Nozioni di base / Esperienza pratica / ...
Implementazione di un modello di machine learning su un endpoint di inferenza in tempo reale
TUTORIAL
Panoramica
In questo tutorial, imparerai a implementare un modello di machine learning (ML) addestrato su un endpoint di inferenza in tempo reale tramite Amazon SageMaker Studio.
SageMaker Studio è un ambiente di sviluppo integrato (IDE) per il ML che fornisce un'interfaccia notebook Jupyter completamente gestita in cui è possibile eseguire attività end-to-end del ciclo di vita del ML, inclusa l'implementazione del modello.
SageMaker offre diverse opzioni di inferenza per supportare un'ampia gamma di casi d'uso:
- Inferenza in tempo reale di SageMaker per i carichi di lavoro con requisiti di bassa latenza nell'ordine di millisecondi
- Inferenza serverless di SageMaker per i carichi di lavoro con schemi di traffico intermittenti o poco frequenti
- Inferenza asincrona di SageMaker per le inferenze con dimensioni elevate di payload o che richiedono lunghi tempi di elaborazione
- Trasformazione batch di SageMaker per eseguire le previsioni sui batch di dati
In questo tutorial utilizzerai l'opzione Inferenza in tempo reale per implementare un modello XGBoost di classificazione binaria che è già stato addestrato su un set di dati di sinistri di assicurazione generato artificialmente. Il set di dati è costituito da dettagli e funzionalità estratte dalle tabelle dei sinistri e dei clienti insieme a una colonna frode che indica se un incidente è fraudolento o meno. Il modello prevede la probabilità che un sinistro sia fraudolento. Interpreterai il ruolo di un ingegnere di machine learning per implementare questo modello ed eseguire inferenze campione.
Obiettivi
Con questa guida, imparerai a:
- Creare un modello SageMaker da un artefatto di modello addestrato
- Configurare e implementare un endpoint di inferenza in tempo reale per servire il modello
- Richiamare l'endpoint per eseguire le previsioni campione tramite i dati di test
- Collegare una policy con scalabilità automatica per gestire le modifiche al traffico
Prerequisiti
Prima di iniziare questa guida, avrai bisogno di:
- Un account AWS: se non hai già un account, segui la guida introduttiva Configurazione del tuo ambiente per una panoramica rapida.
Esperienza AWS
Principiante
Tempo per il completamento
25 minuti
Costo richiesto per il completamento
Per una stima dei costi di questo tutorial, consulta Prezzi di SageMaker.
Requisiti
Devi aver effettuato l'accesso con un account AWS.
Servizi utilizzati
Inferenza in tempo reale di Amazon SageMaker, Amazon SageMaker Studio
Ultimo aggiornamento
19 maggio 2022
Implementazione
Fase 1: Configurazione del dominio di Amazon SageMaker Studio
Con Amazon SageMaker puoi implementare un modello visivamente utilizzando la console o in maniera programmatica utilizzando SageMaker Studio o i notebook SageMaker. In questo tutorial, il modello viene implementato in maniera programmatica tramite un notebook SageMaker Studio, che richiede un dominio di SageMaker Studio.
Un account AWS può avere solo un dominio SageMaker Studio per regione. Se hai già un dominio SageMaker Studio nella regione Stati Uniti orientali (Virginia settentrionale), consulta la Guida alla configurazione di SageMaker Studio per collegare le policy AWS IAM richieste all'account SageMaker Studio, quindi salta la fase 1 e passa direttamente alla fase 2.
Se invece non disponi di un dominio SageMaker Studio, continua con la fase 1 per eseguire un modello AWS CloudFormation che crea un dominio SageMaker Studio e aggiunge le autorizzazioni necessarie per il resto di questo tutorial.
Scegli il link dello stack AWS CloudFormation. Questo link apre la console AWS CloudFormation e crea il dominio SageMaker e un utente denominato studio-user. Inoltre aggiunge le autorizzazioni richieste al tuo account SageMaker Studio. Nella console CloudFormation, conferma che Stati Uniti orientali (Virginia settentrionale) sia la regione visualizzata nell'angolo in alto a destra. Il nome dello stack deve essere CFN-SM-IM-Lambda-catalog e non può essere modificato. Questo stack richiede circa 10 minuti per creare tutte le risorse.
Assume inoltre che sia presente un VPC pubblico configurato nell'account. Se non hai un VPC pubblico, consulta VPC con una singola sottorete pubblica per scoprire come creare un VPC pubblico.

