AWS Big Data Blog
How Fresenius Medical Care aims to save dialysis patient lives using real-time predictive analytics on AWS
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
This post is co-written by Kanti Singh, Director of Data & Analytics at Fresenius Medical Care.
Fresenius Medical Care is the world’s leading provider of kidney care products and services, and operates more than 2,600 dialysis centers in the US alone. The company provides comprehensive solutions for people living with chronic kidney disease and related conditions, with a mission to improve the quality of life of every patient, every day, by transforming healthcare through research, innovation, and compassion. Data analysis that leads to timely interventions is critical to this mission, and essential to reduce hospitalizations and prevent adverse events.
In this post, we walk you through the solution architecture, performance considerations, and how a research partnership with AWS around medical complexity led to an automated solution that helped deliver alerts for potential adverse events.
Why Fresenius Medical Care chose AWS
The Fresenius Medical Care technical team chose AWS as their preferred cloud platform for two key reasons.
First, we determined that AWS IoT Core was more mature than other solutions and would likely face fewer issues with deployment and certificates. As an organization, we wanted to go with a cloud platform that had a proven track record and established technical solutions and services in the IoT and data analytics space. This included Amazon Athena, which is an easy-to-use serverless service that you can use to run queries on data stored in Amazon Simple Storage Service (Amazon S3) for analysis.
Another factor that played a major role in our decision was the fact that AWS offered the largest set of serverless services for analytics than any other cloud provider. We ultimately determined that AWS innovations met the company’s current needs as well as positioned the company for the future as we worked to expand our predictive capabilities.
Solution overview
We needed to develop a near-real-time analytics solution that would collect dynamic dialysis machine data every 10 seconds during hemodialysis treatment in near-real time and personalize it to predict every 30 minutes if a patient is at a health risk for intradialytic hypotension (IDH) within the next 15–75 minutes. This solution needed to scale to all our dialysis centers nationwide, with each location sending 10 MBps of treatment data at peak times.
The complexities that needed to be managed in the solution included handling high throughput data, a low-latency time-sensitive solution of 10 seconds from data origination to reporting and notification, a highly available solution, and a cost-effective solution with on-demand scaling up or down based on data volume.
