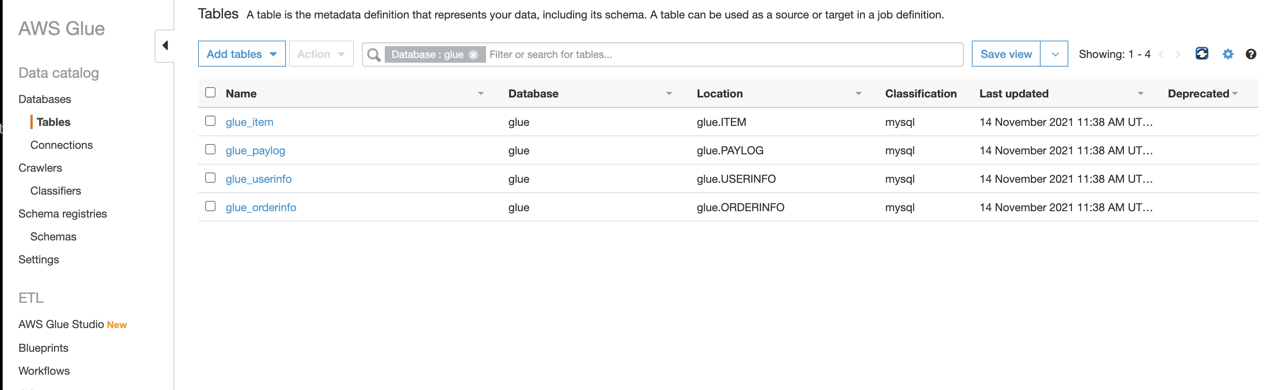
在MySQL中创建完表和插入数据后,在Glue中新建连接和爬网程序,将MySQL中的表同步至Glue的Catalog中。

增量加载操作
利用Glue默认作业书签方式加载USERINFO表
作业书签介绍
Amazon Glue 通过保存作业运行的状态信息来跟踪上次运行 ETL 作业期间已处理的数据。此持久状态信息称为作业书签。作业书签可帮助 Amazon Glue 维护状态信息,并可防止重新处理旧数据。有了作业书签,您可以在按照计划的时间间隔重新运行时处理新数据。作业书签包含作业的各种元素的状态,如源、转换和目标。例如,您的 ETL 作业可能会读取 Amazon S3 文件中的新分区。Amazon Glue跟踪作业已成功处理哪些分区,以防止作业的目标数据存储中出现重复处理和重复数据。Glue的作业书签支持JDBC及S3模式。下面介绍JDBC的实现方式。
实现方法
在数据抽取的Job作业的高级属性设置里面启用作业书签配置即可实现增量抽取,要求源表存在按顺序递增或递减的数字主键,例如USERINFO表中的ID,Glue会自动识别表中的主键字段作为书签键。

