Criação de painéis para visibilidade operacional
Operações e entrega de software | NÍVEL 300
Introdução
Todos nós executamos aplicações em laptops, tablets e smartphones. É fácil perceber se o dispositivo está ligado e se a conexão da rede Wi-Fi está online. Sabemos que nossas telas mostrarão quaisquer notificações críticas, como alertas de pouco espaço em disco. Na realidade, a velocidade geral e a capacidade de resposta da interface do usuário (IU) podem ser um bom indicador para saber se o dispositivo tem recursos suficientes, como memória ou CPU, para executar nossas aplicações.
Qualquer pessoa que tenha prestado suporte técnico remoto para dispositivos da própria família pode confirmar que é um pouco mais difícil detectar e diagnosticar problemas quando você não pode ver e interagir diretamente com o dispositivo. Portanto, no que se refere a serviços baseados em nuvem em execução, enfrentamos um desafio parecido: como monitorar esses serviços remotos e como sabemos que nossos clientes estão satisfeitos?
Para observar um serviço com um único host, podemos fazer login nesse host, executar várias ferramentas de monitoramento do tempo de execução e inspecionar os logs para determinar a causa raiz do que está acontecendo no host. Contudo, as soluções com um único host são viáveis apenas para os serviços mais simples e não essenciais. No outro extremo estão os microsserviços multicamadas distribuídos que são executados em centenas de milhares de servidores, contêineres ou ambientes sem servidor.
Como a Amazon verifica o comportamento real de todos os serviços baseados em nuvem que estão em execução em várias zonas de disponibilidade nas diversas regiões em todo o mundo? O monitoramento, os fluxos de trabalho de remediação (por exemplo, deslocamento de tráfego) e os sistemas de implantação, todos automatizados, são essenciais para detectar e resolver a grande maioria dos problemas nessa escala. No entanto, por vários motivos, ainda precisamos ver o que esses serviços, fluxos de trabalho e implantações estão fazendo a qualquer momento em que isso for necessário.
Uso de painéis na Amazon
Usamos painéis como um mecanismo para enfrentar o desafio de permanecer ciente das atividades em nossos serviços de nuvem. Os painéis são as visualizações de nossos sistemas vistas por humanos. Esses painéis fornecem resumos sucintos de como o sistema está se comportando exibindo métricas de séries temporais, logs, rastreamentos e dados de alarmes.
Na Amazon, nos referimos à criação, ao uso e à manutenção contínua desses painéis como “dashboarding” (uso de painéis). O uso de painéis evoluiu para uma atividade de primeira classe porque é tão essencial para o sucesso de nossos serviços quanto outras atividades operacionais e de entrega de software cotidianas, como projetar, codificar, compilar, testar, implantar e escalar nossos serviços.
É claro que não esperamos que nossos operadores monitorem os painéis o tempo todo. Na maior parte do tempo, ninguém observa esses painéis. Na verdade, descobrimos que qualquer processo operacional que exija uma análise manual dos painéis falhará devido a erro humano, não importa com que frequência os painéis sejam analisados. Para lidar com esse risco, criamos alarmes automatizados que avaliam constantemente os dados de monitoramento mais importantes que nossos sistemas estão emitindo. Normalmente, eles são métricas que indicam se o sistema está se aproximando de algum limite (detecção proativa,antes do impacto) ou se o sistema já está prejudicado de alguma maneira inesperada (detecção reativa, após o impacto).
Esses alarmes podem executar fluxos de trabalho de remediação automatizados e notificar nossos operadores sobre a existência de um problema. A notificação direciona o operador para os painéis e runbooks que ele precisa usar. Quando estou em uma chamada e uma notificação de alarme me alerta sobre um problema, posso usar rapidamente os painéis relacionados para quantificar o impacto no cliente, validar ou classificar a causa raiz, mitigar, e também reduzir o tempo de recuperação. Mesmo que o alarme já tenha iniciado um fluxo de trabalho de remediação automatizado, preciso ver o que esse fluxo de trabalho está fazendo, qual o efeito dele no sistema e, em circunstâncias excepcionais, acelerar o fluxo de trabalho fornecendo confirmação humana para etapas essenciais à segurança.
