AWS Big Data Blog
Category: Amazon EMR

Enterprise scale in-place migration to Apache Iceberg: Implementation guide
Organizations managing large-scale analytical workloads increasingly face challenges with traditional Apache Parquet-based data lakes with Hive-style partitioning, including slow queries, complex file management, and limited consistency guarantees. Apache Iceberg addresses these pain points by providing ACID transactions, seamless schema evolution, and point-in-time data recovery capabilities that transform how enterprises handle their data infrastructure. In this post, we demonstrate how you can achieve migration at scale from existing Parquet tables to Apache Iceberg tables. Using Amazon DynamoDB as a central orchestration mechanism, we show how you can implement in-place migrations that are highly configurable, repeatable, and fault-tolerant.
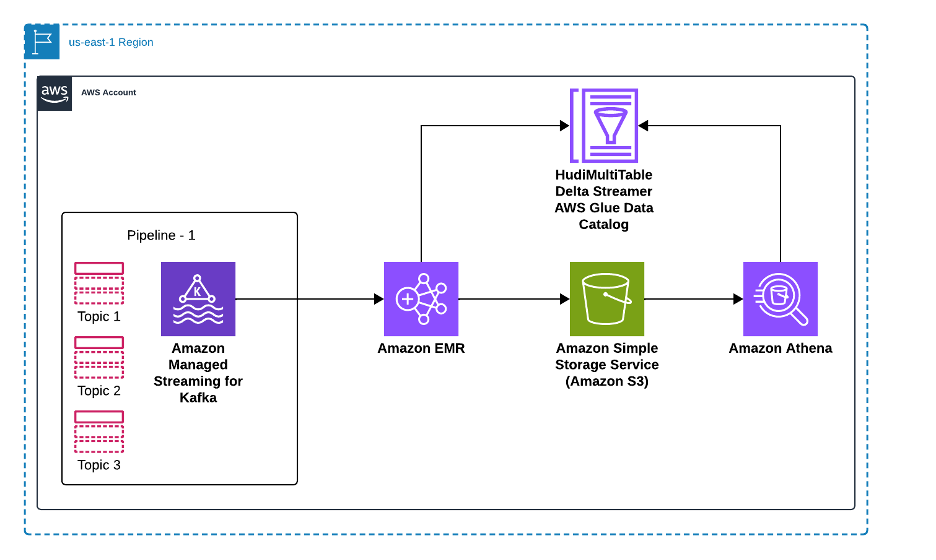
Using Amazon EMR DeltaStreamer to stream data to multiple Apache Hudi tables
In this post, we show you how to implement real-time data ingestion from multiple Kafka topics to Apache Hudi tables using Amazon EMR. This solution streamlines data ingestion by processing multiple Amazon Managed Streaming for Apache Kafka (Amazon MSK) topics in parallel while providing data quality and scalability through change data capture (CDC) and Apache Hudi.

How Slack achieved operational excellence for Spark on Amazon EMR using generative AI
In this post, we show how Slack built a monitoring framework for Apache Spark on Amazon EMR that captures over 40 metrics, processes them through Kafka and Apache Iceberg, and uses Amazon Bedrock to deliver AI-powered tuning recommendations—achieving 30–50% cost reductions and 40–60% faster job completion times.

AWS analytics at re:Invent 2025: Unifying Data, AI, and governance at scale
re:Invent 2025 showcased the bold Amazon Web Services (AWS) vision for the future of analytics, one where data warehouses, data lakes, and AI development converge into a seamless, open, intelligent platform, with Apache Iceberg compatibility at its core. Across over 18 major announcements spanning three weeks, AWS demonstrated how organizations can break down data silos, […]

Amazon EMR Serverless eliminates local storage provisioning, reducing data processing costs by up to 20%
In this post, you’ll learn how Amazon EMR Serverless eliminates the need to configure local disk storage for Apache Spark workloads through a new serverless storage capability. We explain how this feature automatically handles shuffle operations, reduces data processing costs by up to 20%, prevents job failures from disk capacity constraints, and enables elastic scaling by decoupling storage from compute.

Modernize Apache Spark workflows using Spark Connect on Amazon EMR on Amazon EC2
In this post, we demonstrate how to implement Apache Spark Connect on Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2) to build decoupled data processing applications. We show how to set up and configure Spark Connect securely, so you can develop and test Spark applications locally while executing them on remote Amazon EMR clusters.

Introducing the Apache Spark troubleshooting agent for Amazon EMR and AWS Glue
In this post, we show you how the Apache Spark troubleshooting agent helps analyze Apache Spark issues by providing detailed root causes and actionable recommendations. You’ll learn how to streamline your troubleshooting workflow by integrating this agent with your existing monitoring solutions across Amazon EMR and AWS Glue.

Introducing Apache Spark upgrade agent for Amazon EMR
In this post, you learn how to assess your existing Amazon EMR Spark applications, use the Spark upgrade agent directly from the Kiro IDE, upgrade a sample e-commerce order analytics Spark application project (including build configs, source code, tests, and data quality validation), and review code changes before rolling them out through your CI/CD pipeline.

Accelerate Apache Hive read and write on Amazon EMR using enhanced S3A
In this post, we demonstrate how Apache Hive on Amazon EMR 7.10 delivers significant performance improvements for both read and write operations on Amazon S3.

Amazon EMR HBase on Amazon S3 transitioning to EMR S3A with comparable EMRFS performance
Starting with version 7.10, Amazon EMR is transitioning from EMR File System (EMRFS) to EMR S3A as the default file system connector for Amazon S3 access. This transition brings HBase on Amazon S3 to a new level, offering performance parity with EMRFS while delivering substantial improvements, including better standardization, improved portability, stronger community support, improved performance through non-blocking I/O, asynchronous clients, and better credential management with AWS SDK V2 integration. In this post, we discuss this transition and its benefits.