AWS 기술 블로그

십만 줄 코드베이스, AST로 길을 찾다 — Kiro Code Intelligence로 대규모 코드베이스를 이해하는 법
들어가며 새 코드를 작성할 때 AI 코딩 어시스턴트는 충분히 쓸 만합니다. 반면 기존 코드, 그중에서도 수년간 누적된 대규모 레거시를 다룰 때는 사정이 다릅니다. 결제 로직의 수정 시작점을 묻거나, 특정 메서드 이름을 바꿨을 때의 영향 범위를 묻거나, 방금 생성한 코드가 기존 아키텍처 규칙에 맞는지 물으면, 그럴듯하지만 실제 구조와 어긋난 답을 받는 경우가 많습니다. 생성은 잘하면서 이해에서 […]

Amazon Bedrock 위에 사내 LLM Gateway 구축하기: Claude Code, Codex를 위한 인증·비용·거버넌스
“개발자 전원에게 Claude Code를 열어주고 싶습니다. 그런데 누가 얼마를 쓰는지, 어떤 모델에 접근하는지, 예산을 넘기면 어떻게 막을지를 모른 채로 열어도 될지 확신이 서지 않습니다.” 이 고민은 2026년 현재 거의 모든 기술 조직이 마주하는 현실입니다. 생성형 AI 코딩 도구는 더 이상 실험이 아니라 일상 도구가 되었고, Claude Code는 환경변수 하나(CLAUDE_CODE_USE_BEDROCK=1)만으로 Amazon Bedrock 위에서 곧바로 동작합니다. 그리고 […]
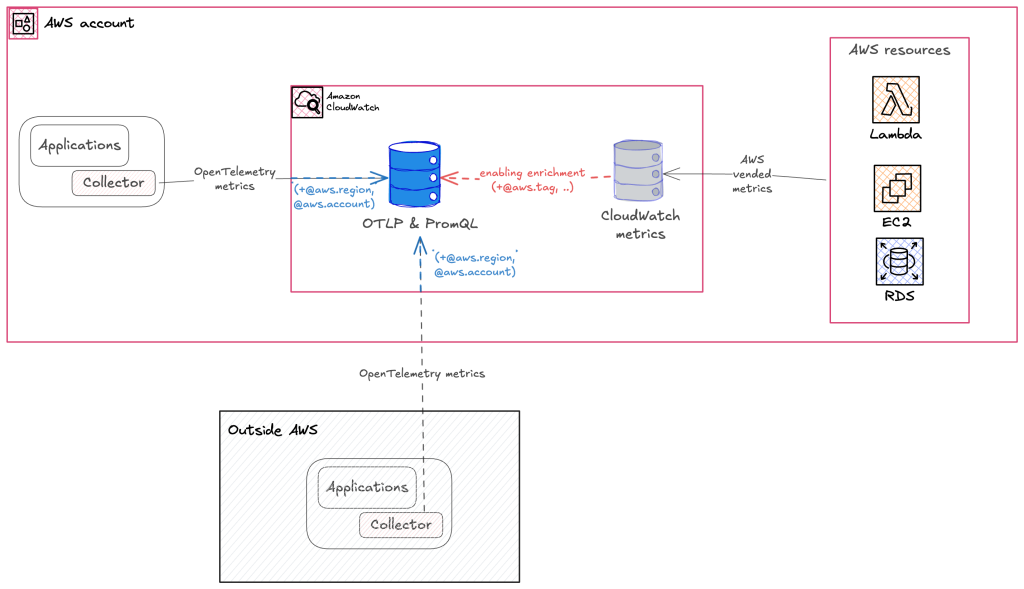
Amazon CloudWatch에서 OpenTelemetry 및 PromQL 지원 소개
본 게시글은 Introducing OpenTelemetry and PromQL support in Amazon CloudWatch by Rodrigue Koffi를 2026년 7월 정식 출시(GA) 시점의 원문을 번역했습니다. 편집자 주(2026년 7월): 이 게시물은 Amazon CloudWatch의 OpenTelemetry 지표 네이티브 수집 및 PromQL 지원 정식 출시(GA), 그리고 새로 추가된 기능과 변경된 가격 정책을 반영하여 업데이트되었습니다. AWS에서 Kubernetes 또는 마이크로서비스 워크로드를 실행한다면, 지표에는 네임스페이스, 파드, 컨테이너, […]

Amazon Aurora 및 Amazon RDS의 PostgreSQL 18: 성능 향상
이 글은 AWS Blog의 “PostgreSQL 18 on Amazon Aurora and Amazon RDS: Security, monitoring, and developer enhancements” by Nazneen Jafri, Sukhpreet Kaur Bedi, Ranjan Burman, and Baji Shaik 게시글을 번역한 글 입니다. 복합 인덱스 전반의 쿼리 성능 관리, 구체화(materialized)된 CTE에서의 메모리 스필(spill) 진단, 그리고 실행 계획의 성능저하(plan regression) 없이 메이저 버전 업그레이드 수행은 PostgreSQL 사용자라면 […]

