Amazon Web Services ブログ
Fivetran の CDC 機能で実現するラーメン山岡家の Iceberg on AWS データパイプライン
はじめに
本ブログは、株式会社丸千代山岡家と Fivetran Japan、Amazon Web Services Japan が共同で執筆しました。
みなさま、こんにちは。AWS ソリューションアーキテクトの大久保です。
昨今、Apache Iceberg を利用したレイクハウスアーキテクチャが AWS の Analytics ワークロードの中心となりつつあります。Iceberg テーブルを分析基盤の核に据える構成が広がる一方で、「データベースからどのように Iceberg テーブルにデータを連携するか」――この”データを投入するコンポーネント”の選定に悩まれている方も多いのではないでしょうか。特に、基幹データベースの変更をタイムリーに反映したい場合、CDC(Change Data Capture)が有力な選択肢となります。CDC とは、データベースに対する変更(INSERT / UPDATE / DELETE)をリアルタイムまたはニアリアルタイムに検知・取得する手法です。従来のバッチ処理のようにテーブル全体を定期的にコピーするのではなく、変更差分のみを効率的に転送できるため、データの鮮度と転送効率を両立できます。しかし、実際に CDC パイプラインを構築しようとすると、複数サービスを組み合わせた運用負荷など、想定以上のハードルに直面することも少なくありません。
本記事では、ラーメンチェーン「山岡家」を展開する株式会社丸千代山岡家(以下、山岡家)が、Fivetran の CDC 機能を活用して Oracle から Amazon S3 上の Iceberg テーブルへのデータ同期を実現した事例をご紹介します。アーキテクチャの検討プロセスから Fivetran 導入後の効果まで解説しますので、同様の構成を検討されている方の参考になれば幸いです。

図 1:山岡家オリジナル看板ロゴ T シャツ。「ラーメンはスープが命。データは鮮度が命。」
山岡家のデータ活用と今回の課題
山岡家では、データ活用による経営の最適化に積極的に取り組んでいます。具体的には、以下のような取り組みを進めています。
- 仕入れ量の最適化:各店舗の売上・仕入れデータの分析による適正発注
- 人員配置の効率化:来客予測に基づくシフト最適化
- キャッシュロジスティックスの最適化:店舗内現金の金種別増減予測
- 現金管理の差異分析:店舗ごとの現金過不足の検知・分析
これらのデータ活用を支える基盤として、Snowflake を中核に据え、AWS サービスと組み合わせたデータパイプラインを構築しています。Snowflake は分析・クエリだけでなく、パイプラインのオーケストレーション(タスク完了検知等)も担っており、データ基盤全体の中核的な役割を果たしています。
会計仕訳データのリアルタイム連携
こうしたデータ基盤をさらに発展させるにあたり、今回取り組んだのが会計仕訳データのリアルタイム連携です。会計仕訳データは、現金管理の差異分析を含む幅広い用途で活用しています。現状は会計データを直接 BI に接続していますが、BI 層を分離し、データレイク経由での参照に移行することで、会計データを SSOT(Single Source of Truth)として一元管理したいと考えています。
今回の具体的な課題は Amazon RDS for Oracle 上の会計仕訳データを、ニアリアルタイム(数分間隔)で S3 上の Iceberg テーブルに同期し、Snowflake からクエリできるようにすることでした。このデータ連携の方式として CDC を採用した理由は以下の通りです。
- ニアリアルタイムの反映が必要:店舗の現金出納データを BI で社内公開しており、数分単位でのデータ反映が求められていた
