





在本模块中,您将创建 Amazon Kinesis Data Analytics 应用程序,以实时聚合独角兽队列中的传感器数据。该应用程序将从 Amazon Kinesis 流中读取数据,计算当前 Wild Ryde 上每个独角兽的总行驶距离、最小和最大生命值及魔法值,并且每分钟将这些汇总的统计数据输出到 Amazon Kinesis 流中。
本模块的架构包括 Amazon Kinesis Data Analytics 应用程序、源 Amazon Kinesis 流和目标 Amazon Kinesis Streams,以及生产者和使用者命令行
Amazon Kinesis Data Analytics 应用程序处理我们在上一个模块中创建的源 Amazon Kinesis 流中的数据,并且每分钟对此类数据进行聚合。应用程序每分钟都会发送数据,其中包括上一分钟的总行驶距离,以及车队中每个独角兽的生命值和魔法值的最小及最大读数。这些数据点将发送到目标 Amazon Kinesis 流,由系统中的其他组件进行处理。
完成模块所需时间:20 分钟
使用的服务:
• Amazon Kinesis Data Streams
• Amazon Kinesis Data Analytics
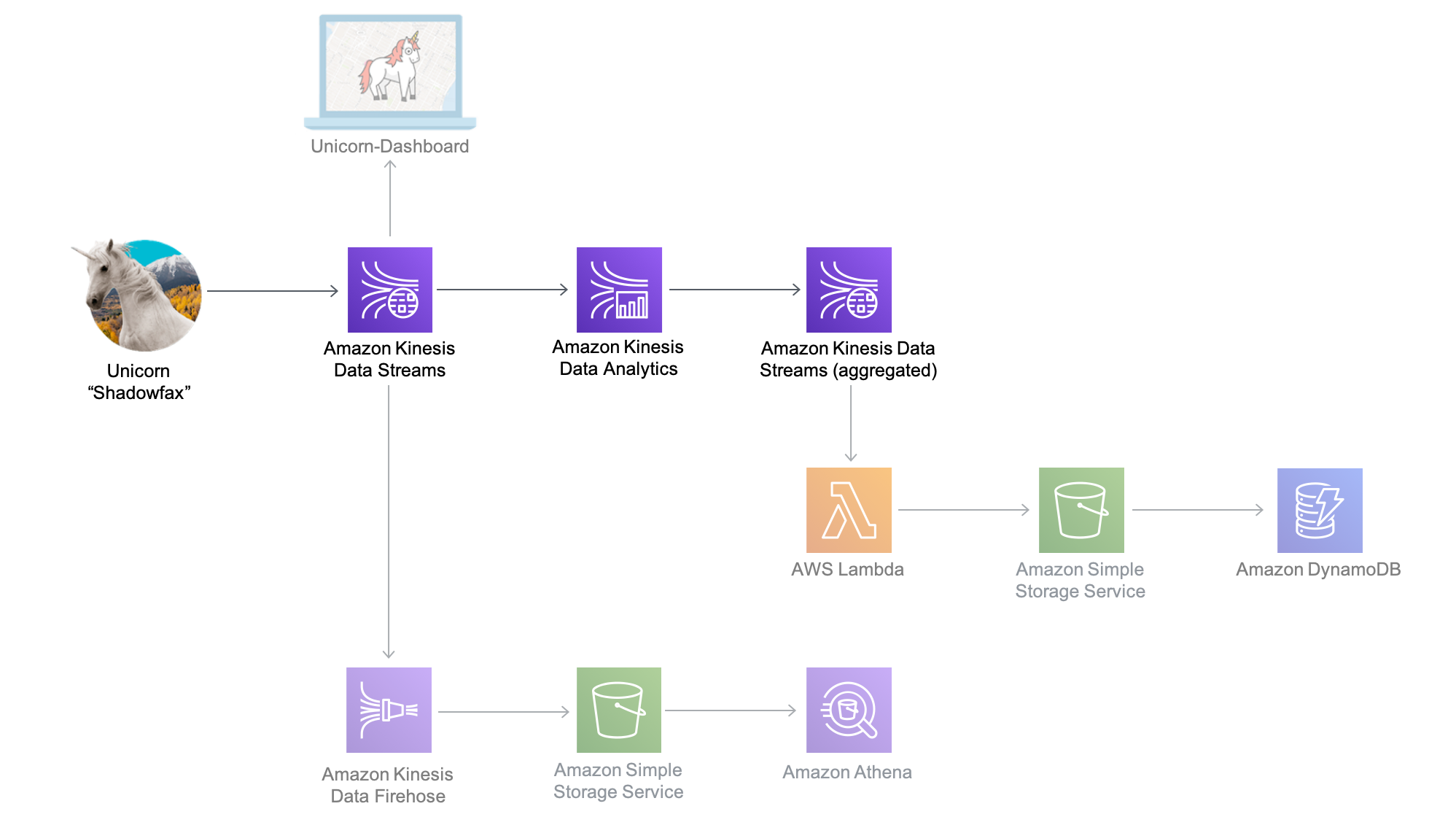
-
第 1 步:创建 Amazon Kinesis 流
使用 Amazon Kinesis Data Streams 控制台新建名为 wildrydes-summary 且具有 1 个分片的流。
a.转至 AWS 管理控制台,单击服务,然后选择“分析”下的 Kinesis。
b.如果屏幕上出现介绍性提示,请选择开始使用。
c.选择创建数据流。
d.在 Kinesis 流名称处输入 wildrydes-summary,在分片数量中输入 1,然后选择创建 Kinesis 流。
e.您的 Kinesis 流将在 60 秒内处于激活状态,并可用于存储实时流式数据。
-
第 2 步:创建 Amazon Kinesis Data Analytics 应用程序
构建一个 Amazon Kinesis Data Analytics 应用程序,它可从在上一个模块中构建的 wildrydes 流中读取数据,并且每分钟发送一个具有以下属性的 JSON 对象:
名称 独角兽名称 StatusTime Amazon Kinesis Data Analytics 提供的 ROWTIME Distance 独角兽行驶的总距离 MinMagicPoints MagicPoints 属性的最小 数据点MaxMagicPoints MagicPooints 属性的最大 数据点MinHealthPoints HealthPoints 属性的最小数据点 MaxHealthPoints HealthPoints 属性的 最大 数据点a.切换至已打开 Cloud9 环境的选项卡。
b.运行生产者,开始向流发送传感器数据。
./producer
在构建应用程序时主动生成传感器数据,可使 Amazon Kinesis Data Analytics 自动检测我们的 schema。
c.转至 AWS 管理控制台,单击服务,然后选择“分析”下的 Kinesis。
d.选择创建分析应用程序。
e.在应用程序名称处输入 wildrydes,然后选择创建应用程序。
f.选择连接流数据。
g.从 Kinesis 流中选择 wildrydes。
h.向下滚动并单击发现 schema,稍等片刻,确保自动发现正确的 schema。
确保自动发现的 schema 包括:
列 数据类型 Distance DOUBLE HealthPoints INTERGER Latitude DOUBLE Longitude DOUBLE MagicPoints INTEGER Name VARCHAR(16) StatusTime TIMESTAMP i.选择保存并继续。
j.选择转至 SQL 编辑器。系统将打开一个交互式查询会话,在此处,我们可以基于实时 Amazon Kinesis 流构建查询。
k.选择是,启动应用程序。应用程序启动需要 30 至 90 秒的时间。
l.复制以下 SQL 查询语句并粘贴到 SQL 编辑器中:
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" ( "Name" VARCHAR(16), "StatusTime" TIMESTAMP, "Distance" SMALLINT, "MinMagicPoints" SMALLINT, "MaxMagicPoints" SMALLINT, "MinHealthPoints" SMALLINT, "MaxHealthPoints" SMALLINT ); CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM" SELECT STREAM "Name", "ROWTIME", SUM("Distance"), MIN("MagicPoints"), MAX("MagicPoints"), MIN("HealthPoints"), MAX("HealthPoints") FROM "SOURCE_SQL_STREAM_001" GROUP BY FLOOR("SOURCE_SQL_STREAM_001"."ROWTIME" TO MINUTE), "Name";
(单击可缩放)
m.选择保存并运行 SQL。您将看到,每分钟都会出现包含聚合数据的行。请等待这些行出现。
n.单击目标链接。
o.选择连接至目标。
p. 从 Kinesis 流中选择 wildrydes-summary。
q.从应用程序内流名称中选择 DESTINATION_SQL_STREAM。
r.选择保存并继续。