스트라드비젼의 AWS 클라우드 기반 피지컬 AI End-to-End 파이프라인 가속화 사례
자동차가 스스로 주변상황을 인식하고 판단하려면, 수백, 수천만 장의 도로 이미지 데이터가 필요합니다. 그런데 만약 AI가 학습해야 할 상황이 현실에서는 거의 일어나지 않는 희귀한 장면이라면 어떨까요? 예를 들어, 사람이 차 바로 앞으로 뛰어드는 상황이나, 인도 도로 한복판에 소가 누워 있는 상황을 카메라로 찍어 모아야 한다면? 스트라드비젼은 자동차의 카메라가 세상을 보고 이해할 수 있게 하는 Vision AI […]

Amazon Bedrock 모델 promptfoo 로 성능 평가하기
들어가며 “프롬프트를 바꿨는데, 정말 더 나아진 걸까?” 생성형 AI 애플리케이션을 개발하는 엔지니어라면 누구나 한 번쯤 마주치는 질문입니다. 프롬프트 한 줄을 수정하거나 모델을 교체할 때마다 품질이 좋아졌는지 확신하기 어렵고, 여러 모델을 두고 어느 쪽이 서비스에 더 맞는지 판단하려면 같은 질문을 양쪽에 던져 결과를 일일이 눈으로 비교해야 합니다. 문제는 대규모 언어 모델(Large Language Model, 이하 LLM)이 비결정적(non-deterministic) […]

Oracle Database@AWS 네트워크 구성 가이드
Oracle Database@AWS(ODB@AWS)는 AWS 데이터센터 내에 위치한 Oracle Exadata 인프라에서 Oracle Database를 네티브로 실행할 수 있게 해주는 서비스입니다. Oracle MAA Platinum 인증을 획득하였으며, 애플리케이션-데이터베이스 간 RTT(Round Trip Time) 165μs의 초저지연을 달성하여 미션 크리티컬 워크로드에 적합한 성능을 제공합니다. 그러나 ODB@AWS는 기존 AWS 서비스와는 다른 고유한 네트워크 토폴로지를 가지고 있어, 엔터프라이즈 환경에서의 네트워크 설계 시 특별한 고려가 필요합니다. […]

AWS Site-to-Site VPN 무중단 운영의 정석 : BGP와 Lifecycle Control로 유지보수 장애 예방하기
들어가며 AWS Site-to-Site VPN은 온프레미스와 AWS VPC를 연결하는 가장 빠르고 간편한 방법입니다. 하지만 운영을 하다 보면 한 번쯤은 이런 경험을 하게 됩니다. “새벽에 갑자기 VPN 터널이 끊기면서 온프레미스-AWS 간 통신이 중단되었습니다. AWS 측에서 예정된 유지보수라고 하는데, 이걸 왜 미리 몰랐을까요?” 실제로 많은 고객이 AWS Site-to-Site VPN 사용 중 터널 유지보수(Tunnel Endpoint Maintenance)로 인한 서비스 장애를 반복적으로 […]

AWS Elemental Inference를 활용한 실시간 문맥 광고(Contextual Advertising) 솔루션
AWS Elemental Inference Smart Subtitle, Amazon Bedrock, SCTE-35를 결합하여 라이브 방송 콘텐츠의 문맥을 실시간으로 이해하고, 최적의 시점에 문맥 기반 광고를 배치하는 아키텍처를 구축합니다. 이 블로그에서는 라이브 콘텐츠의 음성을 실시간으로 자막화하고, 그 자막의 문맥을 AI가 분석하여 IAB(Interactive Advertising Bureau) 카테고리로 분류한 뒤, 표준 SCTE-35 오버레이 시그널(segmentation_type_id 0x38)을 통해 AWS Elemental MediaTailor와 연동하는 전체 파이프라인을 설명합니다. 소개 […]

AWS DevOps Agent 를 활용한 성능 테스트 결과 분석
1. 개요 AWS DevOps Agent는 인시던트 대응을 위한 자율형 AI 에이전트입니다. 장애가 발생하면 AWS 리소스를 AWS Native 도구와 연결 설정 된 외부 모니터링 도구로 부터 메트릭, 로그를 자동으로 수집 및 분석하고, 근본 원인을 파악하여 우선순위가 지정된 권장사항을 제공합니다. 그런데 한 발 물러서 생각해보면, 성능 테스트 결과 분석도 본질은 같습니다 — “특정 시간대에 시스템에 부하가 가해졌을 […]