Amazon Web Services ブログ
Amazon CloudWatch MCP Server と Amazon Q CLI で SAP 運用を効率化 – Part 4
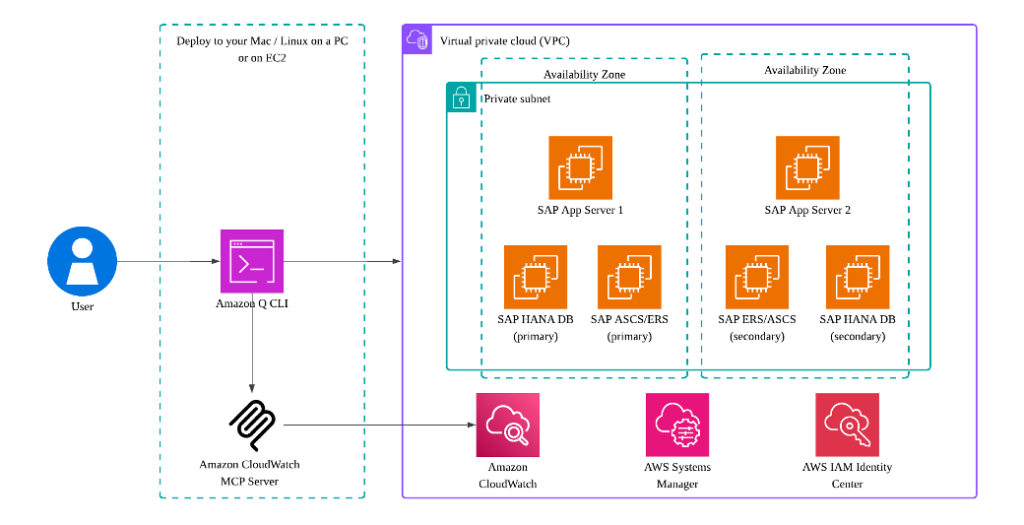
AWS 上の SAP 運用を最適化するには、効率的な監視、トラブルシューティング、およびメンテナンス機能が必要です。part 1 での Amazon CloudWatch Application Insight に関する以前の議論、part 2 での CloudWatch Application Insight を使用して SAP 高可用性を監視する方法、および part 3 での Amazon CloudWatch Model Context Protocol (MCP) Server と Amazon Q for command line (Q CLI) に基づき、この第4回では、これらのツールの高度な実世界のアプリケーションを実演します。実用的なユースケースを通じて、この統合が SAP メンテナンス計画をどのように効率化し、根本原因分析を加速するかを探ります。
Amazon CloudWatch MCP Server と Amazon Q CLI で SAP 運用を効率化 – Part 3
今日の複雑な SAP 環境において、効率的な運用と迅速なトラブルシューティングは、ビジネス継続性にとって極めて重要です。SAP オブザーバビリティ(part-1 英語)と Amazon CloudWatch Application Insights の機能(part-2 英語)に関する以前の議論に基づき、この第3回では、チームが SAP ランドスケープを管理する方法を革新する強力なツールの組み合わせを紹介します:Amazon CloudWatch Model Context Protocol (MCP) Server と Amazon Q for command line (Q CLI) です。
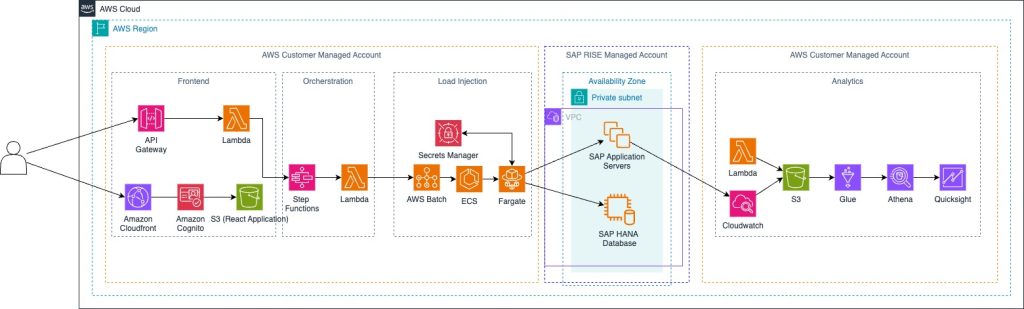
SAPの負荷テスト:AWSによるサーバーレスアプローチ
SAPシステムの適切な負荷テストを実施することは、ピーク使用時にシステムがビジネスのパフォーマンスと信頼性の期待に応えられることを保証する主要な要因です。負荷テストが必要となる典型的なシナリオには、新しい会社/国の展開、ECCからS/4HANAへのソフトウェアリリースアップグレード、アプリケーションパッチ(例:サポートパッケージ)、S/4HANA変革プロジェクト、またはSAP RISEへの移行があります。このような大規模な変更後の安定した運用を確保するため、潜在的なパフォーマンス関連の問題を回避するために、本番カットオーバー前に負荷テストを実行することが推奨されます。このブログでは、オンプレミスまたはRISEにデプロイされたSAP ERPシステムに異なるタイプの負荷を注入するために、AWS上で負荷テストプラットフォームを実装し使用する方法を学びます。
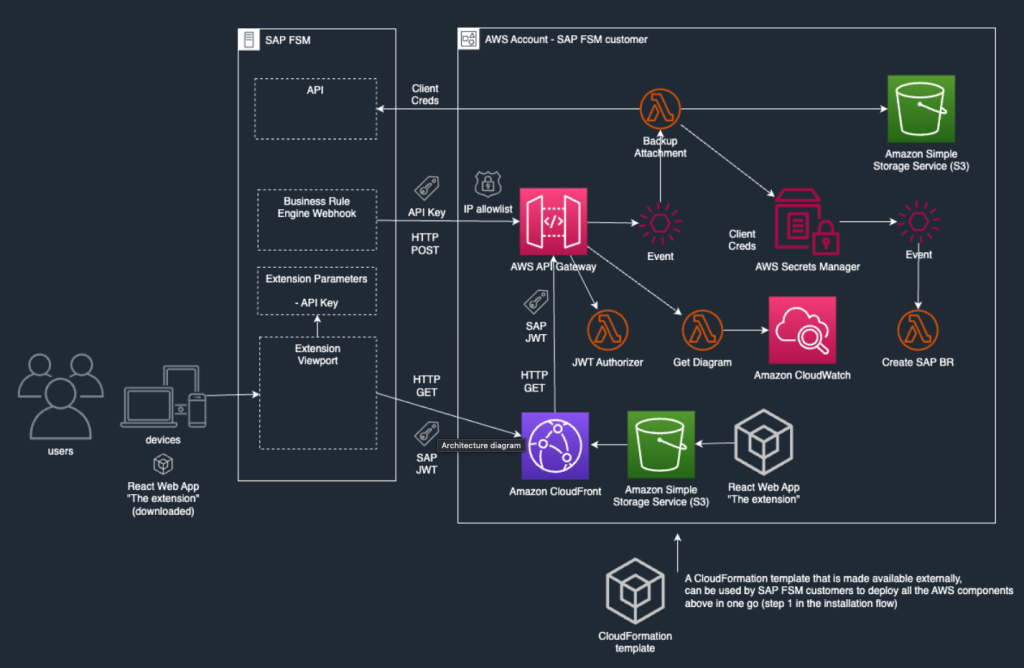
SAP Field Service ManagementをAWSで拡張:添付ファイルストレージのためのクリーンコアアプローチ
フィールドサービス業務のデジタル変革により、資産の生成が指数関数的に増加し、それに伴いストレージ要件も増大しています。SAP Field Service Management(SAP FSM)を使用する組織は、フィールドサービス技術者が取得するデジタル資産の管理において、ますます大きな課題に直面しています。これらの資産には、機器の写真、フォーム、顧客の署名、その他現場で管理される重要な資産が含まれます。この投稿では、Amazon Web Services(AWS)を活用して、SAP Clean Core Extensibilityの原則に従いながら、SAP FSM向けのスケーラブルでコスト効率的な添付ファイルストレージソリューションを作成する方法を実証します。