- 差分同期が必要:会計仕訳データは日々の入力に加えて過去データの修正・削除も発生するため、INSERT だけでなく UPDATE・DELETE を含むテーブル同期が必要だった
構築したアーキテクチャ
この課題に対し、Fivetran の CDC 機能を採用して以下のアーキテクチャを構築しました。
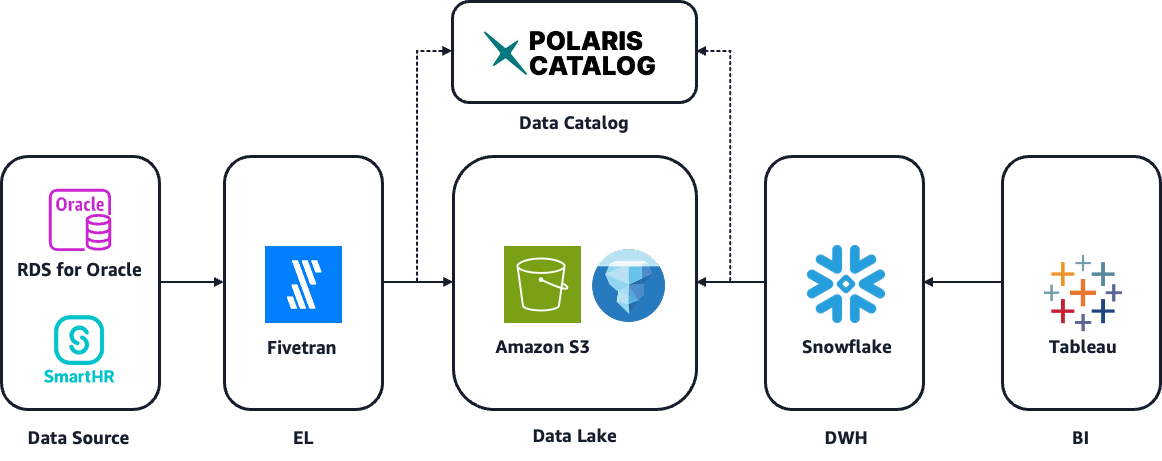
図 2:RDS for Oracle から S3 Iceberg への CDC パイプラインアーキテクチャ
Fivetran が RDS for Oracle から変更データを取得し、S3 上に Iceberg 形式で書き込みます。データカタログは Fivetran が管理する Polaris Catalog を利用しており、Snowflake はこのカタログを参照して S3 上の Iceberg テーブルを認識します。Tableau は Snowflake 経由でデータにアクセスする構成です。
以降のセクションでは、この構成に至った経緯と Fivetran を選択した理由、データの流れの詳細を解説します。
Fivetran の採用
検討した構成
当初は AWS のサービスを組み合わせた構成も検討しましたが、それぞれ課題がありました。
- ストリーミング CDC( AWS Database Migration Service → Amazon Kinesis Data Streams → Amazon Data Firehose → Amazon S3 ):DMS の CDC 機能自体は実績のある手法だが、今回の構成では DMS に加えて Kinesis Data Streams、Data Firehose、S3 と 4 つのサービスを組み合わせる必要があり、それぞれの設定・監視・障害対応を含めた運用負荷が課題だった。また、DMS の定期的なバージョンアップに伴うダウンタイムへの対応も継続運用上の考慮点だった
- バッチ ETL:ニアリアルタイムでのデータ反映という要件を満たせなかった
よりシンプルかつリアルタイム性を両立できる構成を模索する中で、Fivetran の CDC 機能に着目しました。
Fivetran とは
Fivetran は、データの収集・転送を自動化するマネージドデータパイプラインサービスです。700 以上のデータソースに対応しており、ノーコードでデータパイプラインを構築できます。詳細は Fivetran 公式サイト をご参照ください。
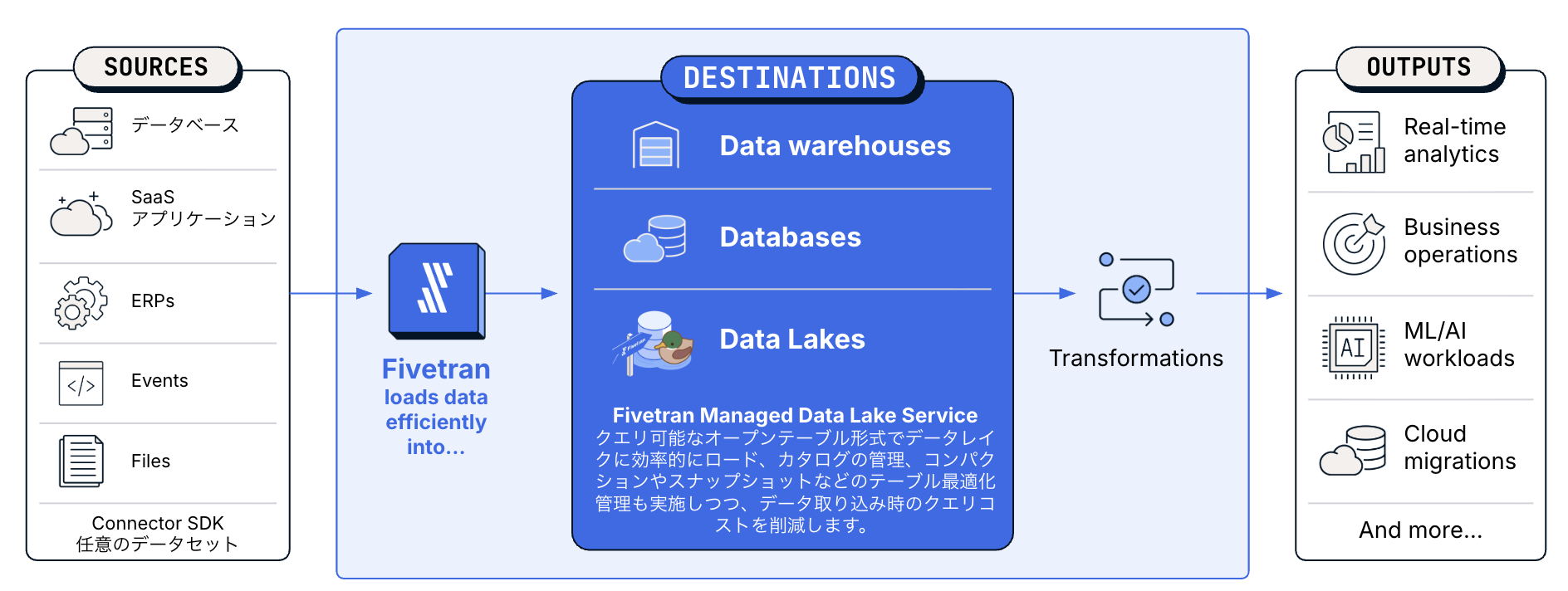
図 3:Fivetran の全体像 — 多様なデータソースから Data Warehouse・Data Lake への連携を自動化する(出典: Fivetran)
Fivetran の CDC 機能は、ソースデータベースの変更(INSERT / UPDATE / DELETE)やスキーマの変更を検知し、ターゲットシステムへ自動的に反映します。Oracle を含む主要な RDB に対応しており、インフラの構築・管理なしに CDC パイプラインを実現できる点が特徴です。
Fivetran を選択した理由
山岡家が Fivetran を選択した背景には、以下のポイントがありました。
- Oracle CDC の運用複雑性を吸収できる:Oracle の CDC は、アーカイブログの管理や補足ロギングの設定など、他の RDB と比較して実装の複雑さが高い。Fivetran は Binary Log Reader 方式でこれらを吸収し、Oracle 固有の設定を深く意識することなく CDC パイプラインを構築できる
- Iceberg 形式での書き込みと Snowflake と直接連携できる Polaris Catalog を提供している:S3 に Iceberg 形式でデータを書き込み、カタログでメタデータを管理できる
- 複数データソースを統合管理できる:Oracle の CDC だけでなく SmartHR 等の SaaS からの API 連携も同一プラットフォームで管理でき、データ基盤全体の統一性が向上する
