AWS 기술 블로그

Part2: 삼성계정 서비스의 Agentic AIOps, 운영환경에서 Multi-Agent 시스템으로 RCA 자동화 하기
이번 포스팅은 삼성전자 서비스의 핵심, 삼성계정 서비스에서 서비스 운영에 실질적인 문제를 해결하는데 GenAI를 어떻게 활용하는지 소개하는 2부작 시리즈 포스팅입니다. 사례가 AWS 기술블로그를 통해 세상에 알려질 수 있게 도움주신 모든 분들에게 감사의 마음을 전합니다. Part 1: 삼성계정 서비스의 AI SecOps – Multi-Agent로 진화하는 보안 위협 탐지 Part 2: Agentic AIOps – Multi-Agent 시스템으로 Root Cause Analysis […]

엠넷플러스 실시간 글로벌 투표 시스템 아키텍처 개선 사례
소개 엠넷플러스(Mnet Plus)는 CJ ENM이 운영하는 글로벌 K-POP 콘텐츠 플랫폼으로, 론칭 3년 만에 글로벌 누적 가입자 수 4,500만 명, 최대 월간 활성 이용자 수(MAU) 2,000만 명을 돌파하며 빠르게 성장하고 있습니다. MAMA AWARDS, KCON, 보이즈 2 플래닛 등 다양한 Mnet 콘텐츠는 물론, 숨바꼭질, 온더맵 등 엠넷플러스 오리지널 콘텐츠까지 아우르며 글로벌 팬들에게 라이브 스트리밍과 VOD 서비스를 제공하고 […]

Agent 로 최적화 하는 EKS 운영: AWS DevOps Agent + K8s Operator로 MTTR 줄이기
Amazon Elastic Kubernetes Service(Amazon EKS) 환경에서 워크로드를 운영하다 보면, Pod의 OOMKilled 종료나 IP 고갈로 인한 생성 실패 등 다양한 장애 상황에 직면하게 됩니다. 이러한 장애가 발생하면 엔지니어는 Pod 로그 수집부터 Kubernetes Events 추적, 노드 시스템 로그 확인까지 반복적이고 시간 소모적인 트러블슈팅 과정을 거쳐야 합니다. 특히 야간이나 주말에는 대응 시간이 길어지고, Pod 삭제나 노드 이상으로 인해 […]

지능형 Physical AI 구축: Strands Agents, Bedrock AgentCore, Claude 4.6, NVIDIA GR00T, Hugging Face LeRobot으로 엣지에서 클라우드까지
이 글은 AWS Open Source Blog의 “Building intelligent physical AI: From edge to cloud with Strands Agents, Bedrock AgentCore, Claude 4.5, NVIDIA GR00T, and Hugging Face LeRobot by Arron Bailiss” 게시글을 번역한 글 입니다. 에이전틱 AI 시스템은 디지털 세계를 넘어 물리적 세계로 빠르게 확장되고 있으며, AI 에이전트가 실제 환경에서 인지하고, 추론하고, 행동합니다. AI 시스템이 로봇공학, […]

AWS에서 NVIDIA Cosmos 월드 파운데이션 모델 실행하기
본 게시글은 “Running NVIDIA Cosmos world foundation models on AWS by Abhishek Srivastav, Brett Hamilton, Diego Garzon, Jathavan Sriram, and Shaun Kirby“를 번역한 글입니다. 자율주행 차량, 로봇공학, 스마트 팩토리를 위한 Physical AI 시스템을 개발하고 있다면, 충분한 양의 고품질 학습 데이터를 확보하는 것이 핵심 과제일 것입니다. 이 블로그에서는 NVIDIA Cosmos™ 월드 파운데이션 모델(WFM)을 Amazon Web Services(AWS)에 […]

중앙 집중식 및 분산형 비밀 관리 방식 알아보기
이 글은 AWS Security 블로그에게시된 글 (Exploring common centralized and decentralized approaches to secrets management)을 한국어로 번역 및 편집하였습니다. Amazon Web Services (AWS)의 비밀 관리 전략에 관한 흔한 질문 중 하나는 조직이 비밀을 중앙 집중화해야 하는지입니다. 이 질문은 비밀을 중앙에 저장해야 하는지에 초점을 맞추는 경우가 많지만, 비밀 관리 프로세스를 중앙 집중화할 때 네 가지 측면인 […]

대규모 환경에서의 MCP를 활용한 효율적인 EBS 모니터링
개요 Amazon EBS(Elastic Block Store)는 Amazon EC2(Elastic Compute Cloud)의 인스턴스에 영구 블록 스토리지를 제공하는 핵심 서비스입니다. 엔터프라이즈 환경에서 수백, 수천 개의 EBS 볼륨을 운영할 때, 각 볼륨의 성능을 실시간으로 모니터링하고 병목 지점을 신속하게 파악하는 것은 서비스 안정성과 직결되는 중요한 과제입니다. Amazon CloudWatch는 EBS 볼륨에 대해 다양한 성능 지표를 제공하지만, 이를 종합적으로 분석하여 실질적인 인사이트를 얻기 […]

