AWS Big Data Blog
Category: Artificial Intelligence

Introducing the Apache Spark troubleshooting agent for Amazon EMR and AWS Glue
In this post, we show you how the Apache Spark troubleshooting agent helps analyze Apache Spark issues by providing detailed root causes and actionable recommendations. You’ll learn how to streamline your troubleshooting workflow by integrating this agent with your existing monitoring solutions across Amazon EMR and AWS Glue.

Introducing Apache Spark upgrade agent for Amazon EMR
In this post, you learn how to assess your existing Amazon EMR Spark applications, use the Spark upgrade agent directly from the Kiro IDE, upgrade a sample e-commerce order analytics Spark application project (including build configs, source code, tests, and data quality validation), and review code changes before rolling them out through your CI/CD pipeline.

Build billion-scale vector databases in under an hour with GPU acceleration on Amazon OpenSearch Service
AWS recently announced the general availability of GPU-accelerated vector (k-NN) indexing on Amazon OpenSearch Service. You can now build billion-scale vector databases in under an hour and index vectors up to 10 times faster at a quarter of the cost. This feature dynamically attaches serverless GPUs to boost domains and collections running CPU-based instances. With […]

Introducing catalog federation for Apache Iceberg tables in the AWS Glue Data Catalog
AWS Glue now supports catalog federation for remote Iceberg tables in the Data Catalog. With catalog federation, you can query remote Iceberg tables, stored in Amazon S3 and cataloged in remote Iceberg catalogs, using AWS analytics engines and without moving or duplicating tables. In this post, we discuss how to get started with catalog federation for Iceberg tables in the Data Catalog.

Accelerate data lake operations with Apache Iceberg V3 deletion vectors and row lineage
In this post, we walk you through the new capabilities in Iceberg V3, explain how deletion vectors and row lineage address these challenges, explore real-world use cases across industries, and provide practical guidance on implementing Iceberg V3 features across AWS analytics, catalog, and storage services.

Cross-account lakehouse governance with Amazon S3 Tables and SageMaker Catalog
In this post, we walk you through a practical solution for secure, efficient cross-account data sharing and analysis. You’ll learn how to set up cross-account access to S3 Tables using federated catalogs in Amazon SageMaker, perform unified queries across accounts with Amazon Athena in Amazon SageMaker Unified Studio, and implement fine-grained access controls at the column level using AWS Lake Formation.

Optimize efficiency with language analyzers using scalable multilingual search in Amazon OpenSearch Service
Organizations manage content across multiple languages as they expand globally. Ecommerce platforms, customer support systems, and knowledge bases require efficient multilingual search capabilities to serve diverse user bases effectively. This unified search approach helps multinational organizations maintain centralized content repositories while making sure users, regardless of their preferred language, can effectively find and access relevant […]

Accelerate your data and AI workflows by connecting to Amazon SageMaker Unified Studio from Visual Studio Code
In this post, we demonstrate how to connect your local VS Code to SageMaker Unified Studio so you can build complete end-to-end data and AI workflows while working in your preferred development environment.
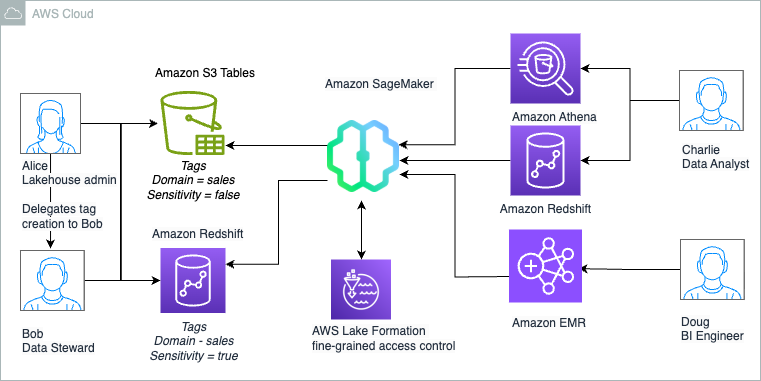
The Amazon SageMaker Lakehouse Architecture now supports Tag-Based Access Control for federated catalogs
We are now announcing support for Lake Formation tag-based access control (LF-TBAC) to federated catalogs of S3 Tables, Redshift data warehouses, and federated data sources such as Amazon DynamoDB, MySQL, PostgreSQL, SQL Server, Oracle, Amazon DocumentDB, Google BigQuery, and Snowflake. In this post, we illustrate how to manage S3 Tables and Redshift tables in the lakehouse using a single fine-grained access control mechanism of LF-TBAC. We also show how to access these lakehouse tables using your choice of analytics services, such as Athena, Redshift, and Apache Spark in Amazon EMR Serverless.

Amazon SageMaker Catalog expands discoverability and governance for Amazon S3 general purpose buckets
In July 2025, Amazon SageMaker announced support for Amazon Simple Storage Service (Amazon S3) general purpose buckets and prefixes in Amazon SageMaker Catalog that delivers fine-grained access control and permissions through S3 Access Grants. In this post, we explore how this integration addresses key challenges our customers have shared with us, and how data producers, such as administrators and data engineers, can seamlessly share and govern S3 buckets and prefixes using S3 Access Grants, while making it readily discoverable for data consumers.