- 運用コンポーネントが少ない:SaaS として提供されるため、前述のストリーミング CDC 構成のように複数サービスの設定・監視・障害対応を個別に行う必要がない
山岡家では、本来単純な EL(Extract / Load)処理に社内リソースを割くのではなく、データ活用そのものに注力したいという背景がありました。データベースから Iceberg へ低い運用コストでニアリアルタイムに CDC が可能な Fivetran を選定し、短期間で目的を達成できました。
データの流れ
本記事で解説する CDC パイプラインのデータの流れは以下の通りです。
- ソースからのデータキャプチャ:Fivetran が Binary Log Reader 方式で RDS for Oracle の変更情報を取得し、INSERT・UPDATE・DELETE の変更を検知します。初回実行時にはフルロードが行われ、以降は差分のみが転送されます。SmartHR からは API 経由で人事データを取得します(こちらは CDC ではなく API ポーリング)。初回フルロードから差分同期への切り替えを含む具体的なセットアップ手順については「Fivetran の Managed Data Lake Service の CDC で実現する業務システムから Apache Iceberg へのリアルタイムデータ連携」をご参照ください
- Iceberg 形式での S3 書き込み:キャプチャした変更データを Apache Iceberg 形式で Amazon S3 に書き込みます。データファイル(Parquet)とメタデータが S3 上に格納されます
- カタログでのメタデータ管理:Polaris Catalog に Iceberg テーブルのメタデータ(スキーマ情報、スナップショット履歴、パーティション情報など)が登録されます。分析エンジンはカタログを参照するだけでテーブルの構造と最新の状態を把握できます
- Snowflake からの分析クエリ:Snowflake は Polaris Catalog を参照し、S3 上の Iceberg テーブルを Iceberg Tables として認識します。Fivetran が新しいデータを書き込むたびに Snowflake 側のテーブル情報が自動更新され、常に最新のデータに対してクエリを実行できます
なお、CDC はデータ同期だけでなく、Snowflake 上の仕訳連携タスクの完了検知トリガーとしても活用しており、データ同期とパイプライン制御を一つの仕組みで兼ねています。
なお、S3 Tables ではなく S3 Standard を採用しています。これは、Fivetran の Iceberg 連携に必須となる Fivetran 管理の Polaris Catalog が、執筆時点で S3 Tables との統合に対応していないためです。S3 Tables の利用を検討される場合はこの点にご留意ください。
Fivetran 導入の効果
実際に Fivetran を導入した結果、山岡家が実感している効果は以下の通りです。
環境維持の負荷が低い
山岡家が最も評価しているポイントの一つです。維持すべきものは S3 バケットと Fivetran のデータカタログ環境のみであり、複数コンポーネントの監視・障害対応・バージョン管理が不要です。データエンジニアリングに専任チームを置かない組織でも無理なく運用できる構成になっています。
データ反映のレイテンシ
Fivetran の CDC 機能により、会計仕訳データの変更が約 5 分で S3 上の Iceberg テーブルに反映され、Snowflake からクエリ可能になります。日々の仕訳入力から分析可能になるまでのタイムラグが大幅に短縮され、よりタイムリーな経営判断が可能になりました。
運用工数の大幅削減