Quando um evento está em andamento, a Amazon normalmente mobiliza vários operadores de chamadas. É possível que os operadores estejam usando painéis diferentes enquanto avançam por uma sequência de tarefas. Normalmente, essas tarefas incluem a quantificação do impacto nos clientes, a triagem, o rastreamento pelos vários serviços até a causa raiz do evento, a observação de fluxos de trabalho de remediação automatizados, bem como a execução e a validação de etapas de mitigação baseadas em runbooks. Enquanto isso, equipes parceiras e partes comerciais interessadas também estão usando os painéis para monitorar o impacto contínuo durante o evento. Esses diferentes participantes se comunicam usando ferramentas de gerenciamento de incidentes, salas de bate-papo (com bots como o AWS Chatbot) e chamadas em conferência. Cada parte interessada traz uma perspectiva diferente sobre os dados que precisam ver nos painéis.
Toda semana, as equipes da Amazon e organizações maiores também realizam reuniões para análise de operações. Os participantes são líderes sênior, gerentes e muitos engenheiros. Durante essas reuniões, usamos uma roleta da sorte a fim de escolher os painéis para uma auditoria de alto nível. As partes interessadas analisam a experiência de nossos clientes e os principais objetivos de nível de serviço, como disponibilidade e latência. Os painéis de auditoria que essas partes interessadas usam normalmente mostram dados operacionais de todas as zonas de disponibilidade e regiões.
Além disso, ao fazer o planejamento e a previsão de capacidade em logo prazo, a Amazon usa painéis que visualizam as métricas de alto nível de negócios, uso e capacidade que nosso sistema emite durante intervalos mais longos.
Tipos de painéis
As pessoas usam painéis para monitorar serviços manualmente, mas não há uma solução universal para todos os casos de uso. Para a maioria dos sistemas, usamos muitos painéis, cada um oferecendo uma visualização diferente do sistema. Essas diferentes visualizações permitem que diferentes usuários entendam como nossos sistemas estão se comportando a partir de diferentes perspectivas e em diferentes períodos.
Os dados que cada público quer ver podem variar significativamente de painel para painel. Aprendemos a manter o foco no público pretendido quando projetamos os painéis. Decidimos quais dados são apresentados em cada painel com base em quem usará o painel e porque usará. Você provavelmente ouviu falar que, na Amazon, trabalhamos de trás para frente a partir do cliente. A criação de painéis é um bom exemplo disso. Criamos painéis baseados nas necessidades dos usuários esperados e em seus requisitos específicos.
O diagrama a seguir ilustra como diferentes painéis fornecem diferentes visualizações do sistema como um todo:
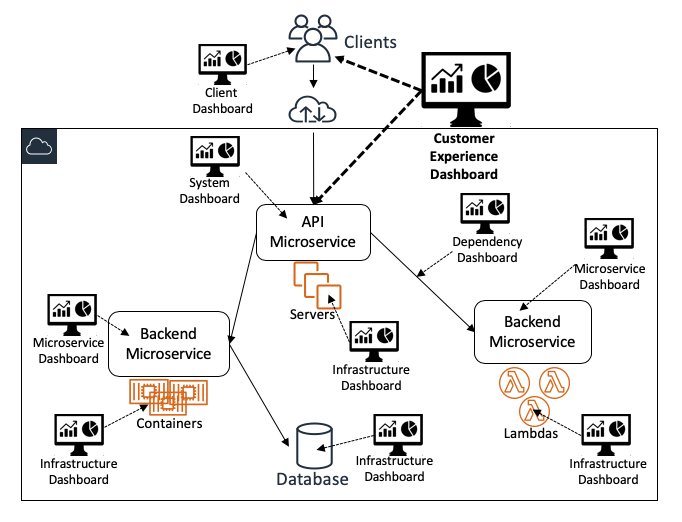
Painéis de alto nível
Painéis de experiência do cliente
Na Amazon, nossos painéis mais importantes e amplamente utilizados são os painéis de experiência do cliente. Eles são projetados para serem utilizados por um amplo grupo de usuários que inclui operadores de serviços e muitas outras partes interessadas. Os painéis apresentam, com eficiência, métricas sobre a integridade geral dos serviços e a aderência a metas. Eles exibem dados de monitoramento cuja origem está no próprio serviço e também na instrumentação do cliente, testadores contínuos (como os canários do Amazon CloudWatch Synthetics) e sistemas de remediação automatizados. Esses painéis também contêm dados que ajudam os usuários a responder a perguntas sobre a profundidade e a amplitude do impacto. Algumas dessas perguntas provavelmente são “Quantos clientes são afetados?” e “Quais clientes são os mais afetados?”.
