Amazon Web Services ブログ
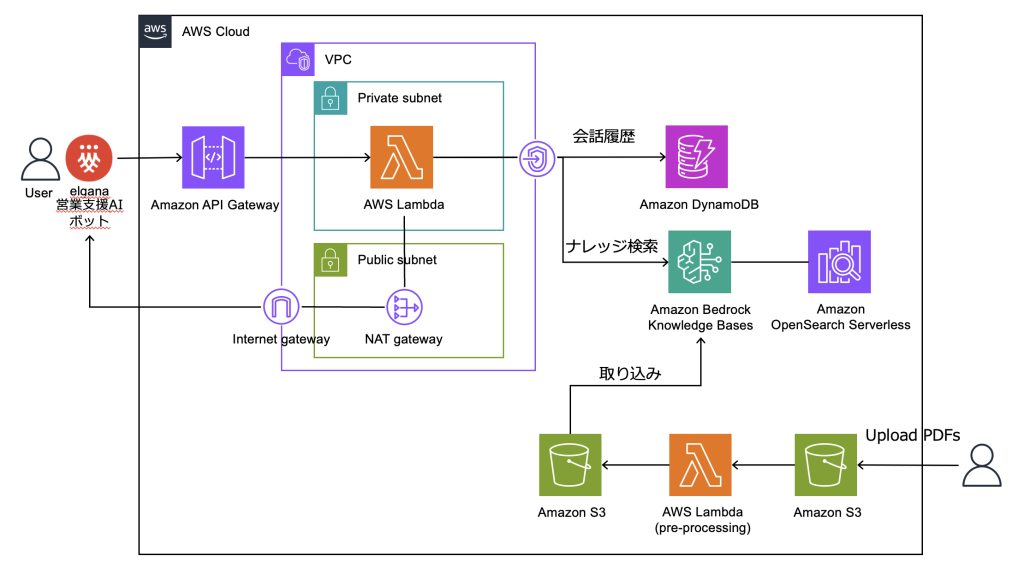
NTT西日本の AWS 事例:Amazon Bedrock Knowledge Bases を活用した営業支援 AI ボットの開発
本ブログでは、NTT西日本の寄稿により、Amazon Bedrock Knowledge Bases を活用した営業支援 AI ボットについて、取り組み背景、実現方法、トライアル結果について解説します

都市規模のイベントを守る:AWS re:Invent における物理セキュリティと論理セキュリティの統合アプローチ
AWS re:Invent 2024 は 6 万人の現地参加者と 40 万人のオンライン参加者を迎える都市規模のイベントでした。このブログでは、物理セキュリティと論理セキュリティを統合した包括的なアプローチを紹介します。コマンドポスト (統制本部) を中心に、監視カメラ、K9 ユニット、ドローン、ワイヤレスセキュリティオペレーションセンター (WiSOC) などを活用し、参加者とデータを多層的に保護する仕組みを解説します。

AWS re:Invent 2025: 4つの変革的テーマで学ぶセキュリティセッションガイド
AWS re:Invent 2025 のセキュリティトラックでは、80 以上のセッションを通じて最新のクラウドセキュリティを学べます。AI のセキュリティ確保と活用、大規模なセキュリティアーキテクチャ設計、セキュリティ文化の構築、AWS セキュリティイノベーションという 4 つの変革的テーマで構成され、生成 AI やエージェンティック AI の保護、ネットワークセキュリティの強化、ポスト量子暗号などの最先端技術を実践的に学べます。
AWS で利用できる Anthropic ソリューションのご紹介
皆さんこんにちは、ソリューションアーキテクトの金杉と石見です。 AWS では、生成 AI を活用したお客様のビ […]

Kiro : コードは仕様と一致していますか? 〜プロパティベーステストで「正しさ」を測定する〜
Kiro は 7 月にローンチした際に仕様駆動開発(Spec Driven Development、以下、SDD)を導入したエージェント型 IDE です。SDD では、Kiro のエージェントがコードを書く前にソフトウェアの完全な仕様を作成します。これにより、開発前にエージェントと繰り返しやり取りしながら、アプリケーションの要件を完全に捉えられているか確認できます。Kiro はその要件ドキュメントを実行して Spec (仕様)に変換し、生成されたコードが仕様に準拠しているかをチェックします。Kiro はこの実行可能な仕様を使ってプログラムをテストしますが、その際にプロパティベーステストと呼ばれる手法を使用します。私たちはこの手法は、バグ発見により効果的であると考えています。

