AWS 기술 블로그
Category: Analytics
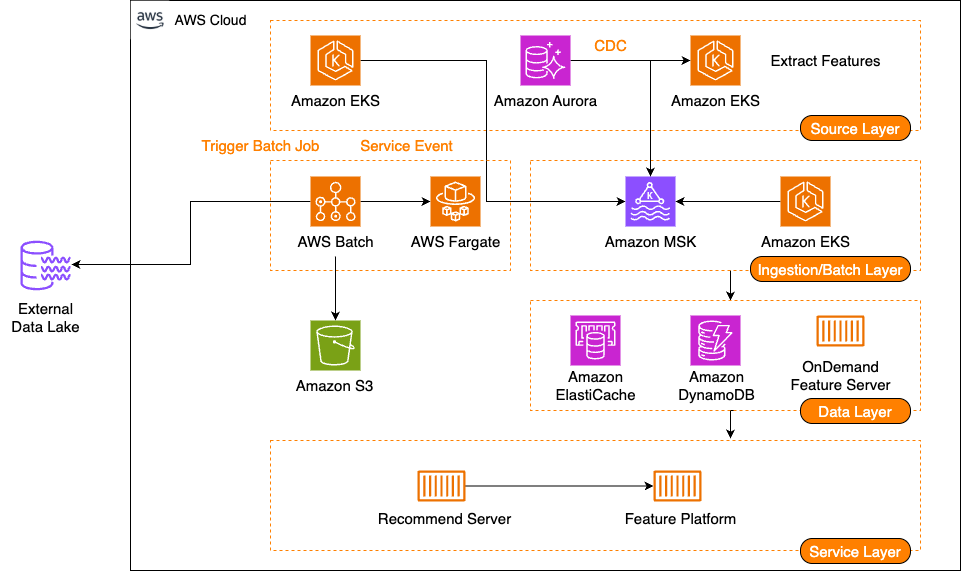
당근의 AWS 기반 피처 플랫폼 구축 여정, Part 2: 피처 수집
해당 포스트는 당근의 김현호님, 서진형님, 권민재님과 함께 작성했으며, 이전에 AWS 글로벌 블로그에 포스팅한 영문 블로그와 동일한 내용입니다. 이 시리즈의 1부에서는 당근이 개발한 새로운 피처 플랫폼에 대해 다루었습니다. 이 플랫폼은 피처 서빙, 스트림 수집 파이프라인, 배치 수집 파이프라인의 세 가지 주요 구성 요소로 이루어져 있습니다. 또한 요구사항, 솔루션 아키텍처, 다단계 캐시를 활용한 피처 서빙에 대해 설명했습니다. […]
AWS 관리형 서비스를 활용한 실시간 지능형 뉴스 기반 주가 영향도 분석 시스템
머리글 주식 가격은 기업의 실적, 경제 지표, 정치적 사건, 산업 동향 등 다양한 정보에 민감하게 반응하며, 이러한 정보의 대부분은 뉴스를 통해 전파되고 시장에 영향을 끼칩니다. 예를 들어 중요한 뉴스 발표 직후 주식 가격이 급등하거나 급락하는 현상은 우리 주변에 자주 볼수 있는 현상입니다. 이 때문에 다양한 기업은 Batch성 뉴스 영향도 분석을 시도해왔습니다. 하지만 주가 데이터가 초 […]

Amazon S3 Vectors와 Amazon OpenSearch Service로 벡터 검색 최적화하기
본 게시글은 AWS Big Data Blog에 게시된 ‘Optimizing vector search using Amazon S3 Vectors and Amazon OpenSearch Service by Sohaib Katariwala, Bobby Mohammed, Sorabh Hamirwasia, Mark Twomey, and Pallavi Priyadarshini’을 한국어 번역 및 편집하였습니다. 참고: 본 블로그 내용은 7월 15일 기준으로, Amazon S3 Vectors와 Amazon OpenSearch Service의 통합 기능은 프리뷰 버전으로, 변경될 수 있습니다. 벡터 임베딩(Vector Embeddings)과 유사성 검색(Similarity […]

HotelStory의 Amazon Q in QuickSight를 통한 생성형 AI 비즈니스 인텔리전스 환경 구축하기
호텔스토리는 호스피탈리티 테크 기업으로, 호텔 예약과 온라인 판매를 위한 통합 솔루션을 제공합니다. 호텔 파트너는 여러 OTA에 흩어진 객실 재고와 요금을 한 곳에서 추적 및 관리할 수 있어, 호텔스토리의 GSA(총판 사업) · CMS(채널 매니저) · 자사 예약엔진(부킹 엔진)을 도입해 객실가와 재고를 최적화하고 운영 효율을 극대화합니다. 영국 파이낸셜 타임즈(FT)로부터 3년 연속 ‘아시아 태평양 고성장 기업’으로 선정되는 등, […]

