Amazon Web Services ブログ
AWS IoT とサーバーレスデータレイクを使用したフロントライン脳震盪モニタリングシステムの構築方法 – パート 1
スポーツ関連の軽度外傷性脳損傷 (mTBI) は、医学界、スポーツ界、そして子育てコミュニティの異なるグループの中で懸念を生じ続けています。アメリカでは、レクリエーションレベルで毎年約 160~380 万件の mTBI 事故が起こっており、そのほとんどが病院で治療を受けていません。(その他のリソースにある「The epidemiology and impact of traumatic brain injury: a brief overview」を参照してください。) 軽度外傷性脳損傷の医療および間接的な費用の推定額は、毎年 600 億 USD に上っています。
北アメリカの救急医療施設では、入院患者の外傷性脳損傷 (TBI) ケースに関するデータを収集していますが、スポーツ選手たちの中で起こった未報告の mTBI の件数について、意味のあるデータはありません。最近の研究では、スポーツ関連の mTBI について、多くの要因による極めて高い過小報告率が示されています。これらの要因には、チームスタッフが単に兆候や症状を認識できない、またはその影響を実際に目にしていないことが含まれます。(その他のリソースにある「A prospective study of physician-observed concussions during junior ice hockey: implications for incidence rates」を参照してください。)
ホッケーやフットボールの選手の大部分は、大学の選手でもなければ、プロの選手でもありません。ユースホッケーの選手は 300 万人を超え、約 500 万人がフットボールに参加登録しています。(その他のリソースにある「Head Impact Exposure in Youth Football」を参照してください。) これらのレクリエーション選手たちには、脳震盪の認識、サイドラインでの外傷評価における訓練を受けた医療スタッフへの基本的なアクセスがありません。利用しやすい測定とスマートフォンベースの評価ツールは、頭部外傷の可能性の特定、評価、および競技復帰 (RTP) 基準の間のプロセスを円滑化します。
最近、頭部衝撃遠隔測定システム (HITS) を含む機器搭載のスポーツ用ヘルメットの使用が、数多くの研究試験における頭部への衝撃の詳細な記録のために許可されています。この実践は、練習における接触と特定のヘルメット設計パラメーターを改める勧告につながりました。(その他のリソースにある「Head impact severity measures for evaluating mild traumatic brain injury risk exposure」を参照してください。) しかし、HITS システムのコストの高さと装置の複雑さのため、これは一般的なレクリエーション人口にとって実用的な衝撃アラートデバイスではありません。
訓練を受けた医療従事者がいないことがありがちなスポーツ環境には、頭部外傷を測定するためのシンプルで実用的、かつ手頃な価格のシステムが必要です。
スマートフォンの急増から判断して、私たちは、これがこのタイプのモニタリングを提供するために研究すべき実用的なデバイスだと感じました。 すべてのスマートフォンデバイスには、様々な範囲でデータを送受信する Bluetooth 通信システムが内蔵されています。 このデモでは、クラス 1 の Bluetooth デバイスをハードウェア通信手段として選択しました。これを選択した理由は、その簡便さ、一般に認められた標準、および既存のスマートフォンと IoT デバイスとのインターフェイスにおける互換性です。
リモートモニタリングには通常、デバイス (例えばウェアラブルデバイス) からの情報のエッジでの収集、その情報のデータレイクへの統合、および関連するステークホルダーに提供することができる推論の生成が関与します。さらに、場合によっては、データの収集と応答の間のフィードバックループを短縮するために、コンピューティングと推論をエッジで行わなければならないこともあります。