在配置完成Job作业后可以执行Job作业进行数据抽取,运行的时候可以检查作业书签是否在启用状态

当我们多次运行作业的时候,Glue会根据书签记录的上次运行时处理的位置增量加载数据。
Glue自动生成处理脚本如下
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "glue", table_name = "glue_userinfo", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "glue", table_name = "glue_userinfo", transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("country", "string", "country", "string"), ("registerday", "date", "registerday", "date"), ("username", "string", "username", "string"), ("id", "int", "id", "int"), ("age", "int", "age", "int")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("country", "string", "country", "string"), ("registerday", "date", "registerday", "date"), ("username", "string", "username", "string"), ("id", "int", "id", "int"), ("age", "int", "age", "int")], transformation_ctx = "applymapping1")
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://quandata1/glue/bookmark/userinfo/"}, format = "csv", transformation_ctx = "datasink2"]
## @return: datasink2
## @inputs: [frame = applymapping1]
datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": "s3://quandata1/glue/bookmark/userinfo/"}, format = "csv", transformation_ctx = "datasink2")
job.commit()
利用Glue作业书签并指定书签字段的方式增量加载ORDERINFO表
当字段的数值为非连续的唯一值(字段为主键或非主键均可)的时候,我们不但需要在Glue中启用书签功能,还需要在脚本中指定具体字段将ORDERID字段指定为书签字段,详细代码如下
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "glue", table_name = "glue_orderinfo", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "glue", table_name = "glue_orderinfo", transformation_ctx = "datasource0",additional_options = {"jobBookmarkKeys":["ORDERID"],"jobBookmarkKeysSortOrder":"asc"})
## @type: ApplyMapping
## @args: [mapping = [("createtimestamp", "timestamp", "createtimestamp", "timestamp"), ("orderid", "int", "orderid", "int"), ("orderdetail", "string", "orderdetail", "string")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("createtimestamp", "timestamp", "createtimestamp", "timestamp"), ("orderid", "int", "orderid", "int"), ("orderdetail", "string", "orderdetail", "string")], transformation_ctx = "applymapping1")
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://quandata1/glue/bookmark/orderinfo/"}, format = "csv", transformation_ctx = "datasink2"]
## @return: datasink2
## @inputs: [frame = applymapping1]
datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": "s3://quandata1/glue/bookmark/orderinfo/"}, format = "csv", transformation_ctx = "datasink2")
job.commit()
利用Glue执行SQL过滤条件的方式增量加载PAYLOG表
当字段中没有递增主键或者唯一值数字字段时,我们可以根据日期等过滤条件增量提取数据,例如表中包含DATE字段,或者在摄入数据的时候,自动创建update_date字段,例如如下脚本通过每天过滤昨天的增量数据实现数据的增量加载。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from datetime import datetime, date, timedelta
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "glue", table_name = "glue_paylog", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
#today=str(date.today())
#yesterday = str(date.today() + timedelta(days = -1))
yesterday = '2021-10-17'
#print(today)
#print(yesterday)
#add_info= {"hashexpression":"payment_date < '2021-10-19' AND payment_date","hashpartitions":"10"}
add_info= {"hashexpression":"payment_date = '" + yesterday + "' AND payment_date","hashpartitions":"10"}
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "glue", table_name = "glue_paylog", additional_options = add_info, transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("order_id", "int", "order_id", "int"), ("amount", "int", "amount", "int"), ("trade_no", "string", "trade_no", "string"), ("payment_date", "date", "payment_date", "date")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("order_id", "int", "order_id", "int"), ("amount", "int", "amount", "int"), ("trade_no", "string", "trade_no", "string"), ("payment_date", "date", "payment_date", "date")], transformation_ctx = "applymapping1")
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://quandata1/glue/bookmark/paylog/"}, format = "csv", transformation_ctx = "datasink2"]
## @return: datasink2
## @inputs: [frame = applymapping1]
datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": "s3://quandata1/glue/bookmark/paylog/"}, format = "csv", transformation_ctx = "datasink2")
job.commit()
实际应用过程中,我们可以传递时间参数到作业脚本中,根据时间参数增量加载数据,也可以通过脚本获取前一天的日期,然后每天增量加载前一天的数据。
利用Glue执行Merge Redshift表SQL的方式增量更新加载ITEM表
有时候源表的数据会存在修改的情况,比如商品价格调整等,这个时候我们希望将变更的数据也可以增量的同步到后端存储中,如果后端存储是S3,默认是不支持UPSERT的数据摄入,需要借助Apache Hudi组件。如果后端存储是Redshift,Redshift默认也无法直接进行UPSERT操作,我们需要利用SQL Merge Stage表的方式实现UPSERT的语义。
增量更新ITEM表的作业脚本参考如下:
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [TempDir, JOB_NAME]
args = getResolvedOptions(sys.argv, ['TempDir','JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "glue", table_name = "glue_item", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
yesterday = '2021-10-18'
add_info= {"hashexpression":"update_date = '" + yesterday + "' AND update_date","hashpartitions":"10"}
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "glue", table_name = "glue_item", additional_options = add_info, transformation_ctx = "datasource0")
## @type: ApplyMapping
## @args: [mapping = [("price", "int", "price", "int"), ("update_date", "date", "update_date", "date"), ("item_id", "int", "item_id", "int"), ("item_name", "string", "item_name", "string")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = datasource0]
applymapping1 = ApplyMapping.apply(frame = datasource0, mappings = [("price", "int", "price", "int"), ("update_date", "date", "update_date", "date"), ("item_id", "int", "item_id", "int"), ("item_name", "string", "item_name", "string")], transformation_ctx = "applymapping1")
## @type: ResolveChoice
## @args: [choice = "make_cols", transformation_ctx = "resolvechoice2"]
## @return: resolvechoice2
## @inputs: [frame = applymapping1]
resolvechoice2 = ResolveChoice.apply(frame = applymapping1, choice = "make_cols", transformation_ctx = "resolvechoice2")
## @type: DropNullFields
## @args: [transformation_ctx = "dropnullfields3"]
## @return: dropnullfields3
## @inputs: [frame = resolvechoice2]
dropnullfields3 = DropNullFields.apply(frame = resolvechoice2, transformation_ctx = "dropnullfields3")
## @type: DataSink
## @args: [catalog_connection = "myredshift", connection_options = {"dbtable": "glue_item", "database": "test"}, redshift_tmp_dir = TempDir, transformation_ctx = "datasink4"]
## @return: datasink4
## @inputs: [frame = dropnullfields3]
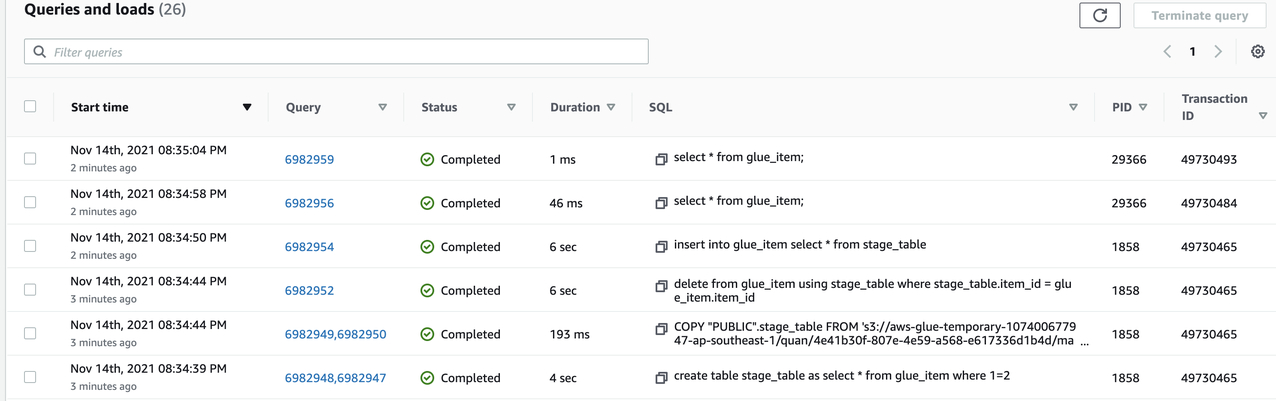
post_query="begin;delete from glue_item using stage_table where stage_table.item_id = glue_item.item_id ; insert into glue_item select * from stage_table; drop table stage_table; end;"
datasink4 = glueContext.write_dynamic_frame.from_jdbc_conf(frame = dropnullfields3, catalog_connection = "myredshift", connection_options = {"preactions":"drop table if exists stage_table;create table stage_table as select * from glue_item where 1=2;", "dbtable": "stage_table", "database": "test","postactions":post_query}, redshift_tmp_dir = args["TempDir"], transformation_ctx = "datasink4")
job.commit()
我们可以看到在Redshift集群中,Glue通过SQL语句实现数据的UPSERT插入

