Amazon Web Services ブログ
VAMS における NVIDIA Isaac Lab を使用した GPU アクセラレーション型ロボットシミュレーショントレーニング
本記事は 2026 年 1 月 30 日 に公開された「GPU-Accelerated Robotic Simulation Training with NVIDIA Isaac Lab in VAMS」を翻訳したものです。
オープンソースの Visual Asset Management System (VAMS) が、NVIDIA Isaac Lab との統合により、ロボットアセット向けの GPU アクセラレーション強化学習 (RL) に対応しました。このパイプラインでアセット管理ワークフローから直接 RL ポリシーのトレーニングと評価ができ、AWS Batch でスケーラブルな GPU コンピューティングを活用できます。
フィジカル AI とロボティクス開発のための Isaac Lab

図 1: NVIDIA Isaac Lab でトレーニングされた ANYmal シミュレーション
世界は自律経済に向かって進んでいます。この変革モデルは AI、ロボティクス、シミュレーション、エッジコンピューティングを統合し、人の介入を最小限に抑えて動作するシステムを実現します。この変革の中心にあるのがフィジカル AI です。これは物理世界を認識し、理解し、推論し、行動できるシステムを指します。
実世界でロボットをトレーニングするのは遅く、コストがかかり、危険を伴います。四足歩行ロボットが歩行を習得するには何千回も転倒する可能性があります。転倒するたびに数万ドルのハードウェアが損傷するリスクがあります。シミュレーションはこの状況を完全に変えます。
NVIDIA Isaac Lab は GPU アクセラレーション型ロボティクスシミュレーションの最先端技術です。Isaac Sim の高精度物理エンジン上に構築され、ポリシーの複雑さと GPU 仕様に応じて、単一の GPU 上で数千のロボットインスタンスを並列実行できます。実世界で数か月かかるトレーニングが数時間のシミュレーション時間に圧縮されます。1,000 万の環境ステップを必要とするポリシーを、数か月ではなく一晩でトレーニングできます。
その意義は大きいです:
- 高速な反復サイクル: 新しい報酬関数、ロボット設計、制御戦略を数週間ではなく数時間でテストできます
- 安全な探索: ハードウェアを損傷することなく、ロボットが積極的な動作を学習し、失敗から回復できます
- 再現性: シミュレーションは決定論的な環境を提供し、アルゴリズムの比較と改善の追跡が可能です
- スケール: 数百の実験を並列実行し、体系的なハイパーパラメータ探索が可能です
しかし、この機能へのアクセスには従来、大きなインフラストラクチャの専門知識が必要でした。チームは GPU インスタンスのプロビジョニング、NVIDIA ドライバーの設定、コンテナイメージの管理、トレーニングインフラストラクチャとアセットリポジトリ間のデータ移動パイプラインの構築、アセット、トレーニング済みポリシー、データ設定のバージョン管理を行うカスタムソリューションの作成が必要でした。この運用オーバーヘッドがプロジェクトを遅らせたり、シミュレーショントレーニングを活用できる人を制限したりすることがよくありました。