Fivetran 導入後、データパイプラインの運用工数は月あたり約 0.5 日にまで削減されました。導入前は月あたり約 6 日の運用工数が発生していましたが、SaaS としてコンポーネントの監視・障害対応・バージョン管理が抽象化されたことで大幅に削減されています。
複数データソースの一元管理
Oracle の会計仕訳データ(CDC)に加えて SmartHR の人事データ(API 連携)も Fivetran 経由で連携しており、データ取得方式が異なるソースでも同一プラットフォームでデータパイプラインを管理できています。データソースが増えても Fivetran 上でコネクタを追加するだけで済むため、データ基盤の拡張が容易です。
ワークロードの規模感
採用を検討されている方の参考として、本パイプラインのワークロード規模を記載します。
| # | 項目 | 値 |
|---|---|---|
| 1 | 月間レコード数 | 約 20 万行 |
| 2 | 月間データサイズ | 約 2 GB |
| 3 | 日次平均レコード数 | 約 7,000 行 |
| 4 | 日次平均データサイズ | 約 70 MB |
| 5 | ピーク(月初) | 約 7,000 件 / 5 分 |
通常時は比較的少量のデータが継続的に連携されますが、月初の会計締め処理時にはバースト的にデータ量が増加します。Fivetran はこのようなピーク時にも安定して動作しており、レイテンシの悪化やエラーは発生していません。
今後の展望
今回の Fivetran CDC パイプラインは、山岡家のデータ基盤を発展させるための第一歩です。今後は既存の Snowflake 基盤を活かしつつ Iceberg の適用範囲を広げ、定型データがほぼすべて可視化された状態を目指していきます。
データ基盤の方向性:Snowflake + S3 Iceberg の併用
現状は Snowflake Internal Tables にデータを直接格納するケースが多くありますが、長期的にはデータ入力等にかかるコストとオープン性を見据え、活用できる箇所には Amazon S3 上の Apache Iceberg テーブルを採用していく方針です。Iceberg を採用する理由は主に 3 つあります。
- Snowflake とのネイティブ連携:Snowflake が Iceberg テーブルをネイティブに参照できるため、既存の分析基盤との親和性が高い
- オープンフォーマットの拡張性:特定のエンジンにロックインされず、将来的に用途に応じた分析ツールを選択できる
- 運用の柔軟性:タイムトラベルやスキーマ進化といった機能により、データ管理の負荷を軽減できる
S3 にデータを Iceberg 形式で集約しておくことで、Snowflake での分析に加え、将来的には他のサービスからもデータを活用できます。Snowflake 経由の分析についても、現在の Tableau に加え、Sigma BI や Streamlit など、用途に応じた分析ツールの活用を視野に入れており、データ活用の幅をさらに広げていく予定です。
まとめ
本記事では、山岡家が Fivetran の CDC 機能を活用して、RDS for Oracle から Amazon S3 上の Apache Iceberg テーブルへのデータ同期を実現した事例をご紹介しました。
当初は AWS のサービスを組み合わせたストリーミング CDC 構成も検討しましたが、複数コンポーネントの運用負荷を考慮し、Fivetran のマネージド CDC 機能を採用しました。その結果、約 5 分でのデータ反映、月あたりの運用工数を約 6 日から 0.5 日への削減、PoC から本番稼働まで約 1 ヶ月という短期導入を実現しています。
CDC × Iceberg on AWS の構成を検討されている方にとって、本記事がアーキテクチャ選定の一助となれば幸いです。
著者について
 |
田中 陽里株式会社丸千代山岡家 経営企画室 副室長
|
 |
大久保 裕太アマゾンウェブサービスジャパン合同会社 ソリューションアーキテクト
|