Painéis em nível de sistema
Os pontos de entrada para nossos serviços baseados em Web normalmente são endpoints da IU e de API, assim os painéis dedicados em nível de sistema devem conter dados suficientes para que os operadores vejam como o sistema e seus endpoints voltados para o cliente estão se comportando. Esses painéis exibem principalmente os dados de monitoramento em nível de interface. Eles mostram três categorias de dados de monitoramento para cada API:
- Dados de monitoramento relacionados a entradas. Esse tipo de dados pode incluir contagens de solicitações recebidas ou trabalho obtido de filas/streams, percentis em tamanho de byte de solicitações e contagens de falhas na autenticação/autorização.
- Dados de monitoramento relacionados a processamento. Esses dados incluem contagens de execução de caminho/ramificação da lógica de negócios multimodal, percentis de contagens/falhas/latência de solicitações de microsserviços do back-end, saída de logs de falhas e erros, e dados de rastreamento de solicitações.
- Dados de monitoramento relacionados a saídas. Podem incluir contagens de tipos de respostas (com detalhamentos relacionados a respostas de erro/falha pelo cliente), tamanho das respostas e percentis referentes ao tempo de gravação do primeiro byte da resposta e tempo de gravação da resposta completa.
Geralmente, nossa meta é manter esses painéis de experiência do cliente e em nível de sistema com o mais alto nível possível. Evitamos deliberadamente a tentação de incluir muitas métricas nesses painéis porque a sobrecarga de informações pode desviar a atenção da mensagem principal que esses painéis precisam transmitir.
Painéis de instâncias de serviços
Criamos alguns painéis para facilitar a avaliação rápida e abrangente da experiência do cliente em uma única instância de serviço (partição ou célula). Essa visualização restrita garante que os operadores que trabalham em uma única instância de serviço não fiquem sobrecarregados com dados irrelevantes de outras instâncias de serviços.
Painéis de auditoria de serviços
Também criamos painéis de experiência do cliente que exibem intencionalmente os dados de todas as instâncias de um serviço em todas as zonas de disponibilidade e regiões. Esses painéis de auditoria de serviços são usados por operadores para auditar alarmes automatizados em todas as instâncias de serviços. Esses alarmes também podem ser revisados durante as reuniões semanais de operações mencionadas anteriormente.
Painéis de planejamento e previsão de capacidade
Para casos de uso de longo prazo, também desenvolvemos painéis de planejamento de capacidade e previsões para nos ajudar a visualizar o crescimento dos nossos serviços.
Painéis de baixo nível
Normalmente, as APIs da Amazon são implementadas pela orquestração de solicitações nos microsserviços de back-end. Esses microsserviços podem pertencer a diferentes equipes, cada uma sendo responsável por algum aspecto específico do processamento da solicitação. Por exemplo, alguns microsserviços são dedicados à autenticação e autorização de solicitações, aplicação limites/controle de utilização, medição do uso, criação/atualização/exclusão de recursos, recuperação de recursos de armazenamentos de dados e inicialização de fluxos de trabalho assíncronos. Normalmente, as equipes criam no mínimo um painel dedicado específico do microsserviço que mostra as métricas de cada API, ou unidade de trabalho se o serviço estiver processando dados assincronamente.
Painéis específicos de microsserviços
Os painéis de microsserviços normalmente mostram dados de monitoramento específicos da implementação que exigem profundo conhecimento do serviço. Esses painéis são usados principalmente pelas equipes que são proprietárias dos serviços. No entanto, como nossos serviços contêm muita instrumentação, precisamos apresentar os dados dessa instrumentação de uma maneira que não sobrecarregue os operadores. Sendo assim, esses painéis normalmente exibem alguns dados de maneira agregada. Quando os operadores identificam anomalias nos dados agregados, normalmente usam várias outras ferramentas para se aprofundarem, executando consultas ad-hoc nos dados de monitoramento subjacentes que desagregam os dados, rastreiam solicitações e revelam dados relacionados ou correlacionados.