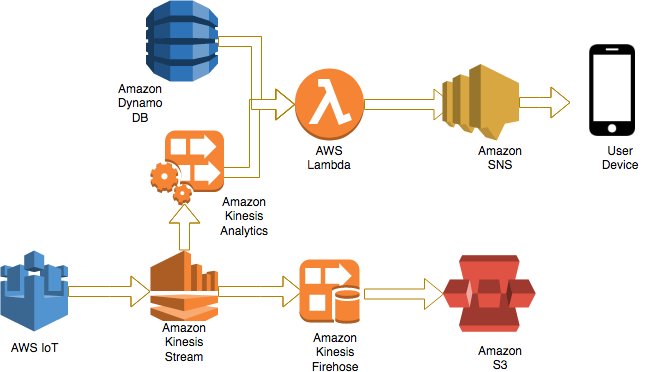
このユースケースは、多種多様な垂直市場におけるその他多くのユースケースに拡張することができます。この 2 回シリーズでは、データレイクをサポートするデータパイプラインの構築方法をご紹介します。今回は、Amazon Kinesis Data Streams、Kinesis Data Analytics、Kinesis Data Firehose、および AWS Lambda などの AWS の主なサービスを使用します。パート 2 では、RTP パラメーターをサポートできるデータから、シンプルな推論を生成することに焦点を当てます。
アーキテクチャの概要
この 2 回シリーズの対象となる AWS アーキテクチャは以下のとおりです。

注意: 心拍数モニタリングセンサーはヘルメットセンサーと比べてはるかに入手しやすいため、このデモでは、ヘルメットセンサーではなく心拍数モニタリングセンサーの使用を選択しました。どちらのタイプのセンサーも、データを送信する方法において非常に類似しています。これらは、データレイクソリューションへの統合方法に関しても、非常に似通っています。
結果のデモは、以下のコンポーネントを使用して心拍データを転送します。
- 心拍数データをクラウドにストリーミングするための、Raspberry Pi 3 を使ってセットアップされた AWS Greengrass。
- データは Amazon Kinesis Data Streams を通じて取り込まれ、raw データは Kinesis Data Firehose を使用して Amazon S3 バケットに保存されます。「Kinesis Data Streams を使用した Kinesis Data Firehose への書き込み」で詳細を確認してください。
- Kinesis Data Analytics は、ストリームデータの取り込みの間に 1 分当たりの心拍を平均化し、平均値を AWS Lambda に渡します。
- AWS Lambda は、リアルタイムのデータを Amazon DynamoDB に保存されたベースライン情報と比較することによって、心拍データに情報を追加します。
- 例えば、心拍数が 120 BPM を超えると、AWS Lambda は Amazon SNS トピック を通じて SMS/ E メールアラートを送信します。
- AWS Glue は、ETL (Extract/Transform/Load) ジョブを実行します。このジョブは、JSON フォーマットのデータストアを圧縮された Apache Parquet カラムナフォーマットに変換し、より迅速なクエリ処理のために変換されたパーティションを適用します。AWS Glue は、Amazon S3 バケットに保存されたデータのクローリング、およびメタデータカタログの構築のための完全マネージド型 ETL サービスです。
- Amazon Athena は、AWS Glue によって処理されるデータのアドホッククエリ分析のために使用されます。このデータは、心臓疾患リスクを減らすための、予測分析を使用した機械学習処理にも使用できます。
- Amazon QuickSight は完全マネージド型の可視化ツールです。これは、Amazon Athena をデータソースとして使用して、心拍数データをビジュアルダッシュボードに表示するために視覚的な折れ線グラフと円グラフを描き出します。
すべてのデータパイプラインはサーバーレスで、最新のデータを提供するために定期的に更新されます。
Kinesis Data Firehose を使用すると、AWS Glue を使用せずに、パイプラインのデータを圧縮された Parquet フォーマットに変換することができます。この記事では、一元化された AWS Glue Data Catalog を含む機能を明らかにするために、AWS Glue を使っています。この Data Catalog は、アドホッククエリのための Athena による使用、および複雑な機械学習プロセスを実行するための Apache Spark EMR による使用が可能です。AWS Glue では、より複雑なユースケースのためのデータを処理するために、生成された ETL スクリプトを編集することもでき、「bring your own ETL」をサポートします。
