Amazon Web Services ブログ
Amazon Relational Database Service を使用したシャーディング
水平パーティション分割とも呼ばれるシャーディングは、リレーショナルデータベースの一般的なスケールアウトアプローチです。Amazon Relational Database Service (Amazon RDS) は、クラウドでシャーディングを使いやすくするための優れた機能を提供するマネージド型リレーショナルデータベースサービスです。この記事では、Amazon RDS を使用してデータストレージの高いスケーラビリティ、高可用性、およびフォールトトレランスを実現するために、シャードデータベースアーキテクチャを実装する方法について説明します。Amazon RDS をデータベースシャードとしてデプロイする際のスキーマ設計とモニタリングメトリクスに関する考慮事項について説明します。また、リシャーディングの課題についても概説し、Amazon RDS でのプッシュボタンによるスケールアップおよびスケールアウトソリューションを紹介します。
シャードデータベースアーキテクチャ
シャーディングは、データをより小さなサブセットに分割し、それらを物理的に分離された多数のデータベースサーバーに分配する手法です。各サーバーはデータベースシャードと呼ばれます。すべてのデータベースシャードは通常、同レベルのパフォーマンスを生成するために、同じタイプのハードウェア、データベースエンジン、およびデータ構造を持っています。ただし、それらはお互いの知識を持っておらず、その点が、データベースクラスタリングやレプリケーションなどの他のスケールアウトアプローチとシャーディングを区別する重要な特性です。
シェアードナッシングモデルにより、スケーラビリティとフォールトトレランスの点で、シャードデータベースアーキテクチャは独自の強みを発揮します。データベースメンバー間のコミュニケーションや競合を管理する必要はありません。それに伴う複雑さとオーバーヘッドは存在しません。1 つのデータベースシャードにハードウェアの問題があるか、フェールオーバーを経ても、単一障害点やスローダウンは物理的に分離されているため、他のシャードは影響を受けません。アプリケーション層に存在するデータマッピングとルーティングロジックの一部から発生するレイテンシーが非常に少ないという条件で、シャーディングは必要なだけのデータベースサーバーを利用する可能性があります。
ただし、シェアードナッシングモデルでは、シャーディングという避けられない欠点も発生させます。そこでは、さまざまなデータベースシャードに分散しているデータが分離されています。複数のデータベースシャードからデータを読み取りまたは結合するためのクエリは、特別に設計する必要があります。通常、片方のシャードでのみ動作するピアよりも高いレイテンシーが発生します。すべてのデータの一貫したグローバルなイメージを提供できないことは、データ分析機能が通常データセット全体に対して実行されるオンライン分析処理 (OLAP) 環境で積極的な役割を果たすことにおいて、シャードデータベースアーキテクチャを制限します。