Seleziona I acknowledge that AWS CloudFormation might create IAM resources (Sono consapevole che AWS CloudFormation può creare le risorse IAM), quindi scegli Create stack (Crea stack).

Nel riquadro CloudFormation, scegli Stack. La creazione dello stack richiede circa 10 minuti. Una volta creato lo stack, il suo stato passerà da CREATE_IN_PROGRESS a CREATE_COMPLETE.

Fase 2: Configurazione di un notebook SageMaker Studio
In questa fase, avvierai un nuovo notebook SageMaker Studio, installerai le librerie open source necessarie e configurerai le variabili SageMaker necessarie per recuperare l'artefatto del modello addestrato da Amazon Simple Storage Service (Amazon S3). Ma poiché l'artefatto del modello non può essere implementato direttamente per l'inferenza, dovrai prima creare un modello SageMaker dall'artefatto del modello. Il modello creato conterrà il codice di addestramento e di inferenza che SageMaker utilizzerà per la distribuzione del modello.
Digita SageMaker Studio nella barra di ricerca della console, quindi scegli SageMaker Studio.

Scegli US East (N. Virginia) (Stati Uniti orientali [Virginia settentrionale]) dall'elenco a discesa Region (Regione) nell'angolo in alto a destra della console SageMaker. In Launch app (Avvia app), seleziona Studio per aprire SageMaker Studio utilizzando il profilo studio-user.

Apri l'interfaccia di SageMaker Studio. Sulla barra di navigazione, scegli File, New (Nuovo), Notebook.

Nella finestra di dialogo Set up notebook environment (Configura ambiente notebook), in Image (Immagine), seleziona Data Science (Data science). Il kernel Python 3 viene selezionato automaticamente. Scegli Select (Seleziona).

Il kernel nell'angolo in alto a destra del notebook dovrebbe visualizzare Python 3 (Data Science) (Python 3 [data science]).