Zookeeper에 의존하지 않는 Kafka를 준비하기 : Amazon MSK에서 KRaft 모드 사용하기
들어가기 Amazon Managed Streaming for Apache Kafka(이하 Amazon MSK)는 AWS에서 제공하는 완전 관리형 Apache Kafka 서비스로 Apache Kafka에 대한 복잡한 설정, 관리, 운영을 AWS가 대신 처리해주어 개발자가 데이터 처리에만 집중 할 수 있도록 도움을 주는 AWS의 매니지드 서비스입니다. 많은 고객들은 Micro-service Architecture(MSA)을 채택하여 어플리케이션을 현대화하고 있으며 Apache Kafka는 MSA의 Event Driven Architecture(EDA)에서 메세징 허브 역할을 […]
AI로 혁신하는 70년 언론사: 한국일보의 AWS 기반 인물 사진 자동 분류 및 AI 검색 시스템 구축 사례
Overview 한국일보가 AWS 기반 AI 기술을 활용해 언론사의 오랜 과제였던 인물 사진 자동 분류 시스템 ‘FACT’를 구축한 사례를 소개합니다. Amazon Rekognition의 얼굴 인식 기술과 Amazon Bedrock의 생성형 AI를 결합해 매일 수백 장의 보도 사진을 자동으로 분류하고, “웃고 있는 지드래곤”, “넘어진 손흥민”과 같은 자연어 기반 맥락 검색을 가능하게 합니다. 기존 수작업 태깅의 한계를 극복하고 기자들의 업무 […]

삼성계정 서비스, 대규모 트래픽 속 Amazon MSK 를 이용한 무 중단 Database 스키마 전환
이 글은 삼성전자의 기술블로그(Samsung Tech Blog)에 기재된 원문을 인용하여 작성 하였습니다. 대 규모 서비스에서 민감한 정보의 암호화 및 스키마 전환을 서비스 영향 없이 이뤄낸 AWS 사용사례를 AWS 한국 기술 블로그를 통해 게시되도록 지원해 주신 삼성전자 김종구 프로님에게 감사의 말씀을 드립니다. 시작하며, 약 18억 명의 사용자를 기반으로 운영되는 글로벌 계정 서비스인 삼성 계정에서는 24/7 대규모 트래픽을 […]

삼성전자 SmartThings, OpenSearch 도입으로 성능향상과 비용절감 달성기
이 글은 삼성전자의 기술블로그(Samsung Tech Blog)에 기재된 원문을 인용하여 작성 하였습니다. 삼성전자의 대규모 IoT 서비스인 Samsung SmartThngs서비스에서 Amazon OpenSearch를 활용해 성능향상과 비용 효율화를 이뤄낸 사례를 AWS 한국 기술 블로그에 기재 할 수 있도록 지원해 주신 삼성전자 이장결 프로님에게 감사의 말씀을 드립니다. 시작하며, 이 글에서는 SmartThings 기록 시스템의 DB 교체 여정에 대해 소개합니다. 기존 HBase는 다양한 […]

카카오게임즈의 Amazon Bedrock 기반 실시간 채팅 번역 구축
카카오게임즈는 글로벌 게임 퍼블리셔이자 디벨로퍼로서, 언어와 지역, 환경의 경계를 넘어 전 세계 누구나 함께 즐길 수 있는 게임 경험을 만들어가고 있습니다. 모바일, PC 온라인, 콘솔 등 다양한 플랫폼을 아우르며, 전 세계 이용자들에게 고품질의 콘텐츠를 선보이고 있으며, 게임의 본질에 집중하여 지속 가능한 가치를 창출하는 동시에, 창의적이고 잠재력 높은 게임 IP를 발굴해 글로벌 시장에서 의미 있는 성과를 […]

뮤직카우의 Amazon RDS와 Amazon Redshift 간 CDC 파이프라인 Zero-ETL로 쉽게 구축하기
2016년 설립된 뮤직카우는 세계 최초의 음악수익증권 플랫폼입니다. 음악수익증권은 누구나 매월 저작권으로부터 발생하는 수익을 받아볼 수 있고, 자유로운 거래로 추가 수익을 창출할 수 있는 자산입니다. 뮤직카우는 음악수익증권 투자라는 혁신적 비즈니스 모델을 통해 ‘문화금융’이라는 새로운 가치를 만들었습니다. 투자자들에게는 매력적인 투자 대안을, 음악 팬들에게는 좋아하는 노래를 들을수록 수익이 쌓이는 음악 소비 문화의 새로운 패러다임을 제시하고 있습니다. 또, 아티스트들에게는 […]