Amazon Web Services ブログ
大規模言語モデルを Amazon SageMaker 上で学習する際のベストプラクティス
本稿は 2023 年 3 月 6 日に AWS Machine Learning Blog で公開された “Training large language models on Amazon SageMaker: Best practices” を翻訳したものです。
言語モデルとは自然言語を用いて、連続するトークンの後に続くトークンを推測するような統計的手法です。大規模言語モデル (LLMs) は数億個 (BERT) から1兆個 (MiCS) 以上のパラメータを持つニューラルネットワークベースの言語モデルであり、その規模の大きさからシングル GPU での学習は現実的ではありません。LLM はその生成能力からテキスト合成、要約、機械翻訳などのタスクに広く用いられています。
LLM と学習データのサイズは諸刃の剣です。サイズが大きいことはモデリングの質を高める一方で、インフラストラクチャの課題を伴います。モデルそのものが大きすぎて、1 つの GPU デバイスのメモリや複数の GPU インスタンスの複数のデバイスに収まらないことがよくあります。これらのことから、機械学習 (ML) に特化したインスタンスからなる、大規模なクラスタ上で LLM を学習する必要があります。ここ数年、数多くのお客様が LLM の学習に AWS クラウドを利用しています。
本記事では、Amazon SageMaker Training で LLM の学習を成功させるための Tips とベストプラクティスについて深く掘り下げます。SageMaker Training は、マネージド型バッチ ML コンピュートサービスであり、インフラストラクチャを管理する必要なしで、大規模なモデルのトレーニングとチューニングにかかる時間とコストを削減することができます。 Amazon SageMaker を使うと、たった 1 回の起動コマンドで、選択したタスクを実行するために完全に機能する、一時的なコンピュートクラスターを起動することができます。また、メタストア、マネージド I/O、配布などの ML 機能を利用することもできます。本記事では、LLM 学習ワークロードのすべてのフェーズをカバーし、関連するインフラ機能とベストプラクティスについて説明しています。この記事に含まれるベストプラクティスの一部では、特に ml.p4d.24xlarge インスタンスに言及していますが、ほとんどはどのインスタンスタイプにも適用可能です。これらのベストプラクティスにより、SageMaker 上で数千万から数億のパラメータ規模の LLM をトレーニングすることができます。
本記事で扱う範囲について、以下の点に注意してください:
- ニューラルネットの科学的設計や関連する最適化については扱いません。代わりに、 Amazon.Science では LLMs に限らず、数多くの科学論文を扱っています。
- 本記事では LLM に焦点を当てていますが、そのベストプラクティスのほとんどは、コンピュータビジョンや Stable Diffusion などのマルチモーダルモデルを含む、あらゆる種類の大規模モデルのトレーニングにも関連したものとなっています。
ベストプラクティス
本記事では以下のベストプラクティスについて扱います:
- コンピュート – SageMaker Training は、データセット準備のための CPU ジョブや、千台規模の GPU ジョブを起動するための素晴らしい API です。
- ストレージ – データの読み込みとチェックポイントの作成方法は、スキルや好みに応じて、 2 つの方法に大別されると考えています。1つは Amazon FSx Lustre ファイルシステムで、もう1つは Amazon Simple Storage Service (Amazon S3) のみです。
- 並列性 – GPU を適切に使用するためには、分散トレーニングライブラリの選択が極めて重要です。SageMaker のシャーディングデータ並列処理など、クラウドに最適化されたライブラリの使用をお勧めしますが、自己管理型やオープンソースのライブラリも有効です。
- ネットワーク – EFA と NVIDIA GPUDirectRDMA が有効になっていることを確認し、マシン間通信を高速化します。
- レジリエンシー – 規模が大きくなると、ハードウェアの故障が発生する可能性が上がります。定期的にチェックポイントを行うことをお勧めします。数時間おきにチェックポイントを行うのが一般的です。
リージョンの選択
リージョンを選択する上で、インスタンスタイプと希望する容量は判断材料となります。SageMaker がサポートするリージョンと、各リージョンで利用できる Amazon Elastic Compute Cloud (Amazon EC2) インスタンスタイプについては、 Amazon SageMaker Pricing をご覧ください。本記事では、トレーニング用インスタンスタイプを SageMaker が管理する ml.p4d.24xlarge と仮定しています。
LLM ワークロードに適したリージョンを決定する際には、 AWS アカウントチームと連携するか、AWS Sales に連絡することをお勧めします。
データ準備
LLM の開発者は、自然界に存在するテキストの大規模なデータセットでモデルを学習します。このようなデータソースの代表的な例として、Common Crawl や The Pile があります。自然発生したテキストには、偏りや不正確さ、文法的な誤り、構文の違いなどが含まれることがあります。LLM の最終的な品質は、トレーニングデータの選択とキュレーションに大きく依存します。LLMのトレーニングデータ作成は、LLM 業界における研究と革新の活発な分野です。自然言語処理 (NLP) データセットの準備には、シェア・ナッシング並列の機会が豊富にあります。つまり、ソースファイル、パラグラフ、センテンス、ワードといった作品単位で、作業者間の同期を必要とせずに適用できる手順があるのです。