Copia e incolla il seguente frammento di codice in una cella nel notebook, quindi premi Maius+Invio per eseguire la cella corrente per aggiornare la libreria aiobotocore, che è un'API per interagire con numerosi servizi AWS. Ignora le eventuali avvertenze per riavviare il kernel o gli errori di conflitto delle dipendenze.
%pip install --upgrade -q aiobotocoreDevi inoltre creare un'istanza dell'oggetto client S3 e delle posizioni all'interno del bucket S3 predefinito in cui vengono caricati i parametri e gli artefatti del modello. Per far ciò, copia e incolla il seguente codice in una cella nel notebook ed eseguilo. Tieni presente che il bucket di scrittura sagemaker-<regione>-<id-account> viene creato automaticamente dall'oggetto di sessione SageMaker alla riga 16 nel codice seguente. I set di dati che utilizzi per l'addestramento sono presenti in un bucket S3 pubblico denominato sagemaker-sample-files, che è stato specificato come bucket di lettura sulla riga 29. La posizione all'interno del bucket viene specificata tramite il prefisso di lettura.
import pandas as pd
import numpy as np
import boto3
import sagemaker
import time
import json
import io
from io import StringIO
import base64
import pprint
import re
from sagemaker.image_uris import retrieve
sess = sagemaker.Session()
write_bucket = sess.default_bucket()
write_prefix = "fraud-detect-demo"
region = sess.boto_region_name
s3_client = boto3.client("s3", region_name=region)
sm_client = boto3.client("sagemaker", region_name=region)
sm_runtime_client = boto3.client("sagemaker-runtime")
sm_autoscaling_client = boto3.client("application-autoscaling")
sagemaker_role = sagemaker.get_execution_role()
# S3 locations used for parameterizing the notebook run
read_bucket = "sagemaker-sample-files"
read_prefix = "datasets/tabular/synthetic_automobile_claims"
model_prefix = "models/xgb-fraud"
data_capture_key = f"{write_prefix}/data-capture"
# S3 location of trained model artifact
model_uri = f"s3://{read_bucket}/{model_prefix}/fraud-det-xgb-model.tar.gz"
# S3 path where data captured at endpoint will be stored
data_capture_uri = f"s3://{write_bucket}/{data_capture_key}"
# S3 location of test data
test_data_uri = f"s3://{read_bucket}/{read_prefix}/test.csv"Fase 3: Creazione di un endpoint di inferenza in tempo reale
In SageMaker, esistono diversi metodi per implementare un modello addestrato su un endpoint di inferenza in tempo reale, ovvero l'SDK SageMaker, l'SDK AWS - Boto3 e la console SageMaker. Per ulteriori informazioni, consulta Implementazione di modelli per l'inferenza nella guida per gli sviluppatori di Amazon SageMaker. L'SDK SageMaker ha più astrazioni rispetto all'SDK AWS - Boto3, con quest'ultimo che espone API di livello inferiore per un maggiore controllo sull'implementazione del modello. In questo tutorial il modello sarà implementato utilizzando l'SDK AWS - Boto3. Per implementare un modello, vi sono tre passaggi da completare in sequenza:
- Creazione di un modello SageMaker dall'artefatto del modello
- Creazione di una configurazione dell'endpoint per specificare le proprietà, tra cui tipo di istanza e conteggio
- Creazione dell'endpoint utilizzando la configurazione dell'endpoint