Isaac Lab を VAMS に統合
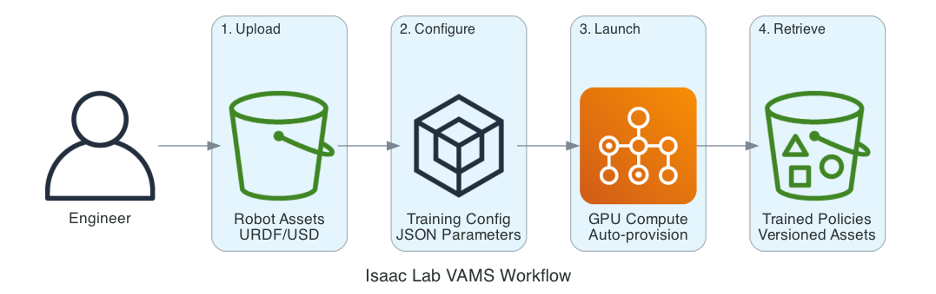
図 2: Isaac Lab VAMS ワークフロー
VAMS の Isaac Lab パイプラインアドオンはこのインフラストラクチャ負担を解消します。アセット管理システムと直接統合することで、ロボットモデルからトレーニング済みポリシーまでのシームレスなパスを作成します:
- アップロード: ロボットの URDF/USD ファイルとカスタム環境を VAMS にアップロードします
- 設定: VAMS にアセットとしてアップロードされたシンプルな JSON ファイルでトレーニングパラメータを設定します
- 起動: GPU コンピューティングを自動的にプロビジョニングするジョブを起動します
- 取得: トレーニング済みポリシーを完全な系統追跡機能を備えたバージョン管理されたアセットとして取得します
GPU インスタンス管理は不要です。コンテナオーケストレーションも不要です。手動のデータ転送も不要です。パイプラインがプロビジョニング、実行、クリーンアップを自動的に処理します。
この統合は、シミュレーショントレーニングが必要だが専任の MLOps リソースがないチームにとって特に価値があります。ロボティクスエンジニアはインフラストラクチャと格闘するのではなく、より優れたロボットと報酬関数の設計に集中できます。一方、組織は VAMS のアセット追跡機能を通じてトレーニング実験を一元的に把握できます。
課題: アセット管理とシミュレーションの橋渡し
ロボットアセットを管理する組織は共通の課題に直面しています。3D モデル、USD ファイル、シミュレーション環境は 1 つのシステムにあり、トレーニングインフラストラクチャは別のシステムに存在します。データサイエンティストはシステム間でアセットを移動し、コンピューティングリソースを設定し、どのアセットでどのポリシーがトレーニングされたかを追跡するのに多くの時間を費やします。
VAMS の Isaac Lab パイプラインは、GPU アクセラレーション型シミュレーショントレーニングをアセット管理ワークフローに直接統合することでこれを解決します。ユーザーは VAMS から離れることなく、ロボットアセットを選択し、トレーニングパラメータを設定し、ジョブを起動できます。
アーキテクチャ概要
パイプラインは複数の AWS サービスを調整してシームレスなトレーニング体験を提供します:
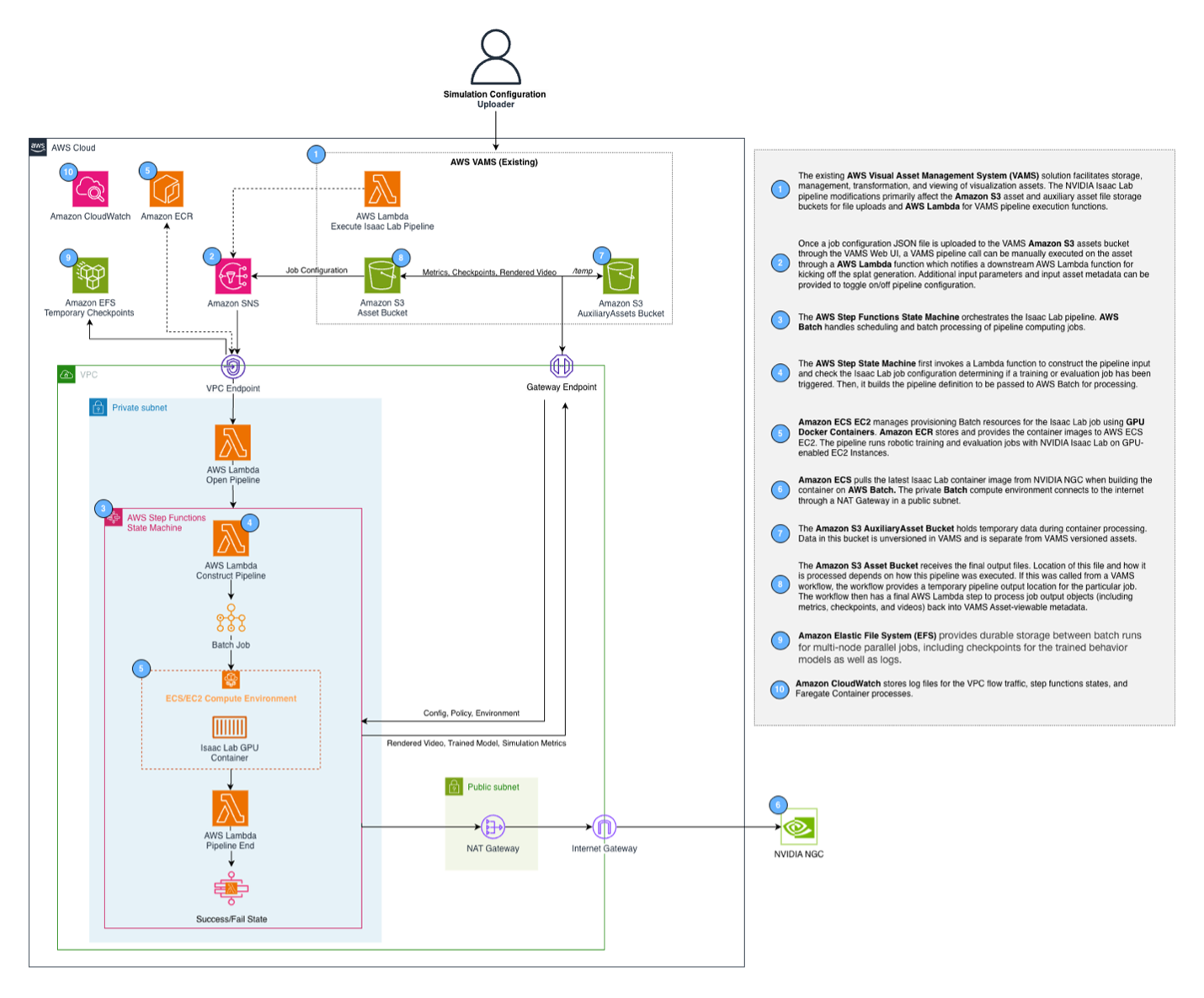 図 3: Isaac Lab パイプラインリファレンスアーキテクチャ
図 3: Isaac Lab パイプラインリファレンスアーキテクチャ