パイプラインをサポートするための主要プロセスの設定
以下のセクションでは、データレイクをサポートするデータパイプラインの構築のデモで使用されるデバイスとサービスのセットアップおよび設定方法を説明します。
リモートセンサーと IoT デバイス
心拍数などの心電図 (ECG) 情報を収集するには、市販の心拍数モニターを使用できます。モニターは、精度を高めるため、胸骨上にセンサーが配置されるように胸回りに固定します。モニターは心拍数を測定し、Bluetooth Low Energy (BLE) 経由で Raspberry Pi 3 にデータを送信します。以下の図は、今回のデモのデバイス側のアーキテクチャを表しています。

Raspberry Pi 3 は IoT デバイスと AWS Greengrass コア両方のホストです。IoT デバイスは、BLE 経由で心拍数モニターに接続し、心拍数データを収集する責任を担います。収集されたデータは、その後 AWS Greengrass コアにローカルに送信されます。データはここで処理され、セキュアな接続を通じてクラウドにルーティングされます。AWS Greengrass コアは、心拍数モニターの「エッジ」ゲートウェイとして機能します。
Raspberry Pi 3 での AWS Greengrass コアソフトウェアのセットアップ
AWS Greengrass ソフトウェアを実行するために Raspberry Pi を準備するには、AWS Greengrass 開発者ガイドの「Greengrass の環境設定」にある手順に従ってください。
Raspberry Pi をセットアップしたら、AWS Greengrass をインストールし、最初の Greengrass グループを作成する準備が整います。「AWS IoT の AWS Greengrass の設定」にある手順に従って、Greengrass グループを作成します。次に、「コアデバイスでの AWS Greengrass の起動」にある手順に従って、Raspberry Pi に適切な証明書をインストールします。
前述のステップは、デバイス、サブスクリプションリスト、および接続情報の 3 つの個別の設定可能項目で構成されている Greengrass グループをデプロイします。
コアデバイスは、センサーから心拍数情報を収集し、それを AWS Greengrass コアに送信する責任を担う一連のコードです。このデバイスは、Greengrass Discovery API を含む AWS IoT Device SDK for Python を使用しています。
以下の AWS CLI コマンドを使用して Greengrass グループを作成します。
セットアップを完了するには、「AWS Greengrass グループで AWS IoT デバイスを作成する」の手順に従ってください。
セットアップ完了後、心拍数データは、デバイスから AWS Greengrass を使用する AWS IoT Core サービスにルーティングされます。したがって、このメッセージルートを円滑にするために、Greengrass グループに単一のサブスクリプションを追加する必要があります。
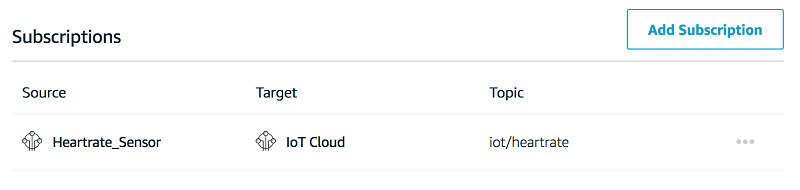
ここでは、デバイスが Heartrate_Sensor と命名されており、ターゲットはトピック iot/heartrate の IoT Cloud です。これは、デバイスが iot/heartrate トピックに発行するとき、AWS Greengrass もこのメッセージを同じトピックで AWS IoT Core サービスに送信することを意味します。その後、幅広い AWS のサービスを使用してデータを処理できます。