SageMaker のジョブ API である SageMaker Training と SageMaker Processing は、この種のタスクに優れています。これらの API を使うことで、開発者は任意の Docker コンテナを複数のマシンのフリート上で実行することができます。SageMaker Training API の場合、コンピューティングフリートは ヘテロジニアス であることができます。SageMaker では、Dask 、 Ray 、さらに PySpark など、数多くの分散コンピューティングフレームワークが使われています。特に、PySpark については SageMaker Processing で動作する専用の AWS 管理コンテナと SDK を用意しています。
複数のマシンでジョブを起動すると、 SageMaker Training と Processing は、マシンごとに 1 回ずつコードを実行します。分散アプリケーションを書くために特定の分散コンピューティングフレームワークを使用する必要はありません : マシンごとに 1 回実行されるコードを、お好みに合わせて書くだけで、シェア・ナッシング並列を実現することができます。また、ノード間通信ロジックも自由に作成・インストールすることができます。
データロード
トレーニングデータを保存し、データをストレージから計算用コンピュートノードに移動する方法は複数あります。このセクションでは、データロードのオプションとベストプラクティスについて説明します。
SageMaker のストレージとローディングのオプション
典型的な LLM データセットのサイズは、数億のテキストトークンで、数百ギガバイトに相当します。SageMaker が管理する ml.p4d.24xlarge インスタンスのクラスタでは、データセットの保存と読み込みにいくつかのオプションが用意されています:
- ノード上の NVMe SSD – ml.P4d.24xlarge インスタンスは 8TB NVMe を搭載しており、SageMaker File モードを使用している場合は
/opt/ml/input/data/<channel>で、また/tmpで利用できます。ローカルリードのシンプルさとパフォーマンスを求めるのであれば、NVMe SSD にデータをコピーすることができます。このコピーは、SageMaker File モードで行うこともできますし、マルチプロセスの Boto3 や S5cmd を使用するなど、独自のソースコードで行うことも可能です。 - FSx for Lustre – オンノードの NVMe SSD はサイズに制限があり、ジョブやウォームクラスタ作成のたびに Amazon S3 からの取り込みが必要です。ランダムアクセスを低レイテンシに維持しながら、より大きなデータセットに拡張したい場合は、 FSx for Lustre を使用することができます。 Amazon FSx は、ハイパフォーマンス・コンピューティング (HPC) で人気のあるオープンソースの並列ファイルシステムです。FSx for Lustre は、分散ファイルストレージ (ストリッピング)を使用し、ファイルメタデータをファイルコンテンツから物理的に分離することにより、高性能な読み書きを実現します。
- SageMaker FastFile Mode – FastFile Mode (FFM) は SageMaker 専用の機能で、SageMaker が管理する計算インスタンスに POSIX 準拠のインターフェースでリモート S3 オブジェクトを表示し、FUSE を使用して読み取り時のみストリームします。FFM の読み込みは、ブロックごとにリモートファイルを伝送する S3 コールを生み出します。Amazon S3 のトラフィックに関連するエラーを避けるためのベストプラクティスとして、FFM の開発者は、例えば、ファイルを順次読み、並列性を制御することによって、内部的な S3 呼び出し量を合理的に保つことを目指すべきです。
- 自己管理型データロード – もちろん、プロプライエタリまたはオープンソースのコードを使用して、独自の完全カスタムデータロードロジックを実装するように決定することもできます。自己管理型データロードを使用する理由としては、すでに開発されたコードを再利用して移行を促進する、カスタムエラー処理ロジックを実装する、基礎的なパフォーマンスとシャーディングをより制御する、などがあります。自己管理型データロードに使用するライブラリの例としては、torchdata.datapipes (旧 AWS PyTorch S3 Plugin)、Webdataset があります。AWS Python SDK Boto3 を使うと、Torch Dataset クラスと組み合わせて、カスタムデータローディングコードを作成することもできます。カスタムデータローディングクラスを使うことで、SageMaker Training のヘテロジニアスなクラスターを創造的に使用し、与えられたワークロードに応じて CPU と GPU のバランスをきめ細かく適応させることもできます。
これらのオプションとその選択方法の詳細については、ブログ記事 “Choose the best data source for your Amazon SageMaker training job” を参照してください。
Amazon S3 との大規模なやりとりにおけるベストプラクティス