ユーザーがトレーニングジョブを送信すると、リクエストは Amazon API Gateway を経由して AWS Lambda 関数に流れ、AWS Step Functions ワークフローを開始します。このワークフローはジョブ設定を構築し、AWS Batch に送信し、非同期コールバックパターンで完了を待ちます。トレーニングコンテナは NVIDIA GPU を搭載した GPU インスタンス上で実行され、並列シミュレーションに必要なコンピューティングパワーを提供します。
主要なインフラストラクチャコンポーネント:
- AWS Batch コンピューティング環境: GPU インスタンス (g6.2xlarge から g6e.12xlarge) 全体で自動スケーリングするコンテナ化環境
- Amazon EFS: マルチノードジョブ全体でトレーニングチェックポイントを共有するストレージ
- Amazon ECR: Isaac Lab コンテナイメージをホストし、AWS Cloud Development Kit (CDK) デプロイ時に自動的に構築されます
- AWS Step Functions: 適切なエラー処理とタイムアウトでワークフローを調整します
- Container Insights: Amazon Elastic Container Service (Amazon ECS) クラスターで有効化され、モニタリングと可観測性を提供します
コンテナ自体は NVIDIA の公式 Isaac Lab イメージ (nvcr.io/nvidia/isaac-lab:2.3.0) 上に構築され、最新のシミュレーション機能との互換性を保証します。
デュアルモード動作: トレーニングと評価
パイプラインは RL 開発ライフサイクルの異なる段階に対応する 2 つの異なるモードをサポートします。
トレーニングモード
トレーニングモードはゼロから新しいポリシーを作成します。ユーザーはシミュレーションタスク、並列環境の数、トレーニング反復回数を指定します。パイプラインは残りすべてを処理します。VAMS からカスタム環境をダウンロードし、トレーニングループを実行し、チェックポイントを保存し、トレーニング済みポリシーを VAMS にアップロードします。
典型的なトレーニング設定は次のようになります:
{
"name": "Ant Training Job",
"description": "Train a PPO policy for the Isaac-Ant-Direct-v0 environment",
"trainingConfig": {
"mode": "train",
"task": "Isaac-Ant-Direct-v0",
"numEnvs": 4096,
"maxIterations": 1000,
"rlLibrary": "rsl_rl"
},
"computeConfig": {
"numNodes": 1
}
}
numEnvs パラメータは GPU 使用率を制御します。Isaac Lab は単一の GPU 上で数千のシミュレーションインスタンスを並列実行します。四足歩行タスクでは、4096 環境で通常良好な GPU 飽和度を達成します。