接続情報はローカルホストを使用するように設定されています。これは、IoT デバイスが AWS Greengrass コアソフトウェアと共に Raspberry Pi 3 上に置かれているからです。IoT デバイスは、IoT デバイスが関連づけられている AWS Greengrass コアの接続情報を取得する責任を担う Discovery API を使用します。
IoT デバイスは次に、エンドポイントとポート情報を使って、心拍数データが送信される AWS Greengrass コアへのセキュアな TLS 接続を開きます。AWS Greengrass コアの接続情報は以下のようになっているはずです。

AWS Greengrass コアの力は、心拍数情報を Raspberry Pi 3 でローカルに処理するために、AWS Lambda 関数と新しいサブスクリプションをデプロイできることです。例えば、心拍数が一連のしきい値に達した場合の反応をトリガーする AWS Lambda 関数をデプロイできます。異なる個人には異なる応答が必要となる場合があるため、このシナリオでは必要に応じて、理論的に個人レベルのユニークな Lambda 関数をデプロイできます。
AWS Greengrass と AWS IoT Core の設定
AWS Greengrass コアから AWS IoT Core に発行された心拍数データメッセージのさらなる処理とストレージを可能にするため、AWS IoT ルールを作成します。AWS IoT ルールは IoT/heartrate トピックに発行されたメッセージを取得し、それらを Kinesis アクション用の AWS IoT ルールアクションを通じて Kinesis データストリームに送信します。
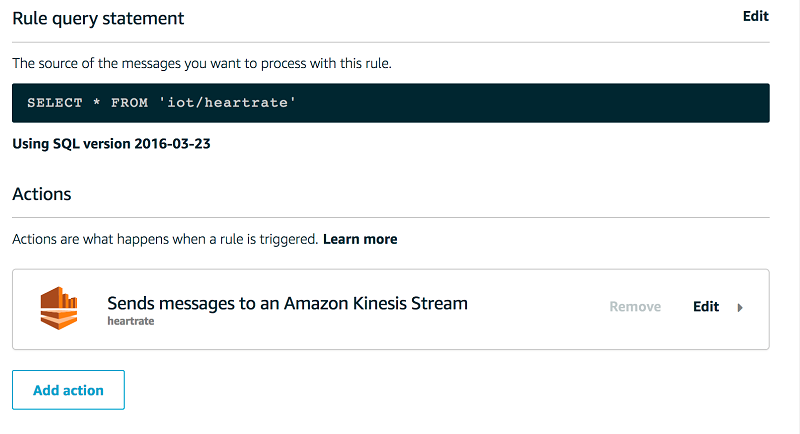
心拍数データのシミュレーション
IoT デバイスにアクセスできない場合もありますが、それでも心拍数ユースケースについての概念実証 (PoC) は実行するようにしてください。シェルスクリプトを作成して、そのデータシミュレーションスクリプトを Amazon EC2 インスタンスにデプロイすることによって、データをシミュレートできます。Amazon EC2 Linux インスタンスを起動するには、EC2 ユーザーガイドを参照してください。
Amazon EC2 インスタンスで、スクリプト kinesis_client_HeartRate.sh を作成し、提供されたコードをコピーして、Kinesis データストリームにレコードを記述し始めます。Kinesis データストリームを作成して、以下のスクリプトの変数 <your_stream_name> を入れ替えるようにしてください。
また、Kinesis Data Generator を使ってデータを作成してから、それをお使いのソリューションまたはデモにストリーミングすることもできます。Kinesis Data Generator の使用に関する詳細については、ブログ記事Amazon Kinesis Data Generator を使用してストリーミングデータソリューションをテストするを参照してください。
Kinesis を使用したデータの取り込みと、Lambda、DynamoDB、および Amazon SNS を使ったアラートの管理
ここで、IoT デバイスからデータを取り込む必要があります。データは、異常な心拍数が検知されたときのリアルタイム通知のために処理できます。
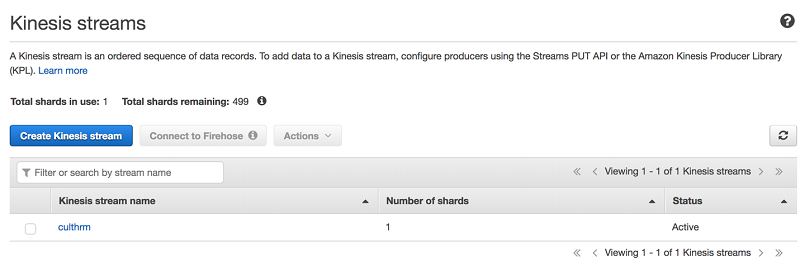
心拍数モニタリングデバイスからのストリーミングデータが Kinesis Data Streams に取り込まれます。Amazon Kinesis は、リアルタイムのストリーミングデータの収集と分析を容易にします。このプロジェクトでは、データストリームはひとつのシャードを使って設定されており、データ保持期間は 24 時間です。これは、1 秒あたり 1 MB のデータ、または 1,000 件のイベントを送信し、1 秒あたり 2 MB のデータを読み取ることを可能にします。より多くのデバイスをサポートする必要がある場合は、UpdateShardCount API または Amazon Kinesis Scaling Utility を使用してスケールアップし、より多くのシャードを追加できます。