Painéis de infraestrutura
Nosso serviços são executados na infraestrutura da AWS, que normalmente emite métricas. Por essa razão, também temos painéis de infraestrutura dedicados. Esses painéis têm como foco principal as métricas emitidas pelos recursos computacionais em que nossos sistemas são executados, como instâncias do Amazon Elastic Compute Cloud (EC2), contêineres do Amazon Elastic Container Service (ECS)/Amazon Elastic Kubernetes Service (EKS) e funções do AWS Lambda. Métricas como utilização de CPU, tráfego de rede, E/S de disco e utilização de espaço são usadas comumente nesses painéis, junto com qualquer cluster relacionado, Auto Scaling e métricas de cotas que forem relevantes para esses recursos computacionais.
Painéis de dependência
Em muitos casos, além dos recursos computacionais, os microsserviços dependem de outros microsserviços. Mesmo que as equipes proprietárias dessas dependências já tenham seus próprios painéis, cada proprietário de microsserviço normalmente cria painéis de dependência dedicados para fornecer uma visualização de como as dependências em etapas anteriores do processo (por exemplo, proxies e load balancers) e as dependências em etapas posteriores do processo (por exemplo, armazenamentos de dados, filas e streams) estão se comportando, conforme a medição dos respectivos serviços. Esses painéis também podem ser usados para monitorar outras métricas essenciais, como datas de expiração de certificados de segurança e outra utilização da cota de dependências.
Projeto de painéis
Na Amazon, consideramos a consistência na apresentação dos dados como de suma importância para a criação bem-sucedida de um painel. Para que um painel seja eficaz, a consistência precisa estar presente nele e em todos os painéis. No decorrer dos anos, identificamos, adaptamos e refinamos um conjunto comum de idiomas e convenções de design que, acreditamos, torna os painéis acessíveis para a maior parte do público. Isso, em última análise, aumenta o valor deles para nossa organização. Encontramos maneiras sutis de mensurar e melhorar essas convenções de design com o tempo. Por exemplo, se um novo operador puder entender e usar rapidamente os dados apresentados nos painéis para saber como um serviço funciona, isso é um indicativo de que esses painéis estão apresentando as informações certas da maneira correta.
Uma tendência muito comum ao projetar painéis é superestimar ou subestimar o conhecimento que o usuário pretendido tem sobre o domínio. É fácil criar um painel que faça total sentido para seu criador. Contudo, esse painel pode não ser de grande valor para os usuários. Usamos a técnica de trabalhar de trás para frente a partir do cliente (neste caso, a partir dos usuários do painel) para eliminar esse risco.
Adotamos uma convenção de projeto que padroniza o layout dos dados em um painel. Os painéis são renderizados de cima para baixo, e os usuários tendem a interpretar os gráficos renderizados primeiro (visíveis quando o painel é carregado) como os mais importantes. Assim, nossa convenção de projeto aconselha colocar os dados mais importantes na parte superior do painel. Descobrimos que os gráficos de disponibilidade agregados/resumidos e os gráficos de percentis de latência de uma extremidade a outra normalmente são os painéis mais importantes para Web services.