Per creare un modello SageMaker utilizzando l'artefatto del modello addestrato archiviato in S3, copia e incolla il seguente codice. Il metodo create_model utilizza il container Docker contenente l'immagine di addestramento (per questo modello, il container XGBoost) e la posizione S3 dell'artefatto del modello come parametri.
# Retrieve the SageMaker managed XGBoost image
training_image = retrieve(framework="xgboost", region=region, version="1.3-1")
# Specify a unique model name that does not exist
model_name = "fraud-detect-xgb"
primary_container = {
"Image": training_image,
"ModelDataUrl": model_uri
}
model_matches = sm_client.list_models(NameContains=model_name)["Models"]
if not model_matches:
model = sm_client.create_model(ModelName=model_name,
PrimaryContainer=primary_container,
ExecutionRoleArn=sagemaker_role)
else:
print(f"Model with name {model_name} already exists! Change model name to create new")
Puoi controllare il modello creato nella console SageMaker nella sezione Models (Modelli).

Una volta creato il modello SageMaker, copia e incolla il seguente codice per utilizzare il metodo create_endpoint_config di Boto3 per configurare l'endpoint. Gli input principali per il metodo create_endpoint_config sono il nome della configurazione dell'endpoint e le informazioni sulla variante, ad esempio il tipo di istanza di inferenza e il conteggio, il nome del modello da implementare e la condivisione del traffico che deve essere gestita dall'endpoint. Insieme a queste impostazioni, puoi configurare l'acquisizione dei dati specificando DataCaptureConfig. Questa funzione consente di configurare l'endpoint in tempo reale per acquisire e archiviare richieste e/o risposte in Amazon S3. L'acquisizione dei dati è una delle fasi della configurazione del monitoraggio del modello e, se combinata con i parametri di base e i processi di monitoraggio, consente di monitorare le prestazioni del modello confrontando i parametri dei dati di test con le linee base. Tale monitoraggio risulta utile per programmare la riqualificazione del modello in base alla deriva del modello o dei dati e a scopo di verifica. Nella configurazione corrente, sia l'input (i dati di test in entrata) che l'output (le previsioni del modello) vengono acquisiti e archiviati nel bucket S3 predefinito.
# Endpoint Config name
endpoint_config_name = f"{model_name}-endpoint-config"
# Endpoint config parameters
production_variant_dict = {
"VariantName": "Alltraffic",
"ModelName": model_name,
"InitialInstanceCount": 1,
"InstanceType": "ml.m5.xlarge",
"InitialVariantWeight": 1
}
# Data capture config parameters
data_capture_config_dict = {
"EnableCapture": True,
"InitialSamplingPercentage": 100,
"DestinationS3Uri": data_capture_uri,
"CaptureOptions": [{"CaptureMode" : "Input"}, {"CaptureMode" : "Output"}]
}
# Create endpoint config if one with the same name does not exist
endpoint_config_matches = sm_client.list_endpoint_configs(NameContains=endpoint_config_name)["EndpointConfigs"]
if not endpoint_config_matches:
endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[production_variant_dict],
DataCaptureConfig=data_capture_config_dict
)
else:
print(f"Endpoint config with name {endpoint_config_name} already exists! Change endpoint config name to create new")Puoi controllare la configurazione dell'endpoint creata nella console SageMaker nella sezione Endpoint configurations (Configurazioni endpoint).

