Artificial Intelligence
Run Deep Learning Frameworks with GPU Instance Types on Amazon EMR
Today, AWS is excited to announce support for Apache MXNet and new generation GPU instance types on Amazon EMR, which enables you to run distributed deep neural networks alongside your machine learning workflows and big data processing. Additionally, you can install and run custom deep learning libraries on your EMR clusters with GPU hardware. Through using deep learning frameworks, you have a new toolkit to address use cases ranging from autonomous vehicles to artificial intelligence (AI) to personalized healthcare to computer vision.
Amazon EMR provides a managed Hadoop framework that makes it easy, fast, and cost-effective to process vast amounts of data in Amazon S3 with frameworks like Apache Spark, Apache Hive, Presto, Apache HBase, and Apache Flink. You can securely and performantly address a large set of big data use cases at low cost, including log analysis, web indexing, data transformations (ETL), financial analysis, scientific simulation, real-time processing, and bioinformatics.
EMR has a long history in enabling you to run scalable machine learning workloads. In 2013, we added support for Apache Mahout to help you use Apache Hadoop MapReduce to run distributed machine learning workloads. In 2014, customers started leveraging Apache Spark (we added official support in 2015) to easily build scalable machine learning pipelines with the variety of open-source machine learning libraries available in Spark ML.
In the past 2 years, we also added support for Apache Zeppelin notebooks, easy installation for Jupyter notebooks, and Apache Livy for interactive Spark workloads to enable data scientists to easily and quickly develop, train, and move machine learning models into production. With EMR’s per-second billing and cost savings up to 80% by using Amazon EC2 Spot Instances, you can easily run your machine learning pipelines at a massive scale but low cost.
Today, we are making it easier to implement deep learning on Amazon EMR. We have added support for Apache MXNet (0.12.0), a scalable deep learning framework, and Amazon EC2 P3 and P2 instances, EC2 compute-optimized GPU instances, preloaded with the required GPU drivers. You can now quickly and easily create scalable and secure clusters with the latest GPU hardware for distributed training with a few clicks. Furthermore, you can install and use custom deep learning libraries like BigDL or CaffeOnSpark by preloading them on a custom Amazon Linux AMI or using bootstrap actions to customize your cluster. Additionally, EMR will soon add support for TensorFlow, another popular deep learning framework.
EMR makes it easy to combine both the data exploration and preprocessing phases of development with developing and training deep learning models. First, you can easily and cost-effectively use a variety of open-source big data frameworks including Apache Spark, Apache Hadoop, and Apache Hive to explore and process large datasets in S3.
Second, you can then use MXNet and Spark to make predictions or perform inference in addition to developing, training, and running deep learning models with preprocessed data stored in S3 or on-cluster HDFS. You pay per-second, and you can set your own maximum price for EC2 Spot Instances and use Auto Scaling. Then, you can shut down your cluster and stop paying for it when your workloads are complete, to further lower costs of experimentation and production.
You can quickly create an EMR cluster with one to thousands of nodes with Spark, MXNet, Ganglia monitoring, and Zeppelin notebooks with a just few clicks in the EMR console.
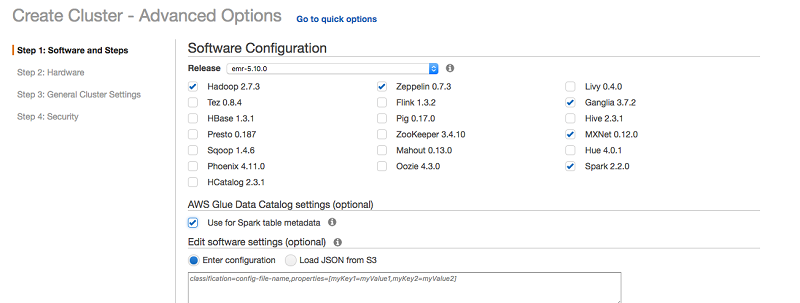
After your cluster has started, you can open up your Zeppelin notebook and start exploring data and building models with Spark and MXNet.

EMR makes it easy to monitor and debug your applications through any of the following:
- View the detailed Spark application history directly in the EMR console
- Use Amazon CloudWatch metrics
- View on-cluster Hadoop UIs
- Push application logs directly to S3
- Use Ganglia for resource use metrics
We plan to publish additional posts soon with examples of and best practices on leveraging MXNet and other frameworks on EMR for deep learning at scale. For more information about how to get started, see the Amazon EMR documentation.
About the Author
 Jonathan Fritz is the Principal Product Manager for Amazon EMR. He leads product management for the team and works to make analytics and machine learning easy on vast amounts of data. In his spare time, he enjoys traveling to new cities, live music, and exploring the outdoors.
Jonathan Fritz is the Principal Product Manager for Amazon EMR. He leads product management for the team and works to make analytics and machine learning easy on vast amounts of data. In his spare time, he enjoys traveling to new cities, live music, and exploring the outdoors.