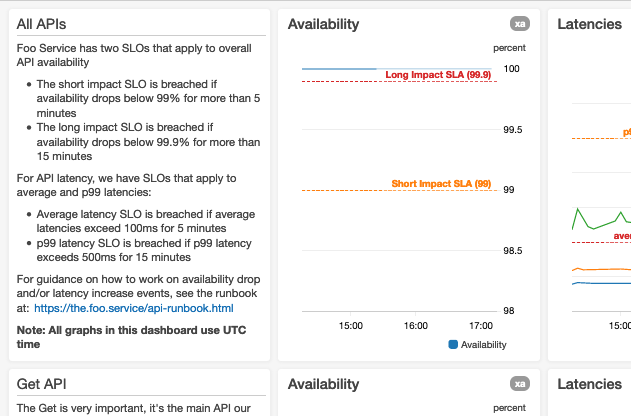
Confira uma captura de tela da parte superior de um painel de um Foo Service hipotético:
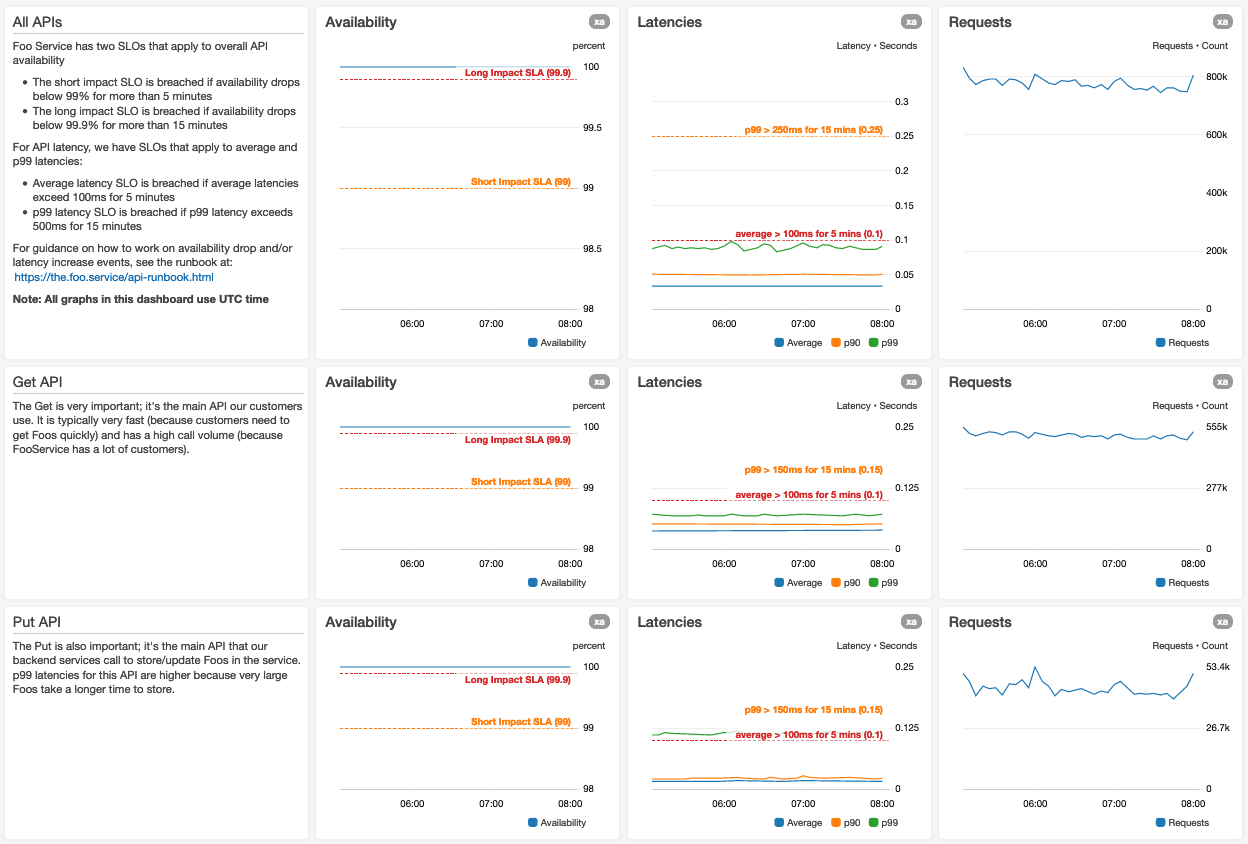
Usamos gráficos maiores para as métricas mais importantes
Se tivermos muitas métricas em um gráfico, garantimos que as legendas do gráfico não espremam vertical ou horizontalmente os dados visíveis nele. Se estivermos usando consultas de pesquisa nos gráficos, garantiremos que haverá espaço para um conjunto de resultado de métricas maior que o normal.
Dispomos os gráficos para a menor resolução gráfica esperada
Isso evita que os usuários sejam forçados a rolar horizontalmente. Um operador em chamada em um laptop às 3h pode não perceber a barra de rolagem horizontam sem uma pista visual óbvia de que há mais gráficos à direita.
Exibimos o fuso horário
Para painéis que exibem dados de data e hora, garantimos que o fuso horário relacionado esteja visível no painel. Para painéis que são usados simultaneamente por operadores em diferentes fusos horários, usamos um fuso horário (UTC) como padrão que todos os usuários podem consultar. Dessa maneira, os usuários podem se comunicar entre si usando um único fuso horário, poupando o tempo e o esforço de fazer excessivas conversões mentais de fusos horários.