Claude Code on AWS パターン解説 – Amazon Bedrock / AWS Marketplace
本稿では、AWS 上で Claude Code を活用する 2 つの主要パターンを解説しています。Amazon Bedrock との連携は従量課金でスモールスタート可能、セキュリティ要件が厳しい場合に適しており、AWS Marketplace 経由の購入は GUI アプリケーション含むフル機能と定額制による予算管理の簡素化が特徴です。
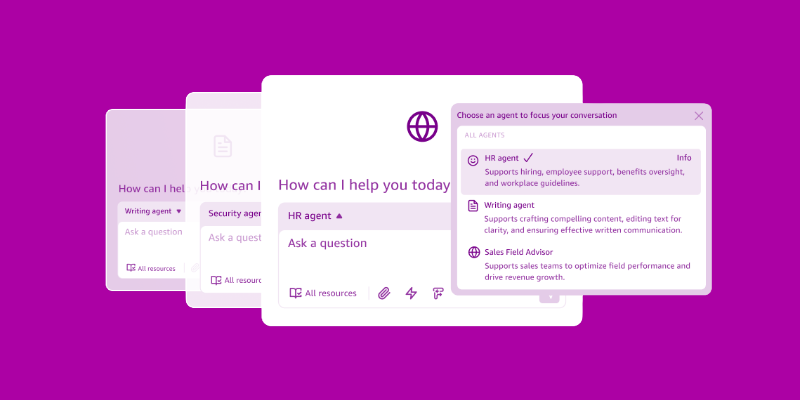
質問への回答とアクションを実行するエージェント型チームメイト Amazon Quick Suite の発表
Amazon Quick Suiteを発表しました。これは、仕事における質問への回答やアクションの実行を支援する新しいAIベースのツールスイートです。
このツールスイートにより、ユーザーは複数のアプリケーションを行き来することなく、単一のワークスペースでAIサポートによるリサーチ、ビジネスインテリジェンス、自動化機能を活用できるようになります。
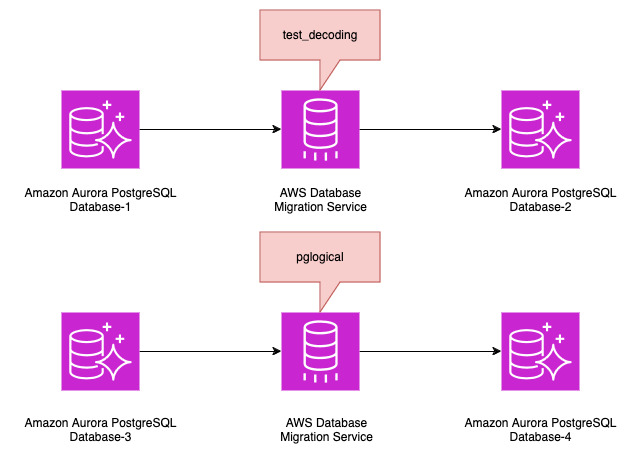
Amazon Aurora PostgreSQL での AWS DMS を使用したデータ移行における test_decoding プラグインと pglogical プラグインの比較
この記事は、”Comparison of test_decoding and pglogical […]

Amazon Q Developer の IDE プラグインから Kiro に乗り換える準備
本記事では、Amazon Q Developer の IDE プラグインから Kiro への移行方法を解説します。既存の Rules 機能は Steering として進化しています。MCP やコンテキスト管理機能も継続して利用可能です。

【開催報告】 アフラック生命保険株式会社様 オペレーショナル・レジリエンス ワークショップ
金融機関では近年、デジタル化の進展に伴いリスク環境が急速に変化しています。障害への未然防止策に重点を置いた従来的なリスク管理や事業継続計画(BCP)だけでは、重要な業務を提供し続けられない可能性が出てきており、障害の早期復旧や影響範囲の軽減確保を重視する、オペレーショナル・レジリエンスという考え方が近年注目されています。
AWS では、オペレーショナル・レジリエンスに関心の高いお客様向けに、AWS の取り組みを紹介するオペレーショナル・レジリエンス ワークショップを提供しております。この度、アフラック生命保険株式会社様と共に、本ワークショップを2025年9月中に2回開催しました。本稿ではこちらのワークショップの開催報告をお届けします。