Deep Dive: Amazon ECS マネージドインスタンスのプロビジョニングと最適化
Amazon Elastic Container Service (Amazon ECS) マネージドインスタンスは、完全マネージド型のコンピューティングオプションで、インフラストラクチャ管理のオーバーヘッドを排除しながら、Amazon Elastic Compute Cloud (Amazon EC2) の幅広い機能にアクセスできます。これには、インスタンスタイプの選択、予約済み容量へのアクセス、高度なセキュリティと監視設定の活用などの柔軟性が含まれます。ECS マネージドインスタンスは Amazon Web Service (AWS) にオペレーションを委託することでお客様の迅速な開始を支援します。総所有コストを削減し、チームがイノベーションをもたらすアプリケーションの構築に専念できるようします。

AWS DMS データ検証:カスタムサーバーレスアーキテクチャ
本投稿は、Anil Malakar と Mahesh Kansara と Prabodh Pawar による記 […]

AWS DMS Schema Conversion CLI を使用したデータベースの評価と移行
本投稿は、 Nelly Susanto による記事 「Assess and migrate your data […]

AWS DMS によるリアルタイムでの Iceberg の取り込み
本投稿は、 Caius Brindescu と Mahesh Kansara による記事 「Real-time […]

東京大学 松尾・岩澤研究室主催の AI エンジニアリング実践講座にて、1400 名を超える受講者に AWS 上でのクラウド開発を体験していただきました [ 後片づけ編 ]
本ブログシリーズでは、2025 年 4 月から 7 月にかけて実施した東京大学 松尾・岩澤研究室の AI エンジニアリング実践講座において、 AWS クラウドを活用した実践的な学習環境を用意し、1400 名を超える受講申し込み者に対して、個別のAWSアカウントを提供する大規模なオンライン講義を開講した取り組みを全 3 回に分けてまとめたものです。
3 回目は、環境の後片付けの実施方法とそこで得た知見について共有します。

東京大学 松尾・岩澤研究室主催の AI エンジニアリング実践講座にて、1400 名を超える受講者に AWS 上でのクラウド開発を体験していただきました [ 演習、運用編 ]
本ブログシリーズでは、2025 年 4 月から 7 月にかけて実施した東京大学 松尾・岩澤研究室の AI エンジニアリング実践講座において、 AWS クラウドを活用した実践的な学習環境を用意し、1400 名を超える受講申し込み者に対して、個別のAWSアカウントを提供する大規模なオンライン講義を開講した取り組みを全 3 回に分けてまとめたものです。
2 回目は、各受講生に割り当てる AWS アカウントに対する権限の適用と管理方法について詳しく説明します。