Amazon Web Services ブログ
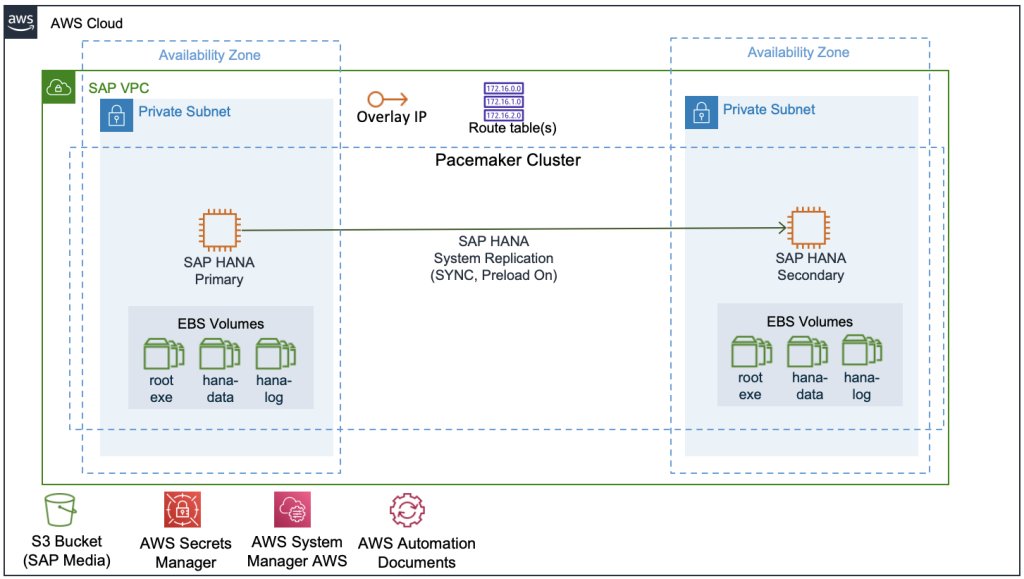
SSM と nZDT を使用した SAP HANA DB HA構成 パッチ適用自動化
SAP HANA データベースを最新のパッチで常に最新の状態に保つことは、セキュリティ、パフォーマンス、信頼性を維持するために非常に重要です。しかし、従来のデータベースパッチ適用では、多くの場合、大幅なダウンタイムが必要となり、ビジネスオペレーションに影響を与えます。以前の AWS ガイダンスでは、さまざまな自動化アプローチを取り上げましたが、この投稿では、ネイティブ AWS サービスを使用して高可用性 SAP HANA データベースのほぼゼロダウンタイムを実現する新しいソリューションを紹介します。

Amazon MWAA Serverless の紹介
本日、AWS は Amazon Managed Workflows for Apache Airflow (MWAA) Serverless の提供を発表しました。これは MWAA の新しいデプロイメントオプションで、Apache Airflow 環境の運用オーバーヘッドを排除しながら、サーバーレススケーリングによってコスト最適化を実現します。この新しいサービスは、データエンジニアと DevOps チームがワークフローのオーケストレーションで直面する主な課題、つまり運用スケーラビリティ、コスト最適化、アクセス管理を解決します。

Amazon Connect の通話録音の保存期間をカスタマイズする方法
コンタクトセンター、特に BPO 企業では、事業部門ごとの要件など、異なる通話録音の保持要件が要求されることがあります。コンプライアンスへの違反は罰金や評判低下につながる可能性がありますし、不要な録音保持はコストやプライバシー問題を引き起こします。このブログでは、単一の Amazon Connect インスタンス内で異なる通話録音保持ポリシーを適用し、コンプライアンスの維持とコスト最適化を両立させる方法を紹介します。

re:Invent 2025 クラウド財務管理セッション完全ガイド:参加前に押さえておきたいポイント
本投稿は、2025年 10 月 6 日に公開、11 月 3 日に更新された Your Ultimate Guide to Cloud Financial Management sessions at re:Invent 2025: Know Before You Go を翻訳したものです。
Cloud Financial Management (CFM) の学習とネットワーキングの時間を re:Invent 2025 で最大限に活用する準備はできていますか?例年通り、今年の CFM セッションを最大限に活用し、スケジュールを計画するための包括的なガイドを作成しました。今年のカタログには、ブレイクアウト、チョークトーク、ワークショップ、ビルダーズセッション、コードトークなど、さまざまな形式のコンテンツがエキサイティングに組み合わされています。

道に迷わないために: Kiro のチェックポイント機能の紹介
このブログでは、Kiro のチェックポイント機能についてご紹介します。チェックポイント機能は、開発セッション中の任意の時点に Kiro の変更を巻き戻す力を与えます。Kiro がコードベースを変更すると、チャット履歴に自動的にチェックポイントマーカーが作成されます。ビデオゲームのオートセーブポイントのようなものだと考えてください。物事がうまくいかず、想定以上のダメージを受けた場合、以前のチェックポイントに戻って別のアプローチを試すことができます。

Kiro を組織で利用するためのセキュリティとガバナンス
本ブログは Kiroweeeeeek (X:#kiroweeeeeeek) の第 3 日目です。本ブログでは、Kiro を組織で利用するにあたって気になるセキュリティとガバナンス機能についてご紹介します。

三遠ネオフェニックス様の AWS 生成 AI 事例「Amazon Bedrock と Step Functions を活用したバスケットボール・スカウティングレポート自動生成システムの構築」のご紹介
本記事では、三遠ネオフェニックス様が、AWS Step Functions と Amazon Bedrock を活用し、生成 AI による AI Analyst 機能を構築されましたので、その事例をご紹介します。

AWS Weekly Roundup: AWS Lambda、ロードバランサー、Amazon DCV、Amazon Linux 2023 など (2025 年 11 月 17 日)
AWS re:Invent まであと数週間、私のチームはカンファレンスのコンテンツの準備を全力で進めています。 […]
AWS Lambda が、SQS イベントソースマッピングのプロビジョニングモードでイベント処理を強化
2025 年 11 月 14 日、Amazon Simple Queue Service (Amazon SQ […]

AWS IoT Core Device Location と Amazon Sidewalk の統合のご紹介
2025 年 11 月 13 日、AWS IoT Core Device Location サービスを使用して […]