Per creare l'endpoint, copia e incolla il codice riportato di seguito. Il metodo create_endpoint utilizza la configurazione dell'endpoint come parametro e implementa il modello specificato nella configurazione su un'istanza di calcolo. L'implementazione del modello richiede circa 6 minuti.
endpoint_name = f"{model_name}-endpoint"
endpoint_matches = sm_client.list_endpoints(NameContains=endpoint_name)["Endpoints"]
if not endpoint_matches:
endpoint_response = sm_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)
else:
print(f"Endpoint with name {endpoint_name} already exists! Change endpoint name to create new")
resp = sm_client.describe_endpoint(EndpointName=endpoint_name)
status = resp["EndpointStatus"]
while status == "Creating":
print(f"Endpoint Status: {status}...")
time.sleep(60)
resp = sm_client.describe_endpoint(EndpointName=endpoint_name)
status = resp["EndpointStatus"]
print(f"Endpoint Status: {status}")Per controllare lo stato dell'endpoint, scegli l'icona SageMaker resources (Risorse SageMaker). Per SageMaker resources (Risorse SageMaker), seleziona Endpoints (Endpoint) e per name (nome), seleziona fraud-detect-xgb-endpoint.

Fase 4: Richiamo dell'endpoint di inferenza
Quando lo stato dell'endpoint diventa InService, potrai richiamare l'endpoint utilizzando la REST API, l'SDK AWS - Boto3, SageMaker Studio, AWS CLI o l'SDK Python di SageMaker. In questo tutorial, verrà utilizzato l'SDK AWS - Boto3. Prima di chiamare un endpoint, è importante che i dati di test siano formattati in modo appropriato per l'endpoint utilizzando la serializzazione e la deserializzazione. La serializzazione è il processo di conversione dei dati non elaborati in un formato come .csv in flussi di byte che possono essere utilizzati dall'endpoint. La deserializzazione è il processo inverso di conversione del flusso di byte in un formato leggibile dall'uomo. In questo tutorial, l'endpoint verrà richiamato inviando i primi cinque campioni da un set di dati di test. Per richiamare l'endpoint e ottenere i risultati di previsione, copia e incolla il seguente codice. Poiché la richiesta all'endpoint (set di dati di test) è in formato .csv, per creare il payload viene utilizzato un processo di serializzazione CSV. La risposta viene quindi deserializzata in una matrice di previsioni. Al termine dell'esecuzione, la cella restituisce le previsioni del modello e le etichette true per i campioni di prova. Nota che il modello XGBoost restituisce le probabilità invece delle effettive etichette di classe. Il modello ha previsto una probabilità molto bassa che i campioni di prova siano sinistri fraudolenti e le previsioni sono in linea con le etichette true.
# Fetch test data to run predictions with the endpoint
test_df = pd.read_csv(test_data_uri)
# For content type text/csv, payload should be a string with commas separating the values for each feature
# This is the inference request serialization step
# CSV serialization
csv_file = io.StringIO()
test_sample = test_df.drop(["fraud"], axis=1).iloc[:5]
test_sample.to_csv(csv_file, sep=",", header=False, index=False)
payload = csv_file.getvalue()
response = sm_runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
Body=payload,
ContentType="text/csv",
Accept="text/csv"
)
# This is the inference response deserialization step
# This is a bytes object
result = response["Body"].read()
# Decoding bytes to a string
result = result.decode("utf-8")
# Converting to list of predictions
result = re.split(",|\n",result)
prediction_df = pd.DataFrame()
prediction_df["Prediction"] = result[:5]
prediction_df["Label"] = test_df["fraud"].iloc[:5].values
prediction_df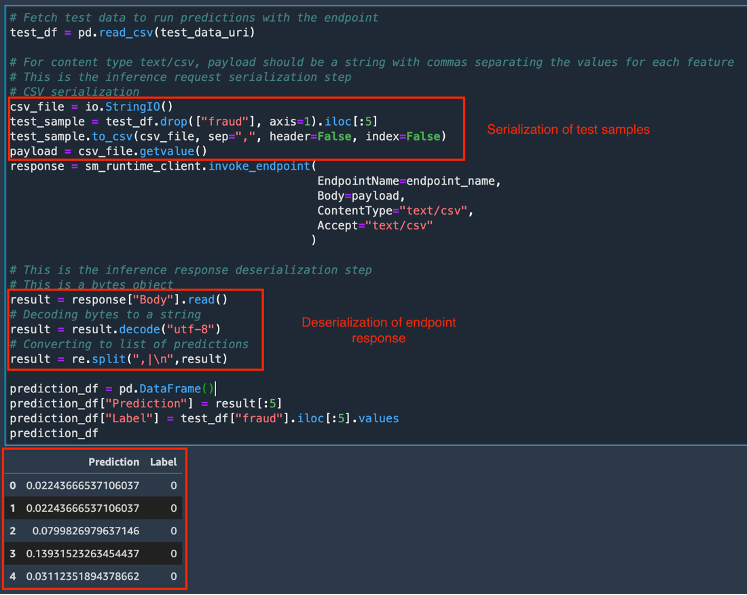
Per monitorare i parametri di chiamata dell'endpoint utilizzando Amazon CloudWatch, apri la console SageMaker. In Inference (Inferenza), seleziona Endpoints (Endpoint), fraud-detect-xgb-endpoint.

Nella pagina Endpoint details (Dettagli dell'endpoint), in Monitor (Monitora), scegli View invocation metrics (Visualizza parametri del richiamo). Inizialmente, nel grafico dei parametri è possibile che vi sia un solo punto. Ma dopo più richiami, vedrai una linea simile a quella nello screenshot di esempio.

La pagina Metrics (Parametri) riporta più parametri di prestazioni dell'endpoint. Per visualizzare le prestazioni dell'endpoint, puoi scegliere periodi di tempo diversi, ad esempio oltre 1 ora o 3 ore. Seleziona un qualsiasi parametro per vederne l'andamento nel periodo di tempo scelto. Nel passaggio successivo, scegli uno di questi parametri per definire le policy di scalabilità automatica.