(单击可缩放)
-
第 3 步:读取流中的消息
使用命令行使用者查看 Kinesis 流中的消息,以了解每分钟发送的聚合数据。
a.切换至已打开 Cloud9 环境的选项卡。
b.运行使用者以开始读取流中的数据。
./consumer -stream wildrydes-summary
使用者每分钟会打印 Kinesis Data Analytics 应用程序发送的消息:
{ "Name": "Shadowfax", "StatusTime": "2018-03-18 03:20:00.000", "Distance": 362, "MinMagicPoints": 170, "MaxMagicPoints": 172, "MinHealthPoints": 146, "MaxHealthPoints": 149 } -
第 4 步:使用生产者进行试验
在观察控制面板和使用者时停止并启动生产者。启动具有不同独角兽名称的多个生产者。
a.切换至已打开 Cloud9 环境的选项卡。
b.按 Control + C 停止生产者,并注意此时消息会停止。
c.再次启动生成者,并注意消息已恢复。
d.单击 (+) 按钮并单击新终端以打开新终端选项卡。
e.在新选项卡中启动另一个生产者实例。提供特定的独角兽名称,并在使用者输出中记下这
两个 独角兽的数据点:./producer -name Bucephalus
f. 验证您在输出中看到多个独角兽:
{ "Name": "Shadowfax", "StatusTime": "2018-03-18 03:20:00.000", "Distance": 362, "MinMagicPoints": 170, "MaxMagicPoints": 172, "MinHealthPoints": 146, "MaxHealthPoints": 149 } { "Name": "Bucephalus", "StatusTime": "2018-03-18 03:20:00.000", "Distance": 1773, "MinMagicPoints": 140, "MaxMagicPoints": 148, "MinHealthPoints": 132, "MaxHealthPoints": 138 } -
回顾和提示
🔑 借助 Amazon Kinesis Data Analytics,您可以使用 SQL 查询流数据或构建整个流式处理应用程序,以便获取可行的见解,并及时响应您的业务和客户需求。
🔧 在本模块中,您创建了一个 Kinesis Data Analytics 应用程序,该应用程序从独角兽的 Kinesis 数据流中读取数据,并且每分钟发送一个摘要行。


在下一模块中,您将使用 AWS Lambda 处理来自先前创建的