Usamos o menor intervalo e período de ponto de dados
Como padrão, adotamos o intervalo e o período de ponto de dados relevantes para a maioria dos casos de uso comuns. Garantimos que todos os gráficos em um painel exibam dados inicialmente para o mesmo período e resolução. Descobrimos que será benéfico se todos os gráficos em uma seção do painel tiverem o mesmo tamanho horizontal. Isso permite a fácil correlação de tempo entre os gráficos.
Também evitamos representar muitos pontos de dados nos gráficos porque isso reduz o tempo de carregamento do painel. Além disso, observamos que a exibição de pontos de dados excessivos para o usuário pode, na verdade, reduzir a visibilidade das anomalias. Por exemplo, um gráfico de um intervalo de três horas de pontos de dados com resolução de um minuto com apenas 180 valores por métrica será renderizado claramente até nos menores widgets do painel. Esse número de pontos de dados também fornece contexto suficiente aos operadores que estão fazendo a triagem de eventos operacionais contínuos.
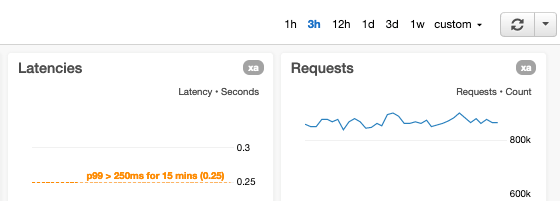
Ativamos a capacidade de ajustar o intervalo e o período da métrica
Nossos painéis fornecem controles para ajustar rapidamente o intervalo e o período da métrica de todos os gráficos. Outras proporções comuns entre intervalo e resolução que usamos em nossos painéis são:
- 1 hora x 1 minuto (60 pontos de dados): útil para observar eventos contínuos mais de perto
- 12 horas x 1 minuto (720 pontos de dados)
- 1 dia x 5 minutos (288 pontos de dados): útil para visualizar tendências diárias
- 3 dias x 5 minutos (864 pontos de dados)
- 1 semana x 1 hora (168 pontos de dados): útil para visualizar tendências semanais
- 1 mês x 1 hora (744 pontos de dados)
- 3 meses x 1 dia (90 pontos de dados): útil para visualizar tendências trimestrais
- 9 meses x 1 dia (270 pontos de dados)
- 15 meses x 1 dia (450 pontos de dados): útil para análises de capacidade de longo prazo
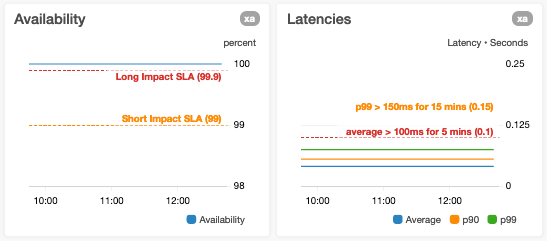
Anotamos os gráficos com limites de alarme
Quando criamos gráficos com métricas que têm alarmes automatizados relacionados, se os limites de alarme forem estáticos, anotamos os gráficos com linhas horizontais. Se os limites de alarme forem dinâmicos, ou seja, baseados em previsões geradas usando inteligência artificial (IA) ou machine learning (ML), exibimos as métricas reais e de limite no mesmo gráfico. Se um gráfico mostra uma métrica que mede um aspecto do serviço que tem limites conhecidos (como um limite “máximo testado” ou um limite de recursos rígido), anotamos o gráfico com uma linha horizontal indicando onde os limites conhecidos ou testados estão. Para métricas que têm metas, adicionamos linhas horizontais para tornar essas metas imediatamente visíveis para o usuário.
Evitamos adicionar linhas horizontais aos gráficos que já usam um eixo y à esquerda e um à direita.
Se você adicionar linhas horizontais a esses gráficos, os usuários podem considerar difícil saber a qual eixo y a linha horizontal se relaciona. Para evitar essa ambiguidade, dividimos gráficos como esse em dois que usam apenas um único eixo horizontal e adicionamos as linhas horizontais somente ao gráfico apropriado.