オンライントランザクション処理 (OLTP) 環境では、大量の書き込みまたはトランザクションが単一のデータベースの容量を超えることがあり、スケーラビリティが懸念される場合、シャーディングは常に追求する価値があります。Amazon RDS の登場により、データベースの設定と運用は大幅に自動化されました。これにより、シャードデータベースアーキテクチャを扱う作業がずっと簡単になります。Amazon RDS は、Amazon RDS for MySQL、MariaDB、PostgreSQL、Oracle、SQL Server、およびAmazon Aurora を含むデータベースエンジンのセットを提供します。これらのいずれかを、シャードデータベースアーキテクチャのデータベースシャードの構成要素として使用できます。
Amazon RDS を使用して構築されたシャードデータベースアーキテクチャの例を見てみましょう。AWS クラウドコンピューティング環境のコンテキストでは、データフローパス内での位置はいくつかの特徴があります (次の図に示します)。
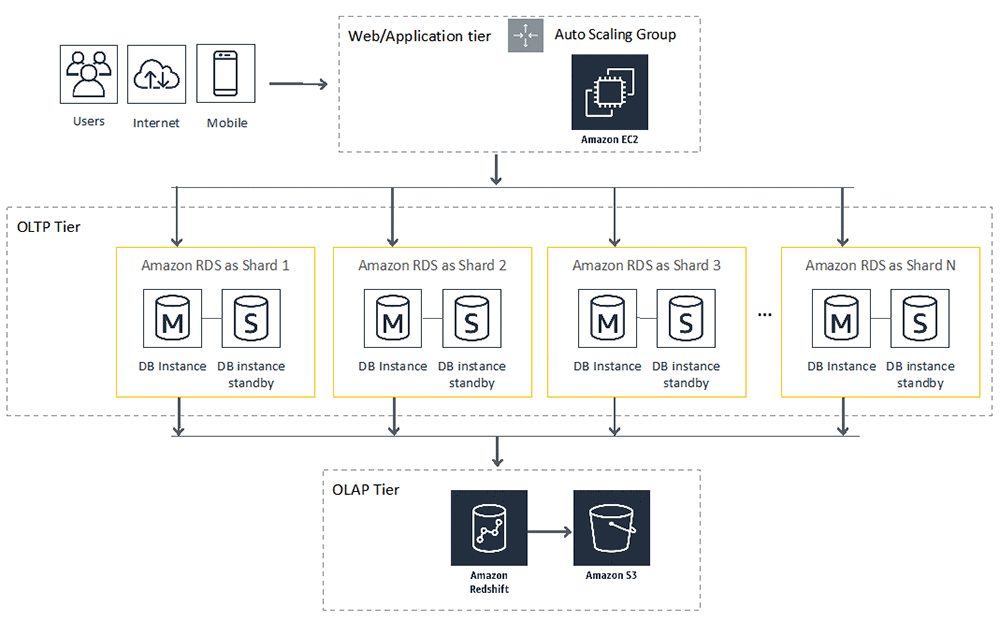
- Auto Scaling 機能を備えた Amazon EC2 インスタンスのグループでホストされているウェブアプリケーションを介してデータがシステムに入力されます。
- データストレージは、さまざまなビジネス要件および所有権要件を満たすために OLTP 環境が OLAP 環境から分離されている層になっています。
- OLTP 環境ではデータベースシャーディングを使用します。これは、高いスケーラビリティで書き込みスループットに対する増大する需要を満たすために Amazon RDS で構築されたデータベースのグループで構成されています。Multi-AZ 機能を使用してデプロイされたスタンドアロンデータベースを使用した高可用性を実現するために各データベースシャードを構築します。注意: データベースシャードを構築するために Aurora DB クラスターを選択した場合は、プライマリインスタンスでリードレプリカを設定することによっても高可用性を実現できます。
- スケジュールに基づいて、データが OLTP 環境から OLAP 環境に取り出されます。Amazon Redshift を使用して、すべてのデータベースシャードののデータに対応し、データ分析機能に時間一貫性のあるグローバルデータセットを構築できます。集約されたデータ結果セットは、データ共有、他の分析サービス、および長期保存のために Amazon S3 にプッシュされます。
データパーティション分割とスキーマ設計
シャードデータベースアーキテクチャを実装するための前提条件は、データを水平方向にパーティション分割し、データパーティションをデータベースシャードに分配することです。リストパーティション分割、範囲パーティション分割、ハッシュパーティション分割など、さまざまな方法でテーブルをパーティション分割できます。各データベースシャードが、別々のテーブルの形式で 1 つ以上のテーブルパーティションに対応できるようにすることができます。
次の図は、customer_id をパーティションキーとして使用した、Invoice テーブルの水平パーティション分割の例です。
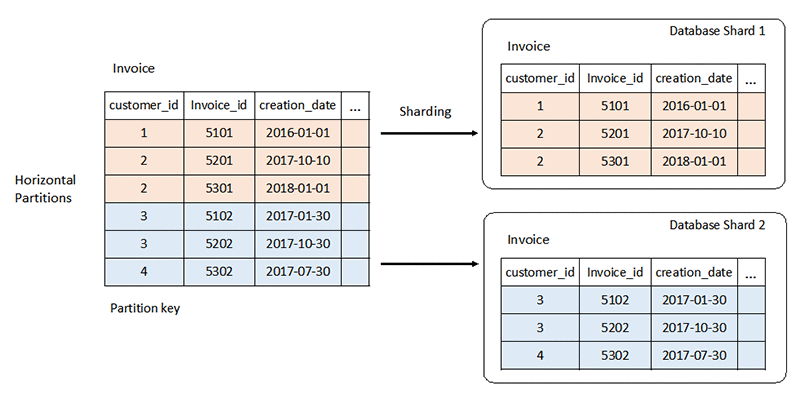