Poiché l'acquisizione dei dati è stata impostata nella configurazione dell'endpoint, hai un modo per controllare quale payload è stato inviato all'endpoint insieme alla sua risposta. Il caricamento completo su S3 dei dati acquisiti richiede del tempo. Copia e incolla il codice seguente per verificare se l'acquisizione dei dati è completa.
from sagemaker.s3 import S3Downloader
print("Waiting for captures to show up", end="")
for _ in range(90):
capture_files = sorted(S3Downloader.list(f"{data_capture_uri}/{endpoint_name}"))
if capture_files:
capture_file = S3Downloader.read_file(capture_files[-1]).split("\n")
capture_record = json.loads(capture_file[0])
if "inferenceId" in capture_record["eventMetadata"]:
break
print(".", end="", flush=True)
time.sleep(1)
print()
print(f"Found {len(capture_files)} Data Capture Files:")I dati acquisiti vengono archiviati come file separato per ogni chiamata dell'endpoint in S3 in righe JSON, un formato delimitato da una nuova riga per archiviare dati strutturati in cui ogni riga è un valore JSON. Copia e incolla il codice seguente per richiamare i file di acquisizione dati.
capture_files = sorted(S3Downloader.list(f"{data_capture_uri}/{endpoint_name}"))
capture_file = S3Downloader.read_file(capture_files[0]).split("\n")
capture_record = json.loads(capture_file[0])
capture_record
Copia e incolla il codice seguente per decodificare i dati nei file acquisiti utilizzando base64. Il codice recupera i cinque campioni di prova che sono stati inviati come payload e le relative previsioni. Questa funzione è utile per ispezionare i carichi degli endpoint con le risposte del modello e monitorare le prestazioni del modello.
input_data = capture_record["captureData"]["endpointInput"]["data"]
output_data = capture_record["captureData"]["endpointOutput"]["data"]
input_data_list = base64.b64decode(input_data).decode("utf-8").split("\n")
print(input_data_list)
output_data_list = base64.b64decode(output_data).decode("utf-8").split("\n")
print(output_data_list)
Fase 5: Configurazione della scalabilità automatica per l'endpoint
I carichi di lavoro che utilizzano gli endpoint di inferenza in tempo reale in genere hanno requisiti di bassa latenza. Inoltre, in caso di picchi di traffico, gli endpoint di inferenza in tempo reale possono subire un sovraccarico della CPU, una latenza elevata o timeout. Pertanto, è importante dimensionare la capacità per gestire le modifiche del traffico in modo efficiente con una bassa latenza. La scalabilità automatica dell'inferenza di SageMaker monitora i carichi di lavoro e regola dinamicamente il conteggio delle istanze per mantenere prestazioni degli endpoint stabili e prevedibili a basso costo. Quando il carico di lavoro aumenta, la scalabilità automatica porta più istanze online mentre quando diminuisce rimuove le istanze non necessarie, aiutandoti a ridurre i costi di elaborazione. In questo tutorial, per configurare la scalabilità automatica sul tuo endpoint sarà utilizzato l'SDK AWS - Boto3. SageMaker offre diversi tipi di scalabilità automatica: dimensionamento del monitoraggio della destinazione, dimensionamento delle fasi, dimensionamento on demand e dimensionamento pianificato. In questo tutorial, verrà utilizzata una policy di dimensionamento del monitoraggio della destinazione, che viene attivata quando un determinato parametro di dimensionamento aumenta rispetto a una soglia di destinazione scelta.