Evitamos sobrecarregar um eixo y com várias métricas que tenham faixas de valores muito diferentes
Evitamos essa situação porque ela pode resultar em visibilidade reduzida na variância de uma ou mais métricas. Um exemplo disso é quando plotamos as latências p0 (mínima) e p100 (máxima) no mesmo gráfico em que os valores dos pontos de dados de p100 podem ser ordens de magnitude maiores que pontos de dados de p0.
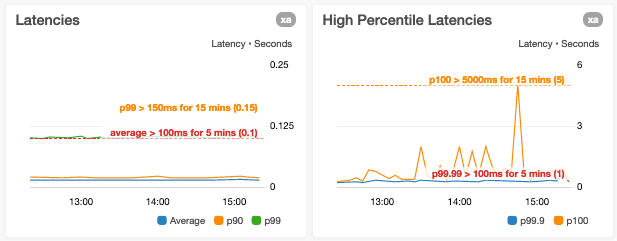
Evitamos restringir os limites do eixo Y apenas ao intervalo de valores dos pontos de dados atuais
Uma olhada casual para um gráfico com a faixa do eixo y limitada aos valores do ponto de dados pode fazer uma métrica parecer muito mais variável do que realmente é.
Evitamos sobrecarregar gráficos únicos
Queremos garantir que não temos muitas estatísticas ou métricas não relacionadas em um único gráfico. Por exemplo, ao adicionar gráficos para processamento de solicitações, normalmente criamos gráficos adjacentes separados no painel referentes ao seguinte:
- % de disponibilidade (falhas/solicitações * 100)
- Latências p10, média, p90
- Latências p99.9 e máxima (p100)
Não assumimos que o usuário saiba exatamente o que cada métrica ou widget significa
Isso se aplica especificamente a métricas específicas da implementação. Queremos fornecer contexto suficiente no texto do painel, por exemplo, com o texto da descrição ao lado ou abaixo de cada gráfico. O operador pode ler esse texto para entender o que a métrica significa. Em seguida, o operador pode interpretar o que é “normal” e o que isso poderia significar se o gráfico não estiver “normal”. Nesse texto, fornecemos links para os recursos relacionados que um operador pode usar para determinar a causa raiz. Veja alguns exemplos dos tipos de links que fornecemos:
- Para runbooks. Para especialistas no assunto, o painel pode ser o runbook.
- Para painéis de “aprofundamento” relacionados.
- Para painéis equivalentes de outros clusters ou partições.
- Para pipelines de implantação.
- Para as informações de contato das dependências.
Usamos status de alarme, números simples e/ou widgets de gráficos de séries temporais onde for apropriado
Dependendo dos casos de uso do painel, consideramos que exibir um widget que contenha um único número (por exemplo, o valor mais recente de uma métrica) ou o status de alarme pode ser mais apropriado do que exibir um gráfico complexo de série temporal de todos os pontos de dados recentes.

Evitamos confiar em gráficos que exibem métricas esparsas
Métricas esparsas são métricas emitidas apenas quando existe alguma condição de erro. Embora possa ser eficiente instrumentar serviços para emitir essas métricas somente quando necessário, os usuários do painel podem ser confundidos por gráficos vazios ou quase vazios. Quando encontramos essas métricas ao projetar painéis, normalmente modificamos o serviço para emitir continuamente valores seguros (ou seja, zero) para essas métricas na ausência da condição de erro. Assim os operadores podem entender facilmente que a ausência de dados implica que o serviço não está emitindo a telemetria corretamente.
Adicionamos mais gráficos que exibem métricas por modo
Fazemos isso quando estamos exibindo gráficos de métricas que agregam comportamento de vários modelos em nosso sistemas. Algumas circunstâncias quando podemos fazer isso incluem:
- Se um serviço for compatível com solicitações de tamanhos variados, podemos criar um gráfico para as latências gerais das solicitações. Além disso, também podemos criar gráficos que exibem métricas para pequenas, médias e grandes solicitações.
- Se um serviço executa métricas de maneiras variáveis dependendo dos valores (ou combinações) de parâmetros de entrada, então podemos adicionar gráficos para métricas que capturam cada modo de execução.