Fresenius Medical Care partnered with AWS on this mission and developed an architecture that met our technical and business requirements. Core components in the architecture included Amazon Kinesis Data Streams, Amazon Kinesis Data Analytics, and Amazon SageMaker. We chose Kinesis Data Streams and Kinesis Data Analytics primarily because they’re serverless and highly available (99.9%), offer very high throughput, and are easy to scale. We chose SageMaker due to its unique capability that allows ease of building, training, and running machine learning (ML) models at scale.
The following diagram illustrates the architecture.
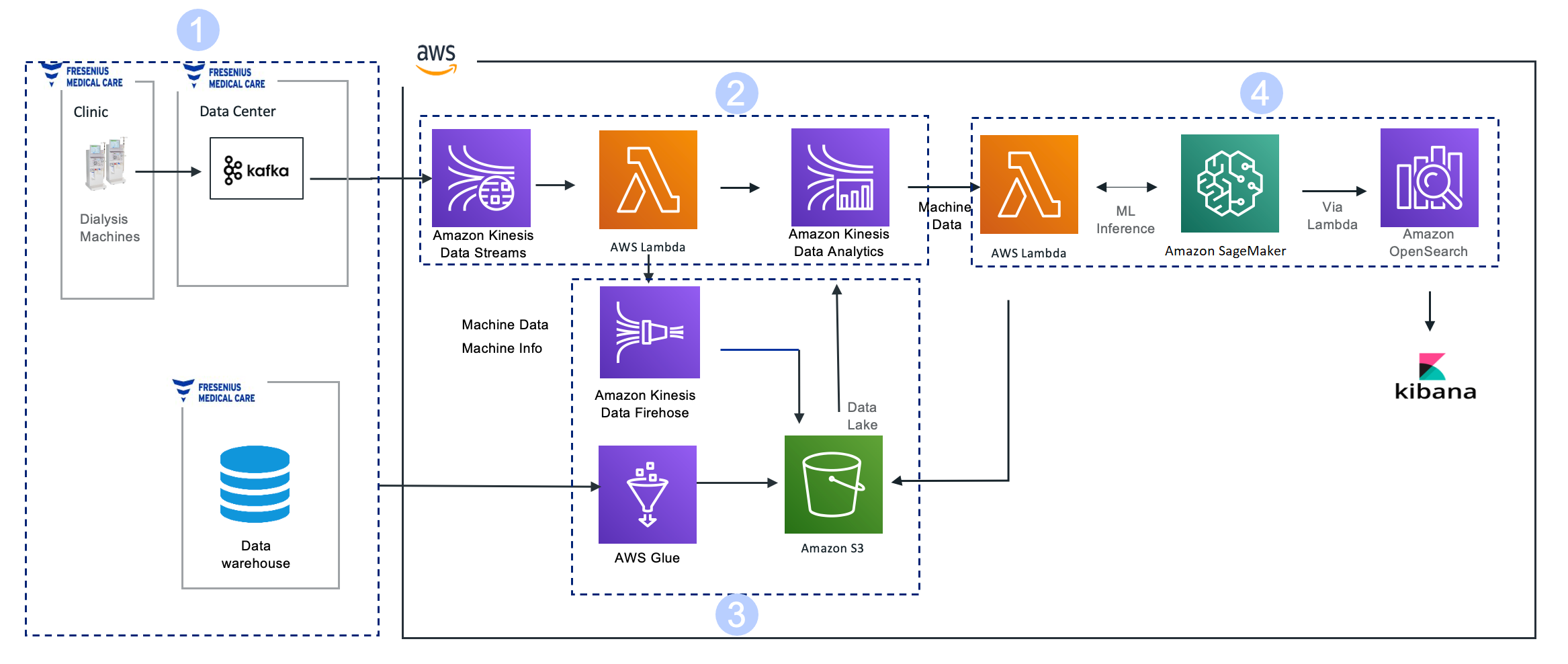
The solution consists of the following key components:
- Data collection
- Data ingestion and aggregation
- Data lake storage
- ML Inference and operational analytics
Let’s discuss each stage in the workflow in more detail.
Data collection
Dialysis machines located in Fresenius Medical Care centers help patients in the treatment of end-stage renal disease by performing hemodialysis. The dialysis machines provide immediate access to all treatment and clinical trending data across the fleet of hemodialysis machines in all centers in the US.
These machines transmit a data payload every 10 seconds to Kafka brokers located in Fresenius Medical Care’s on-premises data center for use by several applications.
Data ingestion and aggregation
We use a Kinesis-Kafka connector hosted on self-managed Amazon Elastic Compute Cloud (Amazon EC2) instances to ingest data from a Kafka topic in near-real time into Kinesis Data Streams.
We use AWS Lambda to read the data points and filter the datasets accordingly to Kinesis Data Analytics. Upon reaching the batch size threshold, Lambda sends the data to Kinesis Data Analytics for instream analytics.
We chose Kinesis Data Analytics due to the ease-of-use it provides for SQL-based stream analytics. By using SQL with KDA (KDA Studio/Flink SQL), we can create dynamic features based on machine interval data arriving in real time. This data is joined with the patient demographic, historical clinical, treatment, and laboratory data (enriched with Amazon S3 data) to create the complete set of features required for a downstream ML model.
Data lake storage
Amazon Kinesis Data Firehose was the simplest way to consistently load streaming data to build a raw data lake in Amazon S3. Kinesis Data Firehose micro-batches data into 128 MB file sizes and delivers streaming data to Amazon S3.
Clinical datasets are required to enrich stream data sourced from on-premises data warehouses via AWS Glue Spark jobs on a nightly basis. The AWS Glue jobs extract patient demographic, historical clinical, treatment, and laboratory data from the data warehouse to Amazon S3 and transform machine data from JSON to Parquet format for better storage and retrieval costs in Amazon S3. AWS Glue also helps build the static features for the intradialytic hypotension (IDH) ML model, which are required for downstream ML inference.
ML Inference and Operational analytics
Lambda batches the stream data from Kinesis Data Analytics that has all the features required for IDH ML model inference.
SageMaker, a fully managed service, trains and deploys the IDH predictive model. The deployed ML model provides a SageMaker endpoint that is used by Lambda for ML inference.
