AWS Big Data Blog
Category: Foundational (100)

How Amazon Devices scaled and optimized real-time demand and supply forecasts using serverless analytics
Every day, Amazon devices process and analyze billions of transactions from global shipping, inventory, capacity, supply, sales, marketing, producers, and customer service teams. This data is used in procuring devices’ inventory to meet Amazon customers’ demands. With data volumes exhibiting a double-digit percentage growth rate year on year and the COVID pandemic disrupting global logistics […]

Amazon EMR launches support for Amazon EC2 C7g (Graviton3) instances to improve cost performance for Spark workloads by 7–13%
Amazon EMR provides a managed service to easily run analytics applications using open-source frameworks such as Apache Spark, Hive, Presto, Trino, HBase, and Flink. The Amazon EMR runtime for Spark and Presto includes optimizations that provide over twice the performance improvements compared to open-source Apache Spark and Presto. With Amazon EMR release 6.7, you can […]

AWS Lake Formation 2022 year in review
Data governance is the collection of policies, processes, and systems that organizations use to ensure the quality and appropriate handling of their data throughout its lifecycle for the purpose of generating business value. Data governance is increasingly top-of-mind for customers as they recognize data as one of their most important assets. Effective data governance enables […]

Amazon EMR launches support for Amazon EC2 C6i, M6i, I4i, R6i and R6id instances to improve cost performance for Spark workloads by 6–33%
Amazon EMR provides a managed service to easily run analytics applications using open-source frameworks such as Apache Spark, Hive, Presto, Trino, HBase, and Flink. The Amazon EMR runtime for Spark and Presto includes optimizations that provide over two times performance improvements over open-source Apache Spark and Presto, so that your applications run faster and at […]

Lower your Amazon OpenSearch Service storage cost with gp3 Amazon EBS volumes
Amazon OpenSearch Service makes it easy for you to perform interactive log analytics, real-time application monitoring, website search, and more. OpenSearch is an open-source, distributed search and analytics suite comprising OpenSearch, a distributed search and analytics engine, and OpenSearch Dashboards, a UI and visualization tool. When you use Amazon OpenSearch Service, you configure a set […]

How Etleap and Amazon Redshift Serverless optimize costs for ETL
Amazon Redshift Serverless lets you avoid managing infrastructure while only paying for what you use. Etleap provides data integration software that is natively built on AWS. It’s an AWS Advanced Technology Partner with the AWS Data & Analytics Competency and Amazon Redshift Service Ready designation. In this post, we share how you can minimize the […]

Reduce cost and improve query performance with Amazon Athena Query Result Reuse
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run on datasets at petabyte scale. You can use Athena to query […]

How The Mill Adventure enabled data-driven decision-making in iGaming using Amazon QuickSight
This post is co-written with Darren Demicoli from The Mill Adventure. The Mill Adventure is an iGaming industry enabler offering customizable turnkey solutions to B2B partners and custom branding enablement for its B2C partners. They provide a complete gaming platform, including licenses and operations, for rapid deployment and success in iGaming, and are committed to […]

Upgrade to Athena engine version 3 to increase query performance and access more analytics features
Customers tell us they want to have stronger performance and lower costs for their data analytics applications and workloads. Customers also want to use AWS as a platform that hosts managed versions of their favorite open-source projects, which will frequently adopt the latest features from the open-source communities. With Amazon Athena engine version 3, we […]
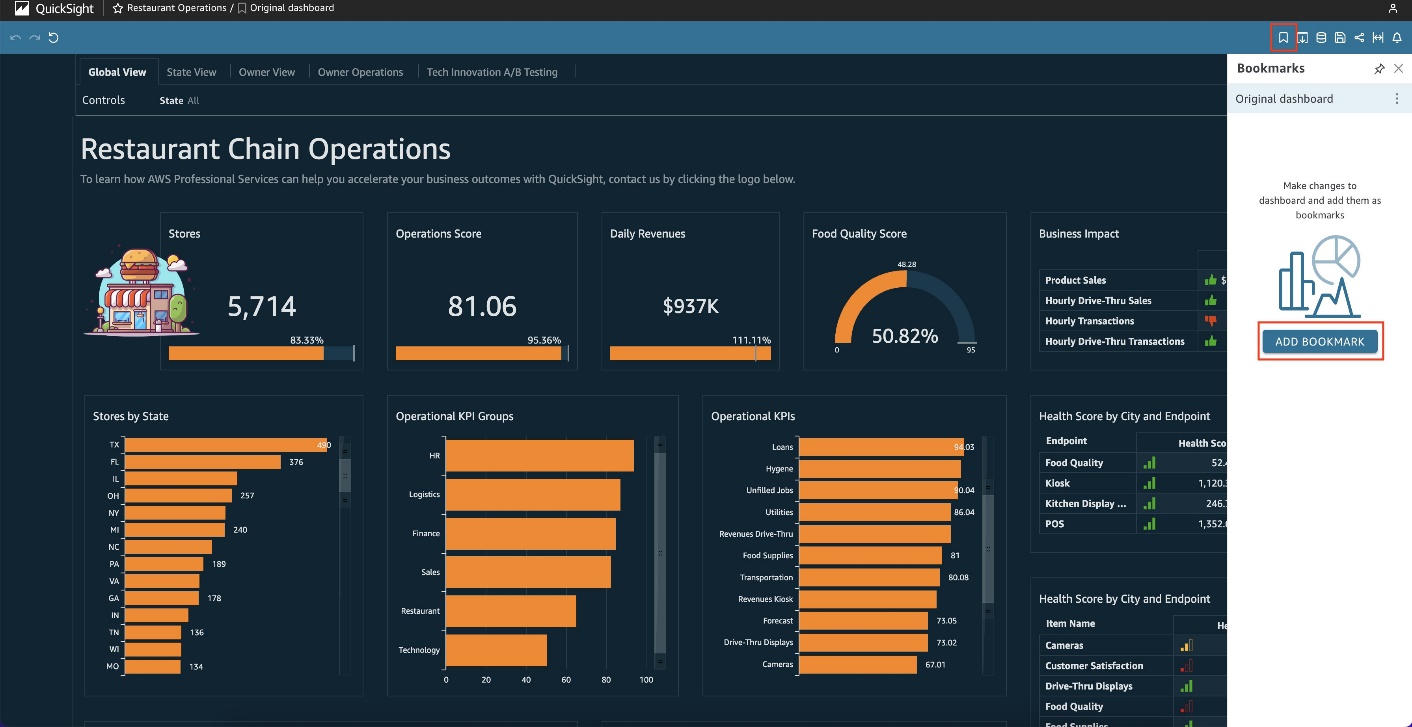
Customize Amazon QuickSight dashboards with the new bookmarks functionality
Amazon QuickSight users now can add bookmarks in dashboards to save customized dashboard preferences into a list of bookmarks for easy one-click access to specific views of the dashboard without having to manually make multiple filter and parameter changes every time. Combined with the “Share this view” functionality, you can also now share your bookmark […]