La scalabilità automatica può essere configurata in due fasi. Innanzitutto, si configura una policy di dimensionamento con i dettagli del numero minimo, desiderato e massimo di istanze per endpoint. Per configurare una policy di dimensionamento del monitoraggio della destinazione, copia e incolla il seguente codice. Il numero massimo di istanze specificato viene avviato quando il traffico supera le soglie selezionate, che scegli nel passaggio successivo.
resp = sm_client.describe_endpoint(EndpointName=endpoint_name)
# SageMaker expects resource id to be provided with the following structure
resource_id = f"endpoint/{endpoint_name}/variant/{resp['ProductionVariants'][0]['VariantName']}"
# Scaling configuration
scaling_config_response = sm_autoscaling_client.register_scalable_target(
ServiceNamespace="sagemaker",
ResourceId=resource_id,
ScalableDimension="sagemaker:variant:DesiredInstanceCount",
MinCapacity=1,
MaxCapacity=2
)Per creare la policy di dimensionamento, copia e incolla il seguente codice. Il parametro di dimensionamento scelto è SageMakerVariantInvocationsPerInstance, che è il numero medio di volte al minuto che ogni istanza di inferenza per una variante di modello viene richiamata. Quando questo numero supera la soglia scelta di 5, la scalabilità automatica viene attivata.
# Create Scaling Policy
policy_name = f"scaling-policy-{endpoint_name}"
scaling_policy_response = sm_autoscaling_client.put_scaling_policy(
PolicyName=policy_name,
ServiceNamespace="sagemaker",
ResourceId=resource_id,
ScalableDimension="sagemaker:variant:DesiredInstanceCount",
PolicyType="TargetTrackingScaling",
TargetTrackingScalingPolicyConfiguration={
"TargetValue": 5.0, # Target for avg invocations per minutes
"PredefinedMetricSpecification": {
"PredefinedMetricType": "SageMakerVariantInvocationsPerInstance",
},
"ScaleInCooldown": 600, # Duration in seconds until scale in
"ScaleOutCooldown": 60 # Duration in seconds between scale out
}
)Per recuperare i dettagli della policy di dimensionamento, copia e incolla il codice riportato di seguito.
response = sm_autoscaling_client.describe_scaling_policies(ServiceNamespace="sagemaker")
pp = pprint.PrettyPrinter(indent=4, depth=4)
for i in response["ScalingPolicies"]:
pp.pprint(i["PolicyName"])
print("")
if("TargetTrackingScalingPolicyConfiguration" in i):
pp.pprint(i["TargetTrackingScalingPolicyConfiguration"])Per eseguire uno stress-test dell'endpoint, copia e incolla il codice riportato di seguito. Il codice viene eseguito per 250 secondi e richiama l'endpoint ripetutamente inviando campioni selezionati casualmente dal set di dati di test.
request_duration = 250
end_time = time.time() + request_duration
print(f"Endpoint will be tested for {request_duration} seconds")
while time.time() < end_time:
csv_file = io.StringIO()
test_sample = test_df.drop(["fraud"], axis=1).iloc[[np.random.randint(0, test_df.shape[0])]]
test_sample.to_csv(csv_file, sep=",", header=False, index=False)
payload = csv_file.getvalue()
response = sm_runtime_client.invoke_endpoint(
EndpointName=endpoint_name,
Body=payload,
ContentType="text/csv"
)Puoi monitorare i parametri dell'endpoint tramite Amazon CloudWatch. Per un elenco di parametri dell'endpoint disponibili, incluso invocation, consulta Parametri di richiamo dell'endpoint SageMaker. Nella console SageMaker, in Inference, (Inferenza), scegli Endpoints (Endpoint), fraud-detect-xgb-endpoint. Nella pagina Endpoint details (Dettagli endpoint), passa alla sezione Monitor (Monitora), quindi scegli View invocation metrics (Visualizza parametri di richiamo). Sulla pagina Metrics (Parametri), seleziona InvocationsPerInstance (questo è un parametro di monitoraggio scelto durante l'impostazione della policy di dimensionamento) e Invocations (Richiami) dall'elenco di parametri, quindi seleziona la scheda Graphed metrics (Parametri su grafico).