Amazon OpenSearch Service helps store the IDH inference results it received from Lambda. The results are then used for visualization through Kibana, which displays a personalized health prediction dashboard visual for each patient undergoing treatment and is available in near-real time for the care team to provide intervention proactively.
Observability and traceability for failures
Because this solution offers the potential for life-saving interventions, it’s considered business critical. The following key measures are taken to proactively monitor the AWS jobs in Fresenius Medical Care’s VPC account:
- For AWS Glue jobs that have failures and errors in Lambda functions, an immediate email and Amazon CloudWatch alert is sent to the Data Ops team for resolution.
- CloudWatch alarms are also generated for Amazon OpenSearch Service whenever there are blocks on writes or the cluster is overloaded with shard capacity, CPU utilization, or other issues, as recommended by AWS.
- Kinesis Data Analytics and Kinesis Data Streams generate data quality alerts on data rejections or empty results.
- Data quality alerts are also generated whenever data quality rules on data points are mismatched. To check mismatched data, we use quality rule comparison and sanity checks between message payloads in the stream with data loaded in the data lake.
These systematic and automated monitoring and alerting mechanisms help our team stay one step ahead to ensure that systems are running smoothly and successfully, and any unforeseen problems can be resolved as quickly as possible before it causes any adverse impact on users of the system.
AWS partnership
After Fresenius Medical Care took advantage of the AWS Data Lab to create a working prototype within one week, expert Solutions Architects from AWS became trusted advisors, helping our team with prescriptive guidance from ideation to production. The AWS team helped with both solution-based and service-specific best practices, helped resolve key blockers in every phase from development through production, and performed architecture reviews to ensure the solution was robust and resilient to business needs.
Solution results
This solution allows Fresenius Medical Care to better personalize care to patients undergoing dialysis treatment with a proactive intervention by clinicians at the point of care that has the potential to save patient lives. The following are some of the key benefits due to this solution:
- Cloud computing resources enable the development, analysis, and integration of real-time predictive IDH that can be easily and seamlessly scaled as needed to reach additional clinics.
- The use of our tool may be particularly useful in institutions facing staff shortages and, possibly, during home dialysis. Additionally, it may provide insights on strategies to prevent and manage IDH.
- The solution enables modern and innovative solutions that improve patient care by providing world-class research and data-driven insights.
This solution has been proven to scale to an acceptable performance level of 6,000 messages per second, translating to 19 MB/sec with 60,000/sec concurrent Lambda invocations. The ability to adapt by scaling up and down every component in the architecture with ease kept costs very low, which wouldn’t have been possible elsewhere.
Conclusion
Successful implementation of this solution led to a think big approach in modernizing several legacy data assets and has set Fresenius Medical Care on the path of building an enterprise unified data analytics platform on AWS using Amazon S3, AWS Glue, Amazon EMR, and AWS Lake Formation. The unified data analytics platform offers robust data security and data sharing for multi-tenants in various geographies across the US. Similar to Fresenius, you can accelerate time to market by using the right tool for the job, using the broad and deep variety of AWS analytic native services.
About the authors
 Kanti Singh is a Director of Data & Analytics at Fresenius Medical Care, leading the big data platform, architecture, and the engineering team. She loves to explore new technologies and how to leverage them to solve complex business problems. In her free time, she loves traveling, dancing, and spending time with family.
Kanti Singh is a Director of Data & Analytics at Fresenius Medical Care, leading the big data platform, architecture, and the engineering team. She loves to explore new technologies and how to leverage them to solve complex business problems. In her free time, she loves traveling, dancing, and spending time with family.
 Harsha Tadiparthi is a Specialist Principal Solutions Architect specialized in analytics at Amazon Web Services. He enjoys solving complex customer problems in databases and analytics, and delivering successful outcomes. Outside of work, he loves to spend time with his family, watch movies, and travel whenever possible.
Harsha Tadiparthi is a Specialist Principal Solutions Architect specialized in analytics at Amazon Web Services. He enjoys solving complex customer problems in databases and analytics, and delivering successful outcomes. Outside of work, he loves to spend time with his family, watch movies, and travel whenever possible.