トレーニング出力は簡単に識別できるようジョブ UUID の下に整理されます:
- {uuid}/checkpoints/model_*.pt – 定期的な間隔でのモデルチェックポイント
- {uuid}/metrics.csv – TensorBoard からエクスポートされたトレーニングメトリクス
- {uuid}/training-config.json – 入力設定のコピー
- {uuid}/*.txt – ログファイル
評価モード
トレーニング済みポリシーを取得したら、評価モードでパフォーマンスを評価できます。このモードは既存のポリシーをロードし、指定された数のエピソードを実行し、メトリクスを収集してビデオを記録します。
{
"name": "Ant Evaluation Job",
"description": "Evaluate a trained PPO policy for the Isaac-Ant-Direct-v0 environment",
"trainingConfig": {
"mode": "evaluate",
"task": "Isaac-Ant-Direct-v0",
"checkpointPath": "checkpoints/model_1000.pt",
"numEnvs": 4,
"numEpisodes": 5,
"stepsPerEpisode": 900,
"rlLibrary": "rsl_rl"
},
"computeConfig": {
"numNodes": 1
}
}評価では、目標がトレーニングスループットではなく評価であるため、並列環境を少なく (4096 ではなく 4) 使用します。
評価出力には以下が含まれます:
- {uuid}/videos/*.mp4 – 記録された評価ビデオ
- {uuid}/metrics.csv – 評価メトリクス
- {uuid}/evaluation-config.json – 入力設定のコピー
Isaac Lab の play スクリプトが適切に終了するには –video フラグが必要なため、評価中は常にビデオが生成されます。

図 4: トレーニング済みポリシーからのビデオ評価出力
チェックポイント検出
パイプラインは評価用のチェックポイントファイルを指定する 3 つの方法をサポートします:
- 相対パス (推奨): checkpointPath を使用して同じアセット内のチェックポイントを参照します (例: “checkpoints/model_300.pt”)
- 完全な S3 URI: policyS3Uri をアセット間または外部チェックポイントに使用します (例: “s3://bucket/path/model.pt”)
- 自動検出: 評価設定と同じディレクトリに .pt ファイルを配置します (レガシー、下位互換性のため)
VAMS を通じたジョブの実行
VAMS を通じて Isaac Lab トレーニングジョブを実行する前に、VAMS のインストールと開始手順に従って、VAMS ソリューションとデータベースをデプロイおよびセットアップしてください。