複数のテーブルが関与し、外部キーの関係によってバインドされている場合は、関与するすべてのテーブルで同じパーティションキーを使用することで水平パーティション分割を実現できます。複数のテーブルにまたがるが 1 つのパーティションキーに属するデータは、1 つのデータベースシャードに分配されます。次の図は、一連のテーブルにおける水平パーティション分割の例を示しています。
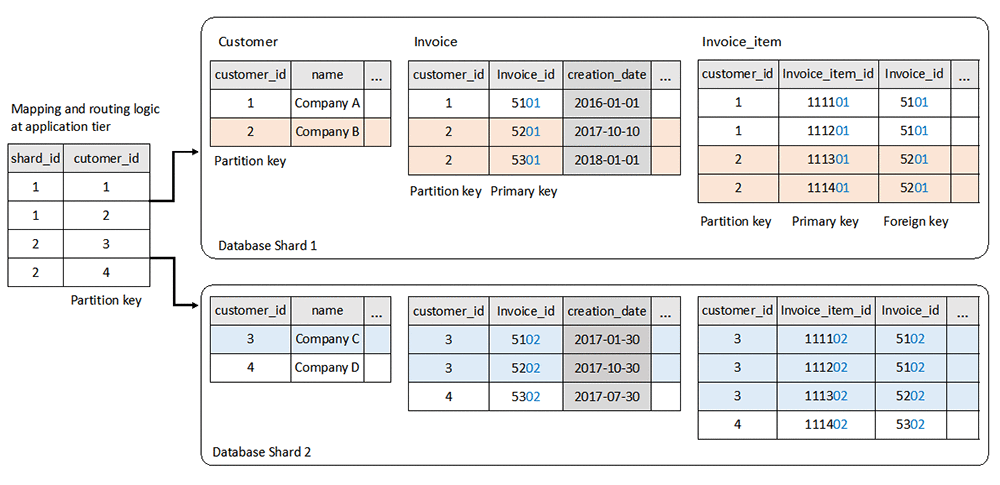
使用した基本設計手法は次のとおりです。
- 各データベースシャードには、シャードに存在するパーティションキーを保管するためのパーティションキーマッピングテーブル、
顧客が含まれています。アプリケーションはすべてのシャードからこのテーブルを読み取り、パーティションキーをデータベースシャードにマップするデータマッピングロジックを構築します。アプリケーションは、定義済みのアルゴリズムを使用してパーティションキーがどのデータベースシャードにあるかを判断できるため、このテーブルを省略することができます。 - パーティションキー
customer_idは、他のすべてのテーブルにデータ隔離ポイントとして追加されます。これは、さまざまなデータベースシャードへのデータおよびワークロードの分散に直接影響します。単一パーティションを対象としたクエリにはパーティションキーが含まれているため、アプリケーション層のデータルーティングロジックはそれを使用してデータベースシャードにマップし、それに応じてクエリをルーティングできます。 - データがあるシャードから別のシャードに移行されるとき、またはデータが OLAP 環境でマージされるときにキーの競合を回避するために、すべてのデータベースシャードにわたってプライマリキーに固有のキー値があります。例えば、Invoice テーブルのプライマリキー
invoice_idは、インターリーブされた番号を使用し、最後の 2 桁はshard_id用に予約されています。もう 1 つの一般的な方法は、プライマリキーとして GUID または UUID を使用することです。 - タイムスタンプデータ型の列は、テーブルの中でデータ整合性ポイントとして定義できます。必要に応じて、すべてのデータベースシャードからグローバルビューにデータをマージするための基準として機能します。例えば、データが OLAP 環境に取り込まれると、Invoice テーブルの
creation_dateが、引き込みクエリのフィルターとして使用され、すべてのシャードに対して一貫した時間範囲が指定されます。
適切に設計されたシャードデータベースアーキテクチャにより、データとワークロードをすべてのデータベースシャードに均等に分配することができます。さまざまなシャードに着くクエリは、予想されるパフォーマンスレベルに一貫して到達することができます。シャード上のデータパーティションの数が増えると、データベースエンジンのリソース消費量が増加し、大規模なハードウェアでも競合箇所やボトルネックが発生します。シャードごとに使用するデータパーティションの数を決定するには、通常、クエリパフォーマンスを最適化するというコミットメントと統合するという目標との間でバランスをとり、コスト削減のためのリソース使用を改善します。