Amazon S3 は、データの読み込みとチェックポイントの両方で、LLM のワークロードを処理することが可能です。バケット内の1つのプレフィックスあたり 1 秒間に 3,500 の PUT/COPY/POST/DELETE または 5,500 の GET/HEAD リクエストのリクエストレートをサポートしています。ただし、このレートはデフォルトでは必ずしも利用できるものではありません。その代わり、プレフィックスのリクエストレートが大きくなると、Amazon S3 は自動的にスケーリングして、増加したレートを処理します。詳細については、AWS re:Post 記事 “Why am I getting 503 Slow Down errors from Amazon S3 when the requests are within the supported request rate per prefix?” を参照してください。
Amazon S3 との高頻度のやり取りが予想される場合は、以下のベストプラクティスをお勧めします:
- 複数の S3バケットとプレフィックスから読み書きをするようにする。例えば、トレーニングデータとチェックポイントを異なるプレフィックスに分割することができます。
- Amazon CloudWatch で Amazon S3 のメトリクスを確認し、リクエストレートを追跡する。
- PUT/GET の同時実行をなるべく少なくする:
- 同時に Amazon S3 を使用するプロセスを少なくする。例えば、ノードあたり 8 つのプロセスが Amazon S3 にチェックポインティングする必要がある場合、まずノード内で、次にノードから Amazon S3 へと階層的にチェックポインティングすることで、PUT トラフィックを8分の1に減らすことができます。
- トレーニングレコードごとに S3 GET を行うのではなく、1つのファイルまたは S3 GET から複数のトレーニングレコードを読み込む。
- SageMaker FFM を介して Amazon S3 を使用する場合、SageMaker FFM は S3 呼び出しを行うことで、チャンクごとにファイルをフェッチします。FFM によって生成される Amazon S3 のトラフィックを制限するために、ファイルを順次読み、並行して開くファイル数を制限することをお勧めします。
開発者、ビジネス、またはエンタープライズサポートプランに加入されている場合は、S3 503 Slow Down エラーに関する技術サポートケースを開くことができます。しかし、まずはベストプラクティスに従っていることを確認し、失敗したリクエストのリクエスト ID を取得してください。
トレーニングの並列化
LLM は一般的に数十億から数千億のパラメータを持つため、NVIDIA GPU カード 1 枚で学習を行うには大きすぎます。そのため、LLM の実践家たちは、FSDP 、DeepSpeed 、Megatron など、LLM 学習の分散計算を容易にするいくつかのオープンソースライブラリを開発しました。これらのライブラリを SageMaker Training で実行することもできますし、SageMaker 分散トレーニングライブラリを使用することもできます。SageMaker 分散トレーニングライブラリは、AWS クラウド用に最適化されており、よりシンプルな開発者体験を提供します。開発者は、SageMaker 上で LLM を学習させるために、SageMaker 分散ライブラリまたは自己管理ライブラリの 2 つの選択肢から好きな方を選ぶことができます。
SageMaker 分散ライブラリ
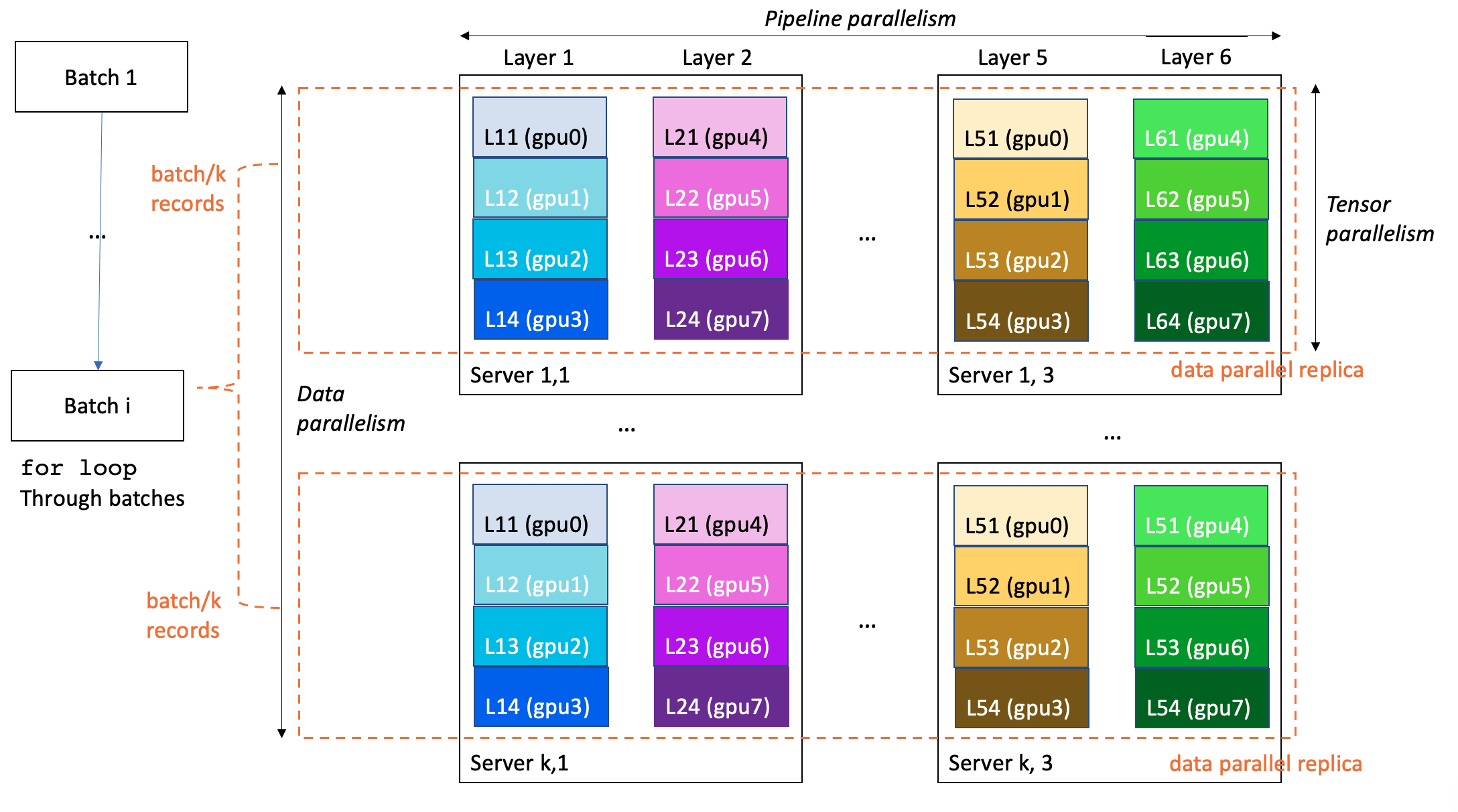
SageMaker Training では、分散トレーニングのパフォーマンスとユーザビリティを向上させるために、TensorFlow と PyTorch のトレーニングコードを拡張する独自の拡張をいくつか提案しています。LLM トレーニングは、多くの場合、3D 並列方式で実施されます:
- データ並列は、トレーニングのミニバッチを分割して複数の同じモデルのレプリカに供給し、処理速度を向上させます。
- パイプライン並列処理は、モデルの様々なレイヤーを異なる GPU やインスタンスに割り当てることで、単一 GPU や単一サーバーを超えたモデルサイズの拡張を可能とします。
- テンソル並列処理は、1 つのレイヤーを複数の GPU(通常は同じサーバー内) に分割し、個々のレイヤーを 1 つの GPU を超えるサイズに拡張します。
以下の例では,6 層モデルを合計で 8*k*3 GPU (1 サーバあたり 8GPU) 搭載となる k*3 個のサーバからなるクラスタで学習しています。データ並列度は k 、パイプライン並列度は 6 、テンソル並列度は 4 です。クラスタの各 GPU はモデル層の 4 分の 1 を含み,フルモデルは 3 台のサーバー(合計 24GPU )に分割されます。
以下は、特に LLM に関連するものです:
- SageMaker 分散モデル並列化 – このライブラリは、グラフパーティショニングを使用して、速度やメモリに最適化されたインテリジェントなモデルパーティショニングを生成します。SageMaker 分散モデル並列化ライブラリは、データ並列、パイプライン並列、テンソル並列、オプティマイザ状態シャーディング、チェックポインティングの有効化、オフロードなどの機能を備え、大規模モデルトレーニングへ最新かつ最高に最適化されています。SageMaker 分散モデル並列ライブラリを用いて、920 個の NVIDIA A100 GPU 上で 1750 億パラメータのモデルトレーニングを行った事例があります。詳細は、ブログ記事 “Train 175+ billion parameter NLP models with model parallel additions and Hugging Face on Amazon SageMaker” を参照してください。