データストリームは、以下の AWS CLI コマンドを使用することによって設定できます (その後、適切なフラグを使って暗号化をオンにします)。
AWS CloudFormation テンプレート を使用して、以下のアーキテクチャ図に示されるスタック全体を作成できます。

AWS CloudFormation テンプレートを起動するときは、パラメーターとして適切なエンドポイントプロトコル (「Email」または「SMS」) で E メールアドレスまたは携帯電話番号を入力するようにしてください。

その代わりに、本記事に記載されているドキュメントリンクにある手動手順に従うこともできます。
Kinesis 内のストリーミングデータは、Kinesis Client を使ってリアルタイムで処理および分析できます。Kinesis データストリームの作成方法について学ぶには、Kinesis Data Streams 開発者ガイドを参照してください。
異常な心拍数情報を識別するには、リアルタイムの分析を使って異常な動作を検知する必要があります。Kinesis Data Analytics を使用して、リアルタイムでストリーミングデータの分析を行うことができます。Kinesis Data Analytics は、ソース、リアルタイム分析、および宛先の 3 つの設定可能なコンポーネントで構成されています。詳細な Kinesis Data Analytics の設定手順については、AWS ドキュメントを参照してください。
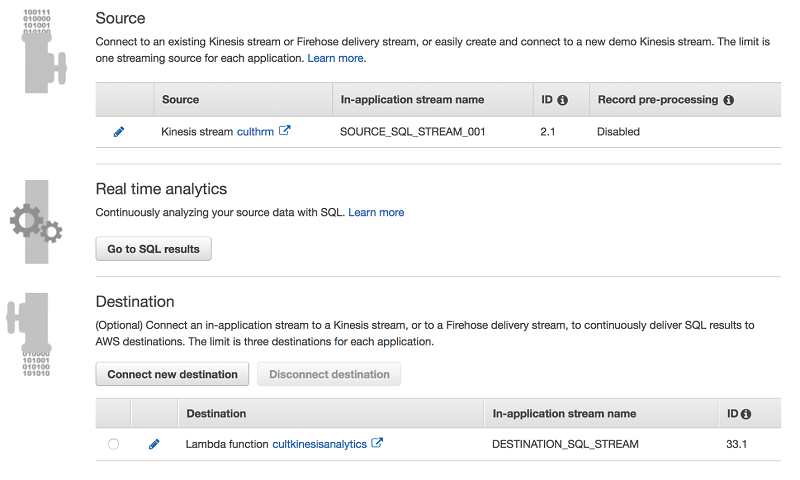
Kinesis Data Analytics は Kinesis Data Streams をデータのソースストリームとして使用します。ソース設定プロセスで、レコードのインバウンドフィルタリングまたはマスキングが必要となるシナリオがある場合は、AWS Lambda を使ってレコードを事前に処理できます。この特定のケースにおけるデータは比較的シンプルであるため、データのレコードを事前処理する必要はありません。
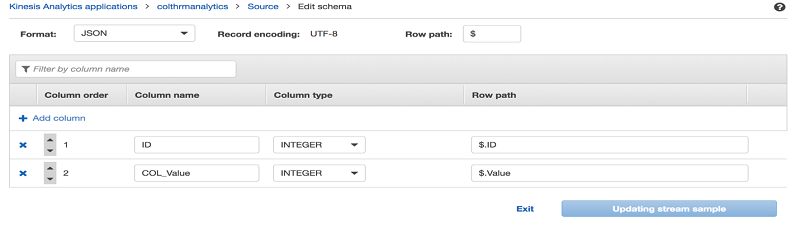
Kinesis Data Analytics のスキーマエディタでは、必要に応じてスキーマを編集または変換することができます。以下の例では、2 番目の列を COL_Value ではなく Value に変換しました。
リアルタイムの分析には、データのリアルタイム分析を実行する SQL コードを SQL Editor にコピーする必要があります。以下はこのデモのために使用したサンプルコードです。
このコードは DESTINATION_SQL_STREAM を生成します。これは、SOURCE_SQL_STREAM_001 から受け取った心拍数の平均値が、60 秒の時間枠内で 120 を超える または 40 を下回る場合に限り、ストリームに値を挿入します。
Tumbling window 概念の詳細については、「Tumbling Windows (Aggregations Using GROUP BY)」を参照してください。

次に、AWS Lambda 関数を宛先のひとつとして追加し、以下のように設定します。

Destination エディタで、選択されているストリーム名が DESTINATION_SQL_STREAM であることを確認します。心拍数の異常が検知される場合にのみ Lambda 関数がトリガーされるようにする必要があります。出力フォーマットは JSON または CSV にすることができます。この例では、Lambda 関数が JSON フォーマットのデータを期待しているので、JSON を選択します。