Amazon RDS をデータベースシャードとしてデプロイするときは、データベースエンジンのタイプ、DB インスタンスクラス、および RDS ストレージも考慮する必要があります。データベース設定を簡単に管理できるように、Amazon RDS には DB パラメータグループが用意されています。これには、すべてのデータベースシャードに一貫して適用できる必要な設定値のセットが含まれています。
スケーラビリティの監視
1 つのシャードからのメトリクス (システムリソース使用量やデータベーススループットなど) を監視することは、1 つのシャードを他のシャードと比較してシステムにホットスポットがあるかどうかを確認でき、グローバルな観点からはより意味があります。データを監視するための適切な保存期間を設定することも有益です。その後、履歴情報を使用して傾向を分析し、システムを変更に適応させるのに役立つキャパシティを計画できます。
マネージドサービスとして、Amazon RDS は自動的にモニタリングデータを収集し、それを Amazon CloudWatch に公開します。CloudWatch は、データベースおよびシステムレベルでメトリクスの統一ビューを提供します。一部のメトリクスはすべてのデータベース共通のものですが、他のメトリクスは特定のデータベースエンジンに固有のものです。メトリクスの完全なリストについては、Amazon RDS と Amazon Aurora のドキュメントを参照してください。
CPUUtilization、FreeableMemory、ReadIOPS、WriteIOPS、FreeStorageSpace など、システムリソース全体の使用量を監視するメトリクスを常にお勧めします。これらのメトリクスは、データベースシャードのリソース使用量が容量内であるかどうか、および成長の余地があるかどうかを示す指標です。システムリソースの消費は、シャードデータベースアーキテクチャをさらにスケールするか、そうでなければ統合する必要があることを正当化するための重要な要素です。
次は CloudWatch ダッシュボードの例です。これにより、シャードデータベースアーキテクチャを詳細に確認できます。これは、すべてのデータベースシャードからのリアルタイムおよび過去のメトリクスデータを 1 つのグラフにまとめます。
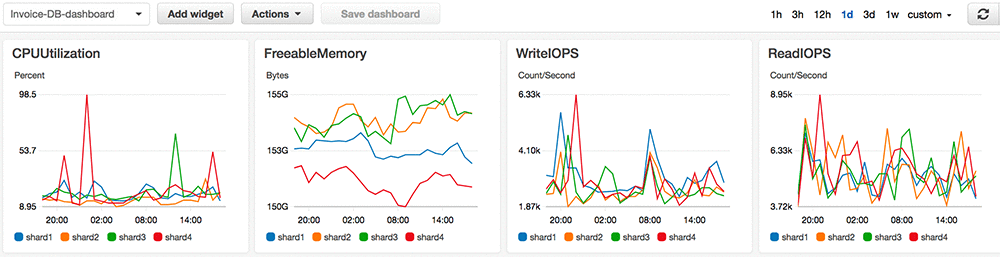
データベースシャードのシステムリソース使用量が多く、より多くの処理能力が必要な場合は、スケールアップまたはスケールアウトのどちらかになります。Amazon RDS にはプッシュボタン式のスケールアップオプションがあります。これを使用してDB インスタンスクラスをより多くの CPU と RAM を備えたより大きなハードウェアに変更したり、DB インスタンスストレージを変更したりしてより多くの記憶領域と IOPS 容量を確保できます。使用可能なインスタンスクラスの選択は、データベースエンジンやデータベースのバージョンによって異なります。AWS マネジメントコンソールはそれを確認するのに適した場所です。