- SageMaker シャーディングデータ並列処理 – 論文 “MiCS: Near-linear Scaling for Training Gigantic Model on Public Cloud” の中で、 著者の Zhang らは、パブリッククラウド上で巨大なモデルをトレーニングするためのニアリニアスケーリングにおいて、クラスタ全体ではなくデータ並列グループのみにモデルを分割する低通信モデル並列戦略を紹介しています。MiCS を用いることで、AWS の科学者は、EC2 P4de インスタンス上で 210 層 10億6000 万パラメータからなるモデルの学習において、1GPU あたり 176テラフロップ(理論ピーク値の56.4%)を達成することができました。MiCS は、SageMaker Training のお客様向けに、SageMaker シャーディングデータ並列処理 として提供されています。
SageMaker 分散トレーニングライブラリは、高いパフォーマンスと、よりシンプルな開発者体験を提供します。特に、並列ランチャーはジョブ起動 SDK に組み込まれているため、開発者はカスタムで並列プロセスランチャーを書いてメンテナンスしたり、フレームワーク固有の起動ツールを使用したりする必要がありません。
自己管理型
SageMaker Training では、お好みのフレームワークや科学的パラダイムを自由に使用することができます。特に、分散トレーニングを自分で管理したい場合、カスタムコードを書くための2つのオプションがあります
- AWS Deep Learning Container (DLC) を使う – AWS は DLC を開発・保守しており、最もよく使われるオープンソース ML フレームワーク群のための、AWS に最適化された Docker ベース環境を提供しています。SageMaker Training は、AWS DLC を外部のユーザー定義エントリポイントから引き出して実行できる独自の統合機能を備えています。特に LLM の学習では、TensorFlow、PyTorch、Hugging Face、MXNet 向けの AWS DLC が関連します。各フレームワークの DLC を利用することで、独自の Docker イメージを開発・管理することなく、PyTorch Distributed のようなフレームワークネイティブな並列処理を利用することができます。さらに、AWS の DLC には MPI インテグレーション機能があり、並列コードを簡単に起動することができます。
- SageMaker 互換のカスタム Docker イメージを作成する – 独自の (Bring Your Own, BYO) イメージを持ち込むことができます(Use Your Own Training Algorithms や Amazon SageMaker Custom Training containers を参照)。ゼロから作り始めることもできますし、既存の DLC イメージを拡張することもできます。SageMaker 上での LLM トレーニングにカスタムイメージを使用する場合、以下の点が満たされていることを確認することが特に重要です:
- イメージに適切な設定の EFA が含まれていること(この記事の後半で詳しく説明します)。
- GPUDirectRDMA が有効な NVIDIA NCCL 通信ライブラリがイメージに搭載されていること。
お客様は、DeepSpeed をはじめとする、さまざまな自己管理型の分散型トレーニングライブラリを利用することができます。
通信
LLM トレーニングのジョブが分散型であることを考えると、マシン間通信はワークロードの実現性、パフォーマンス、コストにとって極めて重要です。このセクションでは、マシン間通信の主要な機能を紹介し、インストールとチューニングのヒントで締めくくります。
Elastic Fabric Adapter
ML アプリケーションを高速化し、クラウドが提供する柔軟性、拡張性、弾力性を実現してパフォーマンスを向上させるためには、SageMaker で Elastic Fabric Adapter (EFA) を活用することができます。経験上、EFA を利用することは、マルチノードのLLM 学習で満足のいくパフォーマンスを得るための必須条件です。
EFA デバイスは、トレーニングジョブの実行中に SageMaker が管理する EC2 インスタンスに接続されるネットワークインターフェイスです。EFA は、P4d を含む特定のインスタンスファミリーで利用可能です。EFA ネットワークは、数百 Gbps のスループットを達成することが可能です。
EFA に関連して、AWS は Scalable Reliable Datagram (SRD) を導入しました。これは、InfiniBand Reliable Datagram にヒントを得て、パケット順序制約を緩和したイーサネットベースのトランスポートです。 EFA と SRD の詳細については、AWS HPC Blog の記事 “In the search for performance, there’s more than one way to build a network“ や、YouTube ビデオ ”How EFA works and why we don’t use infiniband in the cloud“、Shalev らの研究論文 ”A Cloud-Optimized Transport Protocol for Elastic and Scalable HPC“ を参照してください。
SageMaker の既存の Docker コンテナ、またはカスタムコンテナに、互換性のあるインスタンス上の EFA 統合を追加し、SageMaker ジョブによる ML モデルのトレーニングに使用することもできます。詳細については、”Run Training with EFA” を参照してください。 EFA は、オープンソースの Libfabric 通信パッケージを介して公開されています。しかし、LLM 開発者が Libfabric で直接プログラムすることはほとんどなく、 NVIDIA Collective Communications Library (NCCL) に依存する場合がほとんどです。