Sulla pagina Graphed metrics (Parametri su grafico) puoi analizzare visivamente lo schema di traffico ricevuto dall'endpoint e modificare la granularità temporale, ad esempio dai 5 minuti predefiniti a 1 minuto. Perché la scalabilità automatica aggiunga la seconda istanza potrebbero essere necessari alcuni minuti. Una volta aggiunta la nuova istanza, vedrai che i richiami per istanza sono la metà dei richiami totali.

Quando l'endpoint riceve il payload aumentato, puoi controllare lo stato dell'endpoint eseguendo il codice seguente. Questo codice controlla se lo stato dell'endpoint passa da InService (In servizio) a Updating (Aggiornamento in corso) e tiene traccia dei conteggi delle istanze. Dopo qualche minuto, potrai vedere lo stato passare da InService (In servizio) a Updating (Aggiornamento in corso) per poi tornare a InService (In servizio) ma con un numero di istanze maggiore.
# Check the instance counts after the endpoint gets more load
response = sm_client.describe_endpoint(EndpointName=endpoint_name)
endpoint_status = response["EndpointStatus"]
request_duration = 250
end_time = time.time() + request_duration
print(f"Waiting for Instance count increase for a max of {request_duration} seconds. Please re run this cell in case the count does not change")
while time.time() < end_time:
response = sm_client.describe_endpoint(EndpointName=endpoint_name)
endpoint_status = response["EndpointStatus"]
instance_count = response["ProductionVariants"][0]["CurrentInstanceCount"]
print(f"Status: {endpoint_status}")
print(f"Current Instance count: {instance_count}")
if (endpoint_status=="InService") and (instance_count>1):
break
else:
time.sleep(15)
Fase 6: Eliminazione delle risorse
Per evitare di ricevere addebiti non desiderati, è una best practice consigliata eliminare le risorse non utilizzate.
Elimina il modello, la configurazione dell'endpoint e l'endpoint che hai creato in questo tutorial eseguendo il blocco di codice seguente nel tuo notebook. Se non elimini l'endpoint, il tuo account continuerà ad accumulare addebiti per l'istanza di calcolo in esecuzione sull'endpoint.
# Delete model
sm_client.delete_model(ModelName=model_name)
# Delete endpoint configuration
sm_client.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
# Delete endpoint
sm_client.delete_endpoint(EndpointName=endpoint_name)Per eliminare il bucket S3, completa le seguenti operazioni:
- Apri la console Amazon S3. Sulla barra di navigazione, scegli Buckets (Bucket), sagemaker-<regione>-<id-account>, quindi seleziona la casella di controllo accanto a fraud-detect-demo. Quindi, seleziona Elimina.
- Nella finestra di dialogo Delete objects (Elimina oggetti), verifica di aver selezionato l'oggetto corretto da eliminare, quindi digita permanently delete nella casella di conferma Permanently delete objects (Elimina definitivamente gli oggetti).
- Una volta completato e il bucket è vuoto, potrai eliminare il bucket sagemaker-<regione>-<id-account> eseguendo di nuovo la stessa procedura.

Il kernel Data science utilizzato per eseguire l'immagine del notebook in questo tutorial accumulerà costi fino a quando non lo interromperai o eseguirai i passaggi riportati di seguito per eliminare le app. Per ulteriori informazioni, consulta Risorse di arresto nella guida per gli sviluppatori di Amazon SageMaker.
Per eliminare le app SageMaker Studio, completa la seguente procedura: nella console SageMaker Studio, scegli studio-user, quindi elimina tutte le app riportate in Apps (App) selezionando Delete app (Elimina app). Attendi fino a che Status (Stato) diventa Deleted (Eliminato).

Se nella fase 1 hai utilizzato un dominio SageMaker Studio esistente, salta il resto della fase 6 e procedi direttamente alla sezione conclusiva.
Se hai eseguito il modello CloudFormation nella fase 1 per creare un nuovo dominio SageMaker Studio, continua con le fasi seguenti per eliminare il dominio, l'utente e le risorse create dal modello CloudFormation.
Per aprire la console CloudFormation, immetti CloudFormation nella barra di ricerca della console AWS, quindi scegli CloudFormation dai risultati della ricerca.

Nel riquadro CloudFormation, scegli Stacks (Stack). Dall'elenco a discesa degli stati, seleziona Active (Attivo). In Stack name (Nome stack), scegli CFN-SM-IM-Lambda-catalog per aprire la pagina dei dettagli dello stack.

Nella pagina dei dettagli dello stack CFN-SM-IM-Lambda-catalog, scegli Delete (Elimina) per eliminare lo stack insieme alle risorse create nella fase 1.

Conclusioni
Complimenti! Hai terminato il tutorial Implementazione di un modello di machine learning su un endpoint di inferenza in tempo reale.
In questo tutorial, hai creato un modello SageMaker e lo hai implementato su un endpoint di inferenza in tempo reale. Hai utilizzato l'SDK - Boto3 API per richiamare l'endpoint e testarlo eseguendo inferenze campione sfruttrando la funzione di acquisizione dei dati per salvare i payload e le risposte dell'endpoint su S3. Infine, hai configurato la scalabilità automatica utilizzando un parametro di richiamo dell'endpoint di destinazione per gestire le fluttuazioni del traffico.
Puoi continuare il tuo percorso di machine learning con SageMaker completando le fasi successive riportate di seguito.
Addestramento di un modello di deep learning
Creazione automatica di un modello di ML
Trova altri tutorial pratici