データベースシャードを構築するために Amazon RDS for MySQL または PostgreSQL を選択した場合は、もう 1 つのスケールアップオプションがあります。Amazon Aurora DB クラスターへの移行です。Aurora DB クラスターは、Amazon RDS DB インスタンスよりも高いパフォーマンスと IOPS キャパシティを実現するために、クラスター化されたストレージボリュームの上にある複数のデータベースインスタンスで構成できます。Amazon RDS には、Aurora リードレプリカを作成するためのプッシュボタンオプションがあります。このオプションは、MySQL または PostgreSQL の Amazon RDS DB インスタンスから Aurora リードレプリカにデータを移行するためのレプリケーションプロセスを設定します。データの移行が完了したら、Aurora リードレプリカをスタンドアロン Aurora DB クラスターに昇格させることができます。
リシャーディング
データベースシャードのスケールアウトオプションは、リシャーディング、つまり再度シャーディングを行うこととして知られています。広義には、リシャーディングは、シャードデータベースアーキテクチャでシャード数を調整することを目的としたすべての手順を指すこともあります。これらの手順には、新しいシャードの追加、1 つのシャードの複数のシャードへの分割、または複数のシャードの 1 つへのマージが含まれます。フォーマットは異なりますが、これらの手順は本質的に同じタイプの操作を実行する必要があります。つまり、既存のデータをあるシャードから別のシャードに移行することです。データが絶えずアクセスされ変更されている本番データベースでは、最小のダウンタイムでデータを移行することはリシャーディングのため常に困難な作業です。
Amazon RDS は、リシャーディングを容易にするために多大な努力を払っています。 Amazon RDS for MySQL、MariaDB、PostgreSQL、Amazon RDS はプッシュボタン式のスケールアウトオプション (リードレプリカ) を提供し、1 つのスタンドアロンデータベースを複数の新しいデータベースに分割します。次の図は、データベース間でデータを移行するためのデータ複製手法としてリードレプリカを使用する、リシャーディングのワークフロー例を示しています。
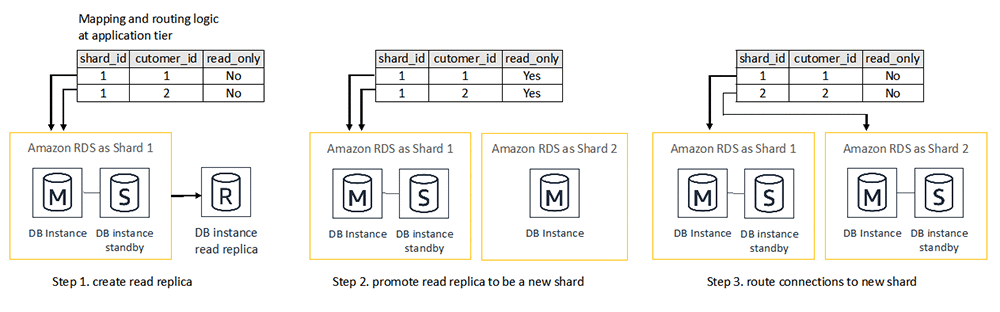
- リードレプリカは、マスターデータベースからデータを継続的に複製するために作成します。
- マスターデータベースは、リードレプリカが同期して新しいスタンドアロンデータベースに昇格できるように、書き込みアクティビティを保留します。この間、アプリケーション層のマッピングおよびルーティングロジックは、マスターデータベース上の複数のデータパーティションのステータスを読み取り専用に更新します。
- データマッピングおよびルーティングロジックは、接続を新しいデータベースにルーティングするように変更されます。
データベースシャードを構築するために Amazon Aurora DB クラスターを選択した場合、そのリードレプリカはストレージボリュームをプライマリインスタンスと共有します。したがって、それらを使用して Aurora クラスター間でデータを複製することはできません。代わりに、Amazon RDS はソースデータベースと同じデータで新しい Amazon Aurora DB クラスターを作成するためのクローンデータベース機能を提供します。Aurora MySQL DB クラスターの場合、データを別の新しい Aurora MySQL DB クラスターに複製するために MySQL レプリケーションを設定するオプションもあります。