AWS-OFI-NCCL プラグイン
分散 ML では、EFA は NVIDIA Collective Communications Library(NCCL) と共に使用されることが多いです。NCCL は NVIDIA が開発したオープンソースのライブラリで、GPU 間通信のアルゴリズムを実装しています。GPU 間通信は、スケーラビリティとパフォーマンスを媒介する LLM トレーニングの基礎となるものです。NCCL は DL 学習において非常に重要なため、Python の DL 開発フレームワークのバックエンドとして採用される場合が多いです。そのため、LLM の開発者は、DL 開発フレームワークを介して気づかないうちに NCCL を利用していることもあります。LLM 開発者が EFA 上で NCCL を使用するためには、AWS が開発した AWS OFI NCCL プラグインを使用します。このプラグインは NCCL コールを EFA が使用する Libfabric インターフェースにマッピングします。最新のアップデートの恩恵を受けるためにも、最新バージョンの AWS OFI NCCL を使用することをお勧めします。
NCCL が EFA を使用していることを確認するには、環境変数 NCCL_DEBUG を INFO に設定し、NCCL によって EFA がロードされていることをログで確認する必要があります:
...
NCCL INFO NET/OFI Selected Provider is efa
NCCL INFO Using network AWS Libfabric
...
NCCL と EFA の設定に関する、より詳細な情報は、“Test your EFA and NCCL configuration” を参照してください。いくつかの環境変数を使用して、NCCL をさらにカスタマイズすることができます。なお、NCCL 2.12 以降では、EFA ネットワークの自動通信アルゴリズム選択ロジックが AWS から提供されています (NCCL_ALGO は未設定のままで可)。
NVIDIA GPUDirect RDMA over EFA
私たちは、P4d インスタンスタイプで、EFA ファブリック上の GPUDirect RDMA (GDR) を導入しました。これは、ネットワークインターフェースカード (NIC) が GPU メモリに直接アクセスすることを可能にし、NVIDIA GPU ベースの EC2 インスタンス間のリモート GPU 間通信を高速化し、 CPU とユーザーアプリケーション間の、オーケストレーションに伴うオーバーヘッドを削減します。GDR は、実現可能な場合 NCCL の内部で使用されます。
GDR の使用状況は、ログレベルが INFO に設定されている場合、以下のコードのように内部GPU 間通信に表示されます:
NCCL INFO Channel 00 : 9[101d0] -> 0[101c0] [receive] via NET/AWS Libfabric/1/GDRDMA
NCCL INFO Channel 00 : 1[101d0] -> 8[101c0] [send] via NET/AWS Libfabric/1/GDRDMA
AWS Deep Learning Containers で EFA を使用する
AWS は Deep Learning Containers (DLC) を維持しており、その多くは AWS が管理する Dockerfile が付属し、EFA、AWS OFI NCCL、および NCCL を含んで構築されています。GitHub レポジトリでは、PyTorch と TensorFlow を使った例を提供しています。DLC を使うと、これらのライブラリを自分でインストールする必要はありません。
独自の SageMaker Training コンテナで EFA を使用する。
独自の SageMaker Training コンテナを作成し、ノード間通信の高速化のために EFA 上の NCCL を使用したい場合は、 EFA、NCCL、AWS OFI NCCL をインストールする必要があります。詳細については、”Run Training with EFA” を参照してください。さらに、コンテナまたはエントリーポイントのコードで、以下の環境変数を設定する必要があります:
FI_PROVIDER="efa"ファブリック・インターフェイス・プロバイダを指定します。NCCL_PROTO=simple通信にシンプルなプロトコルを使用するよう NCCL に指示します。(現在、EFA プロバイダは LL プロトコルをサポートしていないため、有効にするとデータ破損の恐れがあります)。FI_EFA_USE_DEVICE_RDMA=1片方向および両方向の転送にデバイスの RDMA 機能を使用します。nccl_launch_mode="parallel"nccl_net_shared_comms="0"
オーケストレーション
数十から数百のコンピュートインスタンスのライフサイクルとワークロードを管理するには、オーケストレーションソフトウェアが必要です。このセクションでは、LLM オーケストレーションのベストプラクティスを提供します。
ジョブ内オーケストレーション
ほとんどの分散型フレームワークでは、開発者はサーバーサイドのトレーニングコードとクライアントサイドのランチャーコードの両方を書かなければなりません。トレーニングコードはトレーニングマシン上で実行される一方、クライアントサイドのランチャーコードはクライアントマシンから分散ワークロードを起動させます。現時点ではほとんど標準化されていませんが、例として以下のようなものがあります:
- PyTorch では、開発者は
torchrun,torchx,torch.distributed.launch(deprecation path),torch.multiprocessing.spawnを使ってマルチマシンのタスクを起動できます。 - DeepSpeed は独自の deepspeed CLI ランチャーを提供しており、MPI の起動もサポートします。
- MPI は一般的な並列計算フレームワークであり、ML に依存せず適度に枯れていることから、動作が安定し、ドキュメント化されているという利点があり、分散型 ML ワークロードでますます見られるようになりました。
SageMaker Training クラスタでは、トレーニングコンテナは各マシンで 1 回ずつ起動されます。そのため、3 つのオプションを選択できます:
- ネイティブランチャー – 特定の DL フレームワークのネイティブランチャー、例えば
torchrunコールをエントリポイントとして使用することができ、それ自体が複数のローカルプロセスを生成し、インスタンス間の通信を確立します。 - SageMaker MPI integration – SageMaker MPI インテグレーション (AWS DLC で利用可能、または sagemaker-training-toolkit でセルフインストール可能) を利用すると、エントリポイントコードを直接マシンあたり N 回実行することができます。これは、独自のコードで中間的なフレームワーク固有のランチャースクリプトの使用を避けることができるという利点があります。
- SageMaker 分散ライブラリ – SageMaker 分散ライブラリを使用すると、トレーニングコードに集中でき、ランチャーコードを書く必要が全くありません!SageMaker 分散ランチャーコードは、SageMaker SDK に組み込まれています。
ジョブ間オーケストレーション
LLM プロジェクトは、多くの場合、パラメータ探索、実験のスケーリング、エラーからの回復など、複数のジョブで構成されます。トレーニングタスクを開始、停止、並列化するためには、ジョブオーケストレータを使用することが重要です。SageMaker Training は、サーバーレス ML ジョブオーケストレーターであり、要求に応じて直ちにトランジェントなコンピュートインスタンスを提供します。使用した分だけを支払い、クラスタはコードが終了するとすぐに廃止されます。SageMaker Training Warm Pools を使うと、ジョブ間で同じインフラを再利用するために、トレーニングクラスタの有効期限を定義するオプションがあります。これにより、反復時間とジョブ間の配置のばらつきを減らすことができます。SageMaker のジョブは、Python や CLI など、さまざまなプログラミング言語から起動することができます。
SageMaker Python SDK と呼ばれる、sagemaker Python ライブラリを介して実装された SageMaker に特化した Python SDK がありますが、その使用は任意です。
大規模で長時間の学習ジョブにむけたクラスタ構築のためのクォータ緩和
SageMaker には、意図しない使用やコストを防ぐために設計された、リソースに対するデフォルトのクォータがあります。長時間稼働するハイエンドインスタンスの大きなクラスタを使用して LLM を訓練するには、次の表のクォータを増やす必要がある可能性があります。
| クォータ名 | デフォルト値 |
| Longest run time for a training job | 432,000 seconds |
| Number of instances across all training jobs | 4 |
| Maximum number of instances per training job | 20 |
| ml.p4d.24xlarge for training job usage | 0 |
| ml.p4d.24xlarge for training warm pool usage | 0 |
クォータ値を確認したり、クォータ緩和を申請する方法については、AWS サービスクォータを参照してください。オンデマンド、スポットインスタンス、トレーニングウォームプールのクォータは、別々に追跡され、変更されます。
SageMaker Profiler を有効にする場合、トレーニングジョブごとに SageMaker Processing ジョブが起動し、それぞれ1つの ml.m5.2xlarge インスタンスが消費されることに注意してください。 SageMaker Processing のクォータが、予想されるトレーニングジョブの同時実行に対応するのに十分な大きさであることを確認してください。例えば、Profiler 対応のトレーニングジョブを50個同時に起動したい場合、Processing ジョブで使うための ml.m5.2xlarge インスタンスのクォータを 50 に引き上げる必要があります。
さらに、長時間実行するジョブを起動するには、Estimator の max_run パラメータを、学習にかかる最長時間へ秒単位で明示的に設定する必要があります。このとき、値の上限はトレーニングジョブの最長実行時間のクォータ値になります。
監視とレジリエンシー
ハードウェアの故障は、1 つのインスタンスの規模では極めてまれですが、同時に使用するインスタンスの数が増えるにつれて、頻度が高くなります。典型的な LLM の規模では、数百から数千の GPU が 毎日 24 時間、数週間から数ヶ月にわたって使用されるため、ハードウェアの故障はほぼ確実に発生します。したがって、LLM ワークロードは、適切な監視とレジリエンシーのメカニズムを実装する必要があります。まず、LLM インフラストラクチャを綿密に監視し、障害の影響を抑え、計算リソースの利用を最適化することが重要です。SageMaker Training では、この目的のためにいくつかの機能を提供しています:
- ログが自動的に CloudWatch Logs に送信されます。ログにはトレーニングスクリプトの
stdoutとstderrが含まれます。MPI ベースの分散トレーニングでは、すべての MPI ワーカーがリーダープロセスにログを送信します。 - メモリ、CPU 使用率、GPU 使用率などのシステムリソース使用率メトリクスは、自動的に CloudWatch に送信されます。
- CloudWatch に送信されるカスタムトレーニングメトリクスを定義することができます。メトリクスは、設定した正規表現に基づきログから取得されます。AWS パートナーが提供する Weights & Biases のようなサードパーティの実験パッケージも、SageMaker Training で使用できます。(例として、記事 “Optimizing CIFAR-10 Hyperparameters with W&B and SageMaker” をご参照ください。)
- SageMaker Profiler を使うと、インフラストラクチャの使用状況を調査し、最適化の推奨事項を得ることができます。
- Amazon EventBridge と AWS Lambda により、ジョブの失敗や成功、S3 ファイルのアップロードなどのイベントに自動で反応するクライアントロジックを作成することができます。
- SageMaker SSH Helper は、SSH を通してトレーニングジョブホストに接続するための、コミュニティでメンテナンスされているオープンソースのライブラリです。特定のノードで実行されるコードの検査やトラブルシューティングに役立ちます。
監視機能に加え、SageMaker ではジョブのレジリエンシー機能も提供しています。
- クラスタのヘルスチェック – ジョブ開始前に、SageMaker は GPU のヘルスチェックを行い、GPU インスタンス上の NCCL 通信を検証します。また、お客様の学習スクリプトが正常なクラスタインスタンスで実行されるよう、異常なインスタンスを置き換えます。ヘルスチェックは現在、P および G GPU ベースのインスタンスタイプで有効になっています。
- ビルトインの再試行とクラスタアップデート – SageMaker internal server error (ISE) により失敗したトレーニングジョブを自動的に再試行するように SageMaker を設定することができます。ジョブを再試行する際、SageMaker は回復不可能な GPU エラーが発生したインスタンスを新しいインスタンスと交換します。次にすべての健全なインスタンスを再起動し、ジョブを再度開始します。この結果、再起動とワークロードの完了がより速くなります。クラスタアップデートは現在、P および G GPU ベースのインスタンスタイプで有効になっています。独自のアプリケーティブ再試行メカニズムをジョブを送信するクライアントコードの周りに追加することで、クォータ制限の超過といったような他のタイプの起動エラーを処理することができます。
- Amazon S3 への自動チェックポイント – この機能を使うと、ジョブの進捗状況をチェックポインティングし、新しいジョブで過去の状態を再ロードするのに役立ちます。
ノードレベルの置き換え機能の恩恵を受けるには、コードにエラーが発生する必要があります。ノードに障害が発生すると、コレクティブはエラーにならずハングアップすることがあります。したがって、迅速な修復を行うには、コレクティブにタイムアウトを適切に設定し、タイムアウトに達したときにコードがエラーをスローするようにします。
CloudWatch のログやメトリクスを監視し、ログが書き込まれていない、GPU の使用率が0%などの異常なパターンがあれば、ハングアップやコンバージェンス停止を示唆し、ジョブの自動停止やリトライを行うなど、監視クライアントをセットアップし、ジョブハングやアプリケーションの収束停止の際に対処しているお客様もいます。
チェックポイント機能の深掘り
SageMaker のチェックポイント機能は、/opt/ml/checkpoints に書いたもの全てを、checkpoint_s3_uri SDK パラメータで指定された Amazon S3 URI にコピーします。ジョブの起動や再起動時に、その URI に送られたものが、全マシンの /opt/ml/checkpoints に送り返されます。これは、すべてのノードがすべてのチェックポイントにアクセスできるようにしたい場合には便利です。しかし、マシンの数やチェックポイントの履歴サイズの規模が大きくなってくると Amazon S3 のトラフィックやダウンロード時間が大きくなりすぎる可能性があるため、この方法は使えません。さらに、テンソル並列やパイプライン並列では、ワーカーが必要とするのはチェックポイントされたモデルの一部だけで、すべてではありません。そのため、これらの制限に直面した場合、以下のオプションをお勧めします:
- FSx for Lustre へのチェックポイント – ランダム I/O 性能が高いおかげで、好きなようにシャーディングとファイル帰属スキームを定義することができます。
- 自己管理での Amazon S3 へのチェックポイント – ノンブロッキングでチェックポイントの保存と読み込みを行う際に使用できる Python 関数の例については、チェックポイントの保存を参照してください。
関連するオーバーヘッドやコストに応じて、数時間ごと (例えば 1 ~ 3 時間ごと) にモデルをチェックポイントすることを強くお勧めします。
フロントエンドとユーザー管理