Manutenção de painéis
Criar painéis que apresentam várias visualizações de nossos sistemas é a primeira etapa. No entanto, nossos sistemas estão evoluindo e se expandindo constantemente, e os painéis precisam evoluir junto com eles, já que novos recursos são adicionados e as arquiteturas são aperfeiçoadas. A manutenção e a atualização dos painéis está arraigada em nosso processo de desenvolvimento. Antes de concluir as alterações, e durante as revisões de código, nossos desenvolvedores perguntam: “Preciso atualizar algum painel?”. Eles estão capacitados para fazer alterações nos painéis antes que as mudanças subjacentes sejam implantadas. Isso evita a situação em que o operador tem de atualizar os painéis durante ou após a implantação do sistema para validar a alteração sendo implantada.
Se um painel contém muito mais informações detalhadas do que o normal, isso pode indicar que o operador está confiando nesse painel para detecção manual de anomalias em lugar de alarmes e remediação automatizados. Auditamos nossos painéis continuamente para determinar se podemos reduzir esse esforço manual melhorando a instrumentação em nossos serviços e aperfeiçoar nossos alarmes automatizados. Também eliminamos ou atualizamos agressivamente os gráficos que não agregam mais valor aos painéis.
Ao permitir que nossos desenvolvedores atualizem painéis, garantimos que temos um conjunto completo e idêntico de painéis para nossos ambientes de pré-produção (alfa, beta ou gama). Nossos pipelines de implantação automatizados implantam as alterações primeiro nos ambientes de pré-produção. Portanto, nossas equipes devem ser capazes de validar facilmente as alterações nesses ambientes de teste usando os painéis associados (e alarmes automatizados) de uma maneira que seja exatamente consistente com a maneira como eles serão validados quando as alterações forem enviadas para nossos ambientes de produção.
A maioria dos sistemas está evoluindo continuamente conforme os requisitos são atualizados, novos recursos são adicionados e as arquiteturas de software mudam para acomodar o dimensionamento ao longo do tempo. Nossos painéis são um componente essencial de nossos sistemas, portanto, seguimos o processo de Infrastructure-as-Code (IaC – Infraestrutura como código) para a manutenção desses painéis. Esse processo garante que nossos painéis sejam mantidos em sistemas de controle de versão e que as alterações sejam implantadas em nossos painéis usando as mesmas ferramentas que nossos desenvolvedores e operadores usam para nossos serviços.
Quando conduzimos o post-mortem de um evento operacional inesperado, nossas equipes analisam se as melhorias nos painéis (e alarmes automatizados) poderiam ter previsto o evento, identificado a causa raiz mais rapidamente ou reduzido o tempo médio de recuperação. Normalmente nos perguntamos: “Retrospectivamente, os painéis mostraram claramente o impacto no cliente, ajudaram os operadores a triangular para determinar a causa raiz final e auxiliaram na medição do tempo de recuperação?”. Se a resposta a qualquer uma dessas perguntas for não, então nossos post-mortens incluem ações para refinar esses painéis.
Conclusão
Na Amazon, operamos serviços de grande escala em todo o mundo. Nossos sistemas automatizados monitoram, detectam, alertam e corrigem constantemente os eventuais problemas ocorridos. Precisamos da capacidade de monitorar, nos aprofundar, auditar e revisar esses serviços e sistemas automatizados. Para conseguir isso, construímos e mantemos painéis que fornecem muitas visões diferentes de nossos sistemas. Projetamos esses painéis para públicos amplos e específicos, trabalhando de trás para frente a partir dos usuários do painel. Para tornar os painéis mais fáceis de entender para os operadores e proprietários de serviços, usamos um conjunto consistente de expressões idiomáticas e convenções de design para garantir a capacidade de uso e utilidade do painel.
Nossos painéis fornecem muitas perspectivas e visualizações diferentes sobre como os serviços da AWS estão operando. Eles desempenham um papel fundamental na entrega de uma ótima experiência ao cliente, ajudando as equipes da Amazon a compreender, operar e dimensionar nossos serviços. Esperamos que este artigo ajude você a projetar, criar e manter seus próprios painéis. Se você quiser ver um exemplo de como criar painéis usando os serviços da AWS, assista a este vídeo rápido e confira um guia de autoatendimento.
Sobre o autor
John O'Shea é engenheiro-chefe na Amazon Web Services. Seu foco atual é o Amazon CloudWatch e outros serviços de monitoramento e observabilidade internos da Amazon.

Conteúdo relacionado
Você encontrou o que estava procurando hoje?
Ajude-nos a melhorar a qualidade do conteúdo em nossas páginas