任务的启动触发
在创建完作业任务后,我们可以在Glue上配置任务的执行调度,在触发器菜单新建触发器实现任务的定期调度执行。


通过添加新建的作业


将作业书签设置为启用

创建完成触发器之后启用触发器,Glue就可以定时执行任务完成数据增量抽取。
除了使用触发器运行作业外,我们也可以通过Glue API或者AWS Cli的方式启动作业,我们可以在启动作业的时候传递外部参数到Glue脚本中,例如将时间参数传递给脚本,脚本内根据时间参数动态的执行数据过滤。
$ aws glue start-job-run --job-name "jobname" --arguments='--filterdate="2021-10-11"'
过滤条件我们可以通过Glue Job的参数传递到作业脚本中,在脚本中获取外部传递的参数然后执行过滤匹配
args = getResolvedOptions(sys.argv, ['JOB_NAME','filterdate'])
filterdate=args['filterdate']
总结
本文讨论利用Glue进行增量数据的离线加载,需要源数据表具备特定条件,当主键满足递增或递减数字值的时候我们使用Glue内置的作业书签功能;当表字段满足日期及时间字段,我们使用SQL的Where条件进行过滤增量抽取;如果需要更新数据的同步,我们利用Glue脚本在目标库执行Merge语句实现UPSERT语义;如果源数据库表无法满足上述同步对应的条件时,可以利用Glue进行全量数据加载或者利用Glue streaming job流式处理源数据CDC日志的方式,具体可以参考官方文档。
参考链接
https://docs.amazonaws.cn/glue/latest/dg/monitor-continuations.html
https://aws.amazon.com/blogs/big-data/how-to-access-and-analyze-on-premises-data-stores-using-aws-glue/
https://aws.amazon.com/cn/blogs/china/quickly-build-an-aws-glue-based-extracting-cross-region-mysql-8-data-pipeline/
https://docs.aws.amazon.com/redshift/latest/dg/merge-examples.html
本篇作者