Amazon Bedrock과 Claude Agent SDK로 서버리스 멀티 에이전트 구현하기
Kiro CLI나 Claude Code 같은 AI 코딩 에이전트를 사용하다 보면, 코드를 분석하고 수정하고 테스트까지 실행하는 이 에이전트의 동작 방식을 자신의 애플리케이션 백엔드에도 적용할 수 있으면 좋겠다고 생각해 본 적이 있을 것입니다. 하나의 에이전트에게 코드 리뷰, 테스트 작성, 리팩터링을 모두 맡기면 컨텍스트가 길어지면서 앞서 발견한 문제를 뒤에서 잊어버리게 되고, 자신이 작성한 코드를 직접 리뷰하기 때문에 객관성이 떨어집니다. Anthropic의 멀티 에이전트 연구에 따르면, Claude Opus를 리드 에이전트로 두고 Claude Sonnet 서브 에이전트를 병렬 실행한 멀티 에이전트 시스템이 단일 Opus 대비 90.2% 더 높은 성능을 보였습니다. 이 게시글에서는 Claude Agent SDK를 AWS Lambda에서 실행하여 Orchestrator-Worker 패턴의 […]

네오사피엔스의 AWS g6e 기반 LLM 추론 배치 워크로드 최적화 사례
네오사피엔스(Neosapience)는 AI 음성 합성 및 언어 지능 기술을 바탕으로 AI 연기자 서비스인 타입캐스트(Typecast)를 운영하는 스타트업입니다. 2017년 설립 이후 딥러닝 기반의 감정 표현 및 다국어 TTS(Text-to-Speech) 원천 기술을 연구하며 콘텐츠 제작 환경의 변화를 시도해 왔으며, 현재는 글로벌 서비스로의 성장을 목표로 기술적 역량을 쌓아가고 있습니다. 이러한 서비스 운영의 핵심인 LLM 추론 최적화는 “정밀도를 낮추면 빨라진다” 수준의 단일 […]
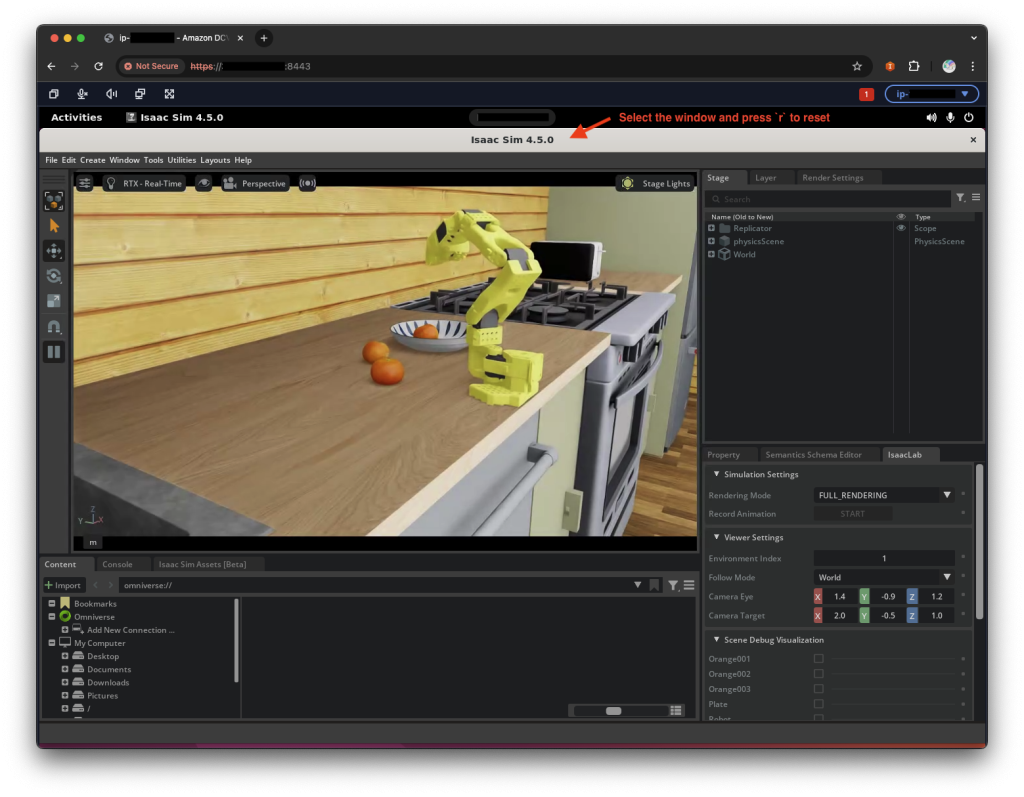
Embodied AI 블로그 시리즈, 파트 1: AWS Batch에서 로봇 학습 시작하기
https://aws.amazon.com/ko/blogs/spatial/embodied-ai-blog-series-part-1/ 의 번역 글입니다. 우리는 고급 AI 모델을 통해 디지털 세계뿐만 아니라 물리적 세계까지 영향을 미칠 수 있는, 기술 진화의 중요한 이정표에 도달했습니다. 이제 텍스트를 생성하는 AI에서 원자를 움직이는 AI로 발전하고 있습니다 — 옷을 개고, 물류를 정리하고, 복잡한 물리적 작업을 스스로 판단하여 수행하는 등 일상생활 전반을 보조합니다. 하지만 구조화되지 않은 역동적인 물리적 세계와 성공적으로 상호작용하는 […]