VAMS の準備ができたら、トレーニングジョブを実行する最も簡単な方法は VAMS Web アプリケーションを使用することです:
1. 実行予定のジョブタイプ (トレーニングまたは評価など) の設定 JSON を作成します。トレーニング設定 JSON の例:
1. {
2. "name": "ANYmal Training Job",
3. "description": "Train a PPO policy for the Isaac-Velocity-Rough-Anymal-D-v0 environment",
4. "trainingConfig": {
5. "mode": "train",
6. "task": " Isaac-Velocity-Rough-Anymal-D-v0",
7. "numEnvs": 2048,
8. "maxIterations": 3000,
9. "rlLibrary": "rsl_rl"
10. },
11. "computeConfig": {
12. "numNodes": 1
13. }
14. }2. Web UI を使用してトレーニング設定 JSON ファイルを VAMS にアップロードします:
図 5: Web UI でファイルをドラッグアンドドロップ
3. Workflows に移動し、Isaac Lab Training または Evaluation パイプラインを選択します
図 6: VAMS ワークフロータブ
4. Execute Workflow を選択します
5. Select Workflow ドロップダウンから isaaclab-training ワークフローを選択します

図 7: VAMS ワークフロー選択
6. Select File to Process ドロップダウンからトレーニング設定 JSON アセットを選択します

図 8: VAMS ワークフローファイル選択
7. Execute Workflow ボタンをクリックしてワークフローを送信します
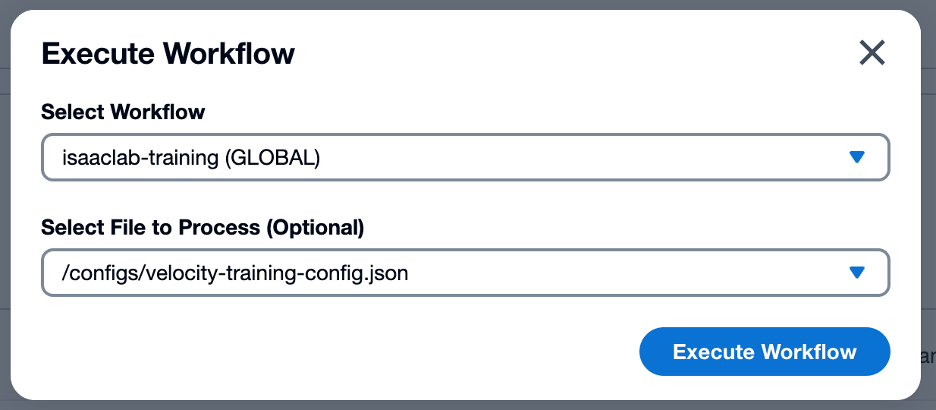
図 9: Isaac Lab トレーニングジョブ用に設定された VAMS ワークフローモーダル
VAMS は実行ステータスをリアルタイムで追跡します。完了すると、トレーニング済みポリシーが元のロボットアセットにリンクされた新しいアセットバージョンとして表示され、完全な系統が維持されます。トレーニングジョブの詳細については、管理者は Amazon CloudWatch でトレーニング出力ログを確認できます。
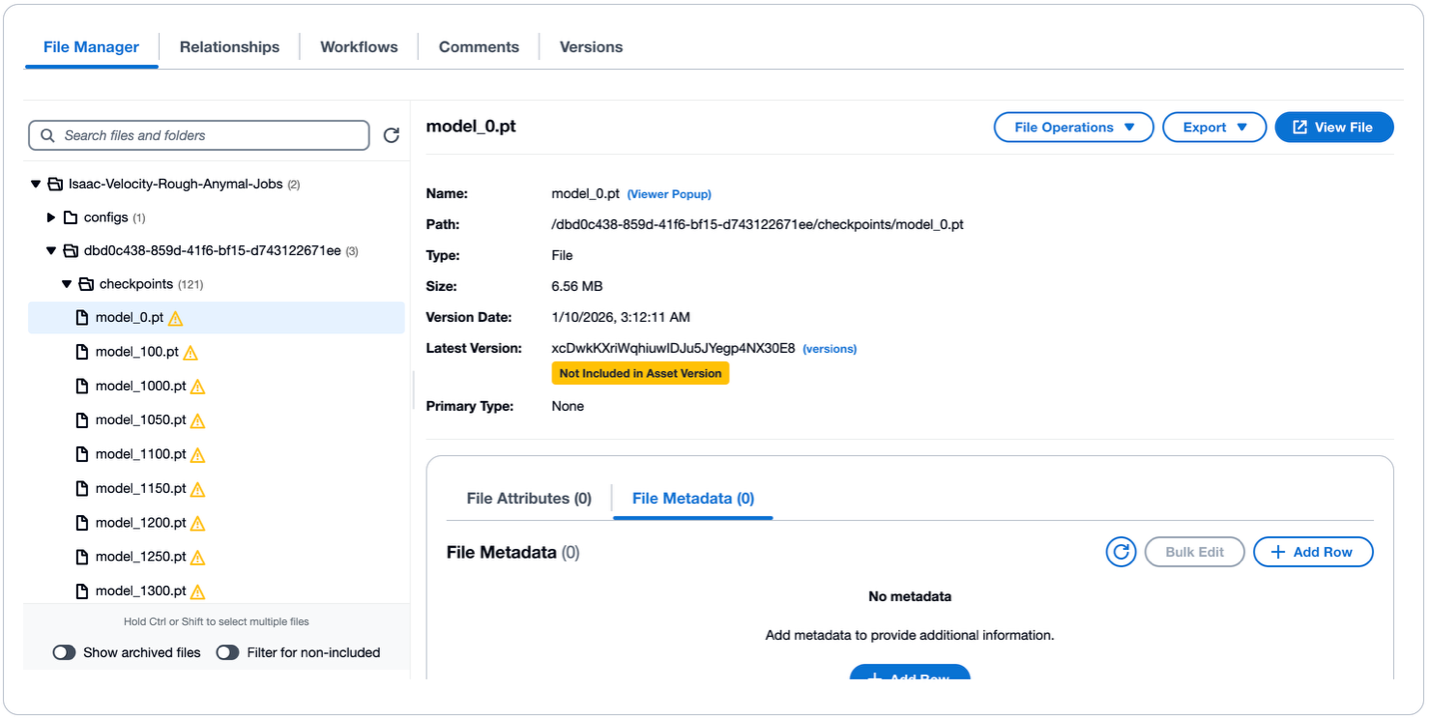
図 10: VAMS ファイルマネージャーのトレーニング済みポリシーアセット
カスタム環境の使用
Isaac Lab には 40 以上の事前構築された環境が含まれていますが、多くのプロジェクトではカスタムタスクが必要です。VAMS は簡単なパッケージングワークフローでこれをサポートします。