スポーツ選手とアスレティックトレーナーの登録情報は Heartrate Registrations DynamoDB テーブルに保存されます。Amazon DynamoDB は、AWS Key Management Service (AWS KMS) が管理する DynamoDB 向けの暗号化キーを使った保管時の完全マネージド型暗号化を提供します。テーブルは、保管時の暗号化を有効にして作成する必要があります。「保管時の Amazon DynamoDB 暗号化」にある詳細手順に従ってください。
テーブル内の各レコードには、deviceid、customerid、firstname、lastname、および mobile が含まれているようにしてください。以下は、参照用のテーブルレコード例です。
DynamoDB テーブルの作成とデータ投入についての完全な手順については、DynamoDB 開発者ガイドを参照してください。
Lambda 関数は、Kinesis Data Analytics アプリケーションから渡されたレコードを処理するために作成されています。 Node.js Lambda 関数は、DynamoDB Registrations テーブルからスポーツ選手とアスレティックトレーナーの情報を取得します。その後、Amazon Simple Notification Service (Amazon SNS) 経由でセルラーテキストメッセージを送信することによって、イベントについてアスレティックトレーナーを警告します。
注意: モバイルメッセージに対する Amazon SNS のデフォルトの AWS アカウント上限は、1 月あたり 1.00 USD です。この上限は、「AWS サービス制限」で説明されている SNS 制限の引き上げケースによって引き上げることができます。
ここで、Node.js 6.10 ランタイムを使った新しい Lambda 関数を作成し、IAM のアクセス許可に [カスタムロールの作成] オプションを選択します。 初めて Lambda 関数をデプロイする場合は、「シンプルな Lambda 関数を作成する」を参照してください。
新しい Lambda 関数は、特定の IAM ロールを使って設定し、提供された AWS CloudFormation テンプレートにある Amazon CloudWatch ログ、Amazon DynamoDB、および Amazon SNS に特権を付与する必要があります。
提供された AWS Lambda 関数は、Kinesis Data Analytics から渡された、base64 で暗号化されている JSON メッセージから心拍数モニターデバイス ID と心拍数平均値を取得します。 心拍数モニターデバイス ID を取得した後、関数は DynamoDB Athlete Registration テーブルをクエリして、選手とアスレティックトレーナーの情報を取得します。
最後に、AWS Lambda 関数は Amazon SNS サービスを使って、スポーツ選手データから取得したアスレティックトレーナーの携帯電話番号にモバイルテキスト通知 (秘密情報は一切含まれていません) を送信します。
他のツールを使用したさらなる分析と可視化のためにストリーミングデータを S3 バケットに保存するには、Kinesis Data Firehose を使用してパイプラインを Amazon S3 ストレージに接続できます。 詳細については、「Kinesis Data Firehose 配信ストリームを作成する」を参照してください。

Kinesis Data Firehose は、宛先の S3 バケットに一定の間隔でストリーミングデータを配信します。この間隔は、S3 バッファサイズ、または S3 バッファ間隔 (または両方。最初のメトリクスを超過する方) を使って定義できます。Data Firehose 配信ストリーム内のデータは変換可能です。また、変換を適用する前にソースレコードをバックアップすることもできます。データは暗号化して、Apache Parquet および Apache ORC などのカラムナフォーマットでデータを保存するために、GZip、Zip、または Snappy フォーマットに圧縮することができます。これによって、クエリパフォーマンスが向上し、ストレージフットプリントが削減されます。運用および本番のトラブルシューティングのために、エラーログを有効にするようにしてください。