既存のデータベーステクノロジを使用してデータを複製することに加えて、リシャーディングでは AWS Database Migration Service (AWS DMS) やユーザー定義のデータ抽出プロセスなど、データベースシャード間でデータを移行する他のツールも利用できます。次の図は、一度に 1 つのデータパーティションを移行するツールベースのリシャーディングワークフローの例です。
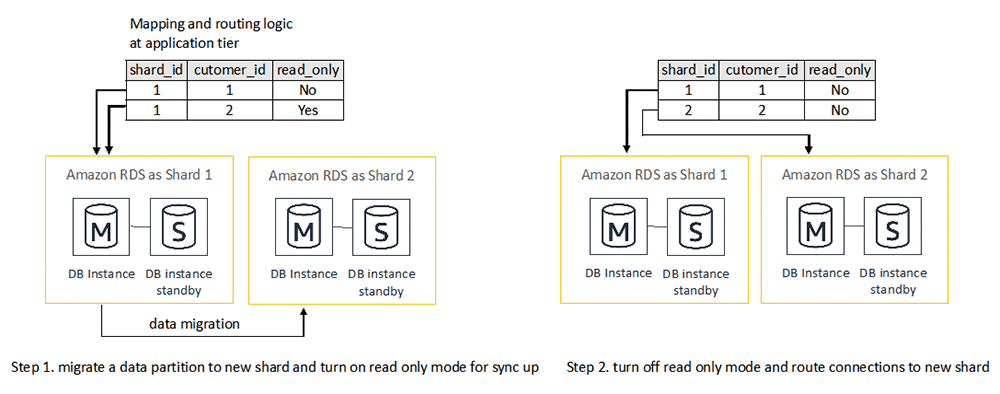
- データ移行ツールは、あるデータベースシャードから別のデータベースシャードにデータパーティションを複製するように設定されています。アプリケーション層のマッピングおよびルーティングロジックは、データパーティションのステータスを読み取り専用に更新します。その後、データ移行ツールは 2 つのデータベースシャードの間でデータを同期させることができます。
- データの同期後、アプリケーション層のデータマッピングおよびルーティングロジックは、データパーティションのマッピングとステータスを更新して、新しいデータベースシャードで有効になるようにします。
ツールベースのリシャーディング手法には、各データパーティションを個別に移行できるため、柔軟性があります。1 つのデータパーティションが移行されている間、それは読み取り専用モードになりますが、アプリケーションはそのデータをまだ読み取ることができます。他のデータアプリケーションは読み取りと書き込みの両方でアクセス可能なままであり、全体的な共有データベースアーキテクチャの可用性は保証されます。
データベースベースのリシャーディング手法では、新規データベースをスピンオフするときに、データベースシャード上の複数のデータパーティションに書き込みアクティビティの停止時間を設定します。新しいデータベースが稼働した後は、元のデータベースから複製されたすべてのデータパーティションが含まれますが、そのうち一部のみが使用されます。したがって、重複したデータをクリーンアップする必要があります。
まとめ
この記事では、リレーショナルデータベースが高いスケーラビリティを実現するためのアプローチとしてのシャーディングについて説明しました。Amazon RDS を使用してクラウドでシャードデータベースアーキテクチャを実装するユースケースの例と、それがデータストレージとアナリティクスのワークフローにどのように適合するかについて学びました。また、非常に自動化された方法でデータベースシャードを管理、モニタリング、スケールアップ、スケールアウトするために RDS が提供するさまざまな機能についても学びました。
この記事を読むことで、シャーディングおよび AWS クラウドコンピューティング環境での使用がいかに簡単になるかについての理解を深めてもらえたら幸いです。ご不明な点がございましたら、お気軽にコメントをお寄せください。
著者について
Lei Zeng は、AWS のシニアデータベースエンジニアです。