ユーザー管理は、レガシーな共有 HPC インフラと比較した際の、SageMaker のユーザビリティ上の主要な強みです。SageMaker Training の権限は、いくつかの AWS Identity and Access Management(IAM) アブストラクションによって支配されています:
- プリンシパル (ユーザーとシステム) には、リソースを起動する権限が与えられます。
- トレーニングジョブはロールを持ち、権限を自身で持つことができます。例えば、データアクセスやサービス呼び出しなどの権限を持つことができます。
さらに、2022 年、私たちは SageMaker Role Manager を追加し、ペルソナベースでのパーミッション作成を容易にしました。
まとめ
SageMaker Training を活用することにより、大規模モデルの学習というワークロードにおいて、コストを削減し、反復速度を向上させることができます。また、私たちは多数の投稿やお客様事例という形で成功事例を文書化しています。これには以下のものが含まれます:
- AWS re:Invent 2022 – Train ML models at scale with Amazon SageMaker, featuring AI21 Labs
- Create, train, and deploy a billion-parameter language model on terabytes of data with TensorFlow and Amazon SageMaker
- How I trained 10TB for Stable Diffusion on SageMaker
- LG AI Research Develops Foundation Model Using Amazon SageMaker
コストを削減しつつ LLM の市場投入までの時間を短縮したい場合は、ぜひ SageMaker Training API をご検討ください!また、どのようなものを構築したのか、ぜひ我々にお知らせください!
Amr Ragab, Rashika Kheria, Zmnako Awrahman, Arun Nagarajan, Gal Oshri の有益なレビューと指導に特別な感謝をいたします
本記事の翻訳はソリューションアーキテクトの大前遼が担当しました。
著者について
 Anastasia Tzevelekaは AWS の機械学習・AI スペシャリストソリューションアーキテクトです。EMEA の顧客に向け、AWS サービスを使用してスケールする機械学習ソリューションの構築を支援しています。これまで、自然言語処理 (NLP)、MLOps、Low Code No Code ツールなど、さまざまな領域のプロジェクトに携わってきました。
Anastasia Tzevelekaは AWS の機械学習・AI スペシャリストソリューションアーキテクトです。EMEA の顧客に向け、AWS サービスを使用してスケールする機械学習ソリューションの構築を支援しています。これまで、自然言語処理 (NLP)、MLOps、Low Code No Code ツールなど、さまざまな領域のプロジェクトに携わってきました。
 Gili Nachumは、EMEA Amazon Machine Learning チームの一員として働く、シニア AI/ML スペシャリストソリューションアーキテクトです。ディープラーニングモデルをトレーニングすることの難しさと、機械学習が私たちの知る世界をどのように変えていくかに情熱を注いでいます。余暇には卓球を楽しんでいます。
Gili Nachumは、EMEA Amazon Machine Learning チームの一員として働く、シニア AI/ML スペシャリストソリューションアーキテクトです。ディープラーニングモデルをトレーニングすることの難しさと、機械学習が私たちの知る世界をどのように変えていくかに情熱を注いでいます。余暇には卓球を楽しんでいます。
 Olivier Cruchantは、フランスを拠点とする AWS のプリンシパル機械学習スペシャリストソリューションアーキテクトです。小規模なスタートアップから大企業まで、AWS のお客様が本番レベルの機械学習アプリケーションを開発・導入するのを支援しています。余暇には、研究論文を読んだり、友人や家族と大自然を探検したりするのが好きです。
Olivier Cruchantは、フランスを拠点とする AWS のプリンシパル機械学習スペシャリストソリューションアーキテクトです。小規模なスタートアップから大企業まで、AWS のお客様が本番レベルの機械学習アプリケーションを開発・導入するのを支援しています。余暇には、研究論文を読んだり、友人や家族と大自然を探検したりするのが好きです。
 Bruno Pistoneは、ミラノに拠点を置く AWS の AI/ML スペシャリストソリューションアーキテクトです。あらゆる規模のお客様を対象に、技術的なニーズを深く理解し、AWS クラウドと Amazon Machine Learning スタックを最大限に活用した AI・機械学習ソリューションの設計を支援することに取り組んでいます。専門分野は、機械学習のエンド・トゥ・エンド、機械学習の産業化、MLOps です。趣味は友人と過ごすこと、新しい場所を探索すること、そして新しい目的地への旅行です。
Bruno Pistoneは、ミラノに拠点を置く AWS の AI/ML スペシャリストソリューションアーキテクトです。あらゆる規模のお客様を対象に、技術的なニーズを深く理解し、AWS クラウドと Amazon Machine Learning スタックを最大限に活用した AI・機械学習ソリューションの設計を支援することに取り組んでいます。専門分野は、機械学習のエンド・トゥ・エンド、機械学習の産業化、MLOps です。趣味は友人と過ごすこと、新しい場所を探索すること、そして新しい目的地への旅行です。