結論
このブログシリーズのパート 1 では、データレイクをサポートするデータパイプラインの構築方法を説明しました。構築では、Kinesis Data Streams、Kinesis Data Analytics、Kinesis Data Firehose、および Lambda などの AWS の主なサービスを使用しました。パート 2 では、サーバーレスデータレイクをデプロイし、データレイクから実用的な洞察を作成するために主要分析を使用する方法について説明します。
その他のリソース
Langlois, J.A., Rutland-Brown, W. & Wald, M., “The epidemiology and impact of traumatic brain injury: a brief overview,” Journal of Head Trauma Rehabilitation, Vol. 21, No. 5, 2006, pp. 375-378.
Echlin, S. E., Tator, C. H., Cusimano, M. D., Cantu, R. C., Taunton, J. E., Upshur E. G., Hall, C. R., Johnson, A. M., Forwell, L. A., Skopelja, E. N., “A prospective study of physician-observed concussions during junior ice hockey: implications for incidence rates,” Neurosurg Focus, 29 (5):E4, 2010
Daniel, R. W., Rowson, S., Duma, S. M., “Head Impact Exposure in Youth Football,” Annals of Biomedical Engineering., Vol. 10, 2012, 1007.
Greenwald, R. M., Gwin, J. T., Chu, J. J., Crisco, J. J., “Head impact severity measures for evaluating mild traumatic brain injury risk exposure,” Neurosurgery Vol. 62, 2008, pp. 789–79
その他の参考資料
この記事が役に立つと思われる場合は、 Setting Up Just-in-Time Provisioning with AWS IoT Core および Real-time Clickstream Anomaly Detection with Amazon Kinesis Analytics も併せてお読みください。
著者について
 Saurabh Shrivastava は世界各国のシステムインテグレーターと連携するパートナーソリューションアーキテクト/ビッグデータスペシャリストです。Saurabh は AWS のパートナーおよびお客様と連携して、ハイブリッド環境と AWS 環境でスケーラブルアーキテクチャを構築するためのアーキテクチャ面でのガイダンスを提供しています。
Saurabh Shrivastava は世界各国のシステムインテグレーターと連携するパートナーソリューションアーキテクト/ビッグデータスペシャリストです。Saurabh は AWS のパートナーおよびお客様と連携して、ハイブリッド環境と AWS 環境でスケーラブルアーキテクチャを構築するためのアーキテクチャ面でのガイダンスを提供しています。
 Abhinav Krishna Vadlapatla は アマゾン ウェブ サービスのソリューションアーキテクトです。Abhinav は、AWS を使用してスケーラブルでセキュアなソリューションを構築するためのクラウド導入においてスタートアップ企業と小企業をサポートしています。そのかたわらで、料理と旅行を楽しんでいます。