まず、Isaac Lab のテンプレート構造に従ってカスタム環境を作成します:
my_custom_env/
├── setup.py
├── my_custom_env/
│ ├── __init__.py # Contains gym.register() call
│ ├── my_env.py # Environment implementation
│ └── my_env_cfg.py # Configuration classes
└── agents/
└── rsl_rl_ppo_cfg.pytarball としてパッケージ化し、アセットとして VAMS にアップロードします:
tar -czf my_custom_env.tar.gz my_custom_env/
# VAMS Web UI または API 経由でアップロードトレーニングジョブを送信する際、カスタム環境アセットを参照します。パイプラインはトレーニング開始前に自動的にダウンロードしてインストールします:
{
"trainingConfig": {
"task": "MyCustom-Robot-v0",
"numEnvs": 4096,
"maxIterations": 5000
},
"customEnvironmentPath": "environments/my_custom_env.tar.gz"
}パフォーマンスに関する考慮事項
インスタンスの選択
パイプラインは自動選択で複数の GPU インスタンスタイプをサポートします:
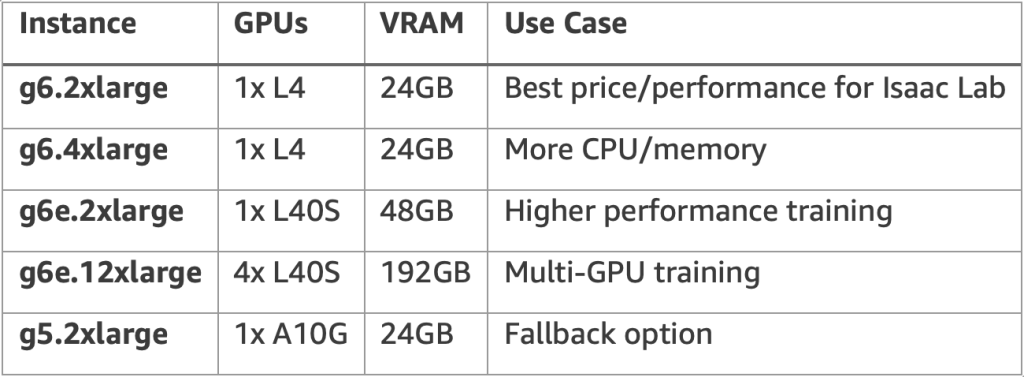
パイプラインは BEST_FIT_PROGRESSIVE 割り当て戦略を使用し、価格とパフォーマンスのバランスが最適な G6 インスタンス (L4 GPU) を優先し、次に G6E (L40S)、フォールバックとして G5 (A10G) を使用します。
マルチノードトレーニング
最大規模の実験では、パイプラインは PyTorch の分散トレーニング (torchrun) によるマルチノード並列トレーニングをサポートします。コンピューティング設定で numNodes > 1 を設定します:
{
"computeConfig": {
"numNodes": 4
}
}パイプラインは AWS Batch のマルチノード並列ジョブ機能を通じてノード通信を自動的に設定します。チェックポイントは Amazon Elastic File System (Amazon EFS) 経由で共有され、すべてのノードが同期された状態を維持します。
Isaac Lab を使用した AWS Batch マルチノードトレーニングの詳細なガイドについては、AWS のこちらのブログを参照してください。
パイプラインの有効化
Isaac Lab パイプラインには VAMS で VPC モードを有効にする必要があります。VAMS 設定オプションの詳細については、設定ガイドを確認してください。/infra/config/config.json にある VAMS 設定ファイルを更新します:
{
"app": {
"useGlobalVpc": {
"enabled": true,
"addVpcEndpoints": true
},
"pipelines": {
"useIsaacLabTraining": {
"enabled": true,
"acceptNvidiaEula": true,
"autoRegisterWithVAMS": true,
"keepWarmInstance": false
}
}
}
}重要: NVIDIA ソフトウェアライセンス契約に同意するには、acceptNvidiaEula: true を設定する必要があります。これを設定しないとデプロイは失敗します。

Isaac Lab パラメータを含むように設定ファイルを更新したら、標準の VAMS 手順に従って Isaac Lab アドオンを含む VAMS ソリューションをデプロイできます。
デプロイは Isaac Lab コンテナを自動的に構築し、Amazon Elastic Container Registry (Amazon ECR) にプッシュします。最初の Batch ジョブは約 10GB のコンテナイメージをプルするのに 5〜10 分かかる場合があります。その後のジョブはインスタンスキャッシュにより高速に起動します。
コンテナ Pull 時間の最適化
ジョブの起動を高速化するには:
- ウォームインスタンスの維持: keepWarmInstance: true を設定してインスタンスを実行状態に保ちます (最小 8 vCPU)。インスタンスをウォーム状態に保つとパイプラインの実行コストが増加します。この設定は指定された数の EC2 vCPU を実行状態に保ちます。
- AMI の事前構築: コンテナイメージを事前キャッシュしたカスタム AMI を作成します
- 大容量 EBS ボリューム: パイプラインは Docker レイヤーキャッシュを備えた 100GB GP3 EBS ボリュームを使用します
次のステップ
Isaac Lab 統合はロボットアセットワークフローに新しい可能性を開きます。GPU アクセラレーション型シミュレーショントレーニングを VAMS に統合することで、チームはアセット、トレーニング実行、デプロイされたポリシー間の完全なトレーサビリティを維持しながら、ロボットの動作をより速く反復できます。Isaac Lab の高精度物理シミュレーションと VAMS のアセット管理機能の組み合わせは、ロボット AI 開発のための強力なプラットフォームを作成します。
始めましょう
Isaac Lab パイプラインは VAMS 2.4.0 で利用できます。完全なソースコード、詳細なドキュメント、コスト見積もり、トラブルシューティングガイドは VAMS GitHub リポジトリで入手できます。
著者について
この記事は Kiro が翻訳を担当し、Professional Services の Akinori Hiratani と Solution Architect の Shinya Nishizaka がレビューしました。