Abhinav Krishna Vadlapatla は アマゾン ウェブ サービスのソリューションアーキテクトです。Abhinav は、AWS を使用してスケーラブルでセキュアなソリューションを構築するためのクラウド導入においてスタートアップ企業と小企業をサポートしています。そのかたわらで、料理と旅行を楽しんでいます。
 John Cupit は AWS の Global Telecom Alliance Team のためのパートナーソリューションアーキテクトです。 John は、クラウドを活用して通信キャリア業界を変えることに情熱を傾けています。 John には大学を卒業した息子と娘がおり、娘は就職していますが、息子はテュレーン大学ロースクールの 1 年生です。 このため、お金もなければ副業する時間もありません。
John Cupit は AWS の Global Telecom Alliance Team のためのパートナーソリューションアーキテクトです。 John は、クラウドを活用して通信キャリア業界を変えることに情熱を傾けています。 John には大学を卒業した息子と娘がおり、娘は就職していますが、息子はテュレーン大学ロースクールの 1 年生です。 このため、お金もなければ副業する時間もありません。
 David Cowden は AWS の新興パートナーと連携するパートナーソリューションアーキテクト/IoT スペシャリストです。David はお客様と連携して、IoT 分野でスケーラブルなアーキテクチャを構築するためのアーキテクチャ面でのガイダンスを提供しています。
David Cowden は AWS の新興パートナーと連携するパートナーソリューションアーキテクト/IoT スペシャリストです。David はお客様と連携して、IoT 分野でスケーラブルなアーキテクチャを構築するためのアーキテクチャ面でのガイダンスを提供しています。
 Josh Ragsdale は AWS のエンタープライズソリューションアーキテクトです。 Josh は非常に大きな規模のクラウド運用モデルへの適応に焦点を当てています。サイクリングと野外で家族と過ごす時間を楽しんでいます。
Josh Ragsdale は AWS のエンタープライズソリューションアーキテクトです。 Josh は非常に大きな規模のクラウド運用モデルへの適応に焦点を当てています。サイクリングと野外で家族と過ごす時間を楽しんでいます。
 Pierre-Yves Aquilanti 博士は AWS の特化型 HPC シニアソリューションアーキテクトです。Pierre-Yves は、石油およびガス業界で、大規模 HPC システムのための R&D アプリケーションを最適化し、アップストリームための機械学習の可能性を実現することに数年間従事しました。彼と彼の家族は、人、文化経験、そして新鮮なドリアンを食べるためにもういちどシンガポールに住みたいと思っています。
Pierre-Yves Aquilanti 博士は AWS の特化型 HPC シニアソリューションアーキテクトです。Pierre-Yves は、石油およびガス業界で、大規模 HPC システムのための R&D アプリケーションを最適化し、アップストリームための機械学習の可能性を実現することに数年間従事しました。彼と彼の家族は、人、文化経験、そして新鮮なドリアンを食べるためにもういちどシンガポールに住みたいと思っています。
 Manuel Puron は AWS のエンタープライズソリューションアーキテクトです。Manuel はクラウドセキュリティと IT サービス管理に 10 年以上携わっており、電気通信業界に重点を置いています。Manuel はビデオゲーム、そして新しい文化を発見するために新たな場所に旅することが好きです。
Manuel Puron は AWS のエンタープライズソリューションアーキテクトです。Manuel はクラウドセキュリティと IT サービス管理に 10 年以上携わっており、電気通信業界に重点を置いています。Manuel はビデオゲーム、そして新しい文化を発見するために新たな場所に旅することが好きです。