AWS Big Data Blog
Reduce cost and improve query performance with Amazon Athena Query Result Reuse
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run on datasets at petabyte scale. You can use Athena to query your S3 data lake for use cases such as data exploration for machine learning (ML) and AI, business intelligence (BI) reporting, and ad hoc querying.
It’s not uncommon for datasets in data lakes to update only daily, or at most a few times per day, yet queries running on these datasets may be repeated more frequently. Previously, all queries resulted in a data scan, even if the same query was repeated again. When the source data hasn’t changed, repeat queries run needlessly, leading to the same results with higher data scan costs and query latency. Wouldn’t it be better if the results of a recent query could be reused instead?
Query Result Reuse is a new feature available in Athena engine version 3 that makes it possible to reuse the results of a previous query. This can improve performance and reduce cost for frequently run queries, by skipping scanning the source data and instead returning a previously calculated result directly. With Query Result Reuse, you can tell Athena that you want to reuse results of a previous query run, with a maximum age setting that controls how recent a previous result has to be.
Athena automatically reuses any previous results that match your query and maximum age setting, or transparently runs the query again if no match is found. If you know that a dataset changes a few times per day, you can, for example, tell Athena to reuse results that are up to an hour old to avoid rerunning most queries, but still get new results when you run a query soon after new data has become available.
In this post, we demonstrate how to reduce cost and improve query performance with the new Query Result Reuse feature.
When should you use Query Result Reuse?
We recommend using Query Result Reuse for every query where the source data doesn’t change frequently. You can configure the maximum age of results to reuse per query, or use the default, which is 60 minutes. In certain cases where queries include non-deterministic functions such as RAND(), the query fetches fresh data from the input source even if the Query Result Reuse feature is enabled.
Query Result Reuse allows results to be shared among users in a workgroup, as long as they have access to the tables and data. This means Query Result Reuse can benefit not only a single user, but also other users in the workgroup who might be running the same queries. One example where this may be especially beneficial is when you have dashboards that are viewed by many users. The dashboard widgets run the same queries for all users, and are therefore accelerated by Query Result Reuse, when enabled.
Another example is if you have a dataset that is updated daily, and many users who all query the most recent data to create reports. Different people might run the same queries as part of their work; with Query Result Reuse, they can collectively avoid running the same query more than once, making everyone more productive and lowering overall cost by avoiding repeated scans of the same data.
Finally, if you have a historical dataset that is frequently queried, but never or very rarely updated, you can configure queries to reuse results that are up to 7 days old to maximize the chances of reusing results and avoid unnecessary costs.
How does Query Result Reuse work?
Query Result Reuse takes advantage of the fact that Athena writes query results to Amazon S3 as a CSV file. Before the introduction of Query Result Reuse, it was possible to reuse query results by reading these files directly. You could also use the ClientRequestToken parameter of the StartQueryExecution API to ensure queries are run only once, and subsequent runs return the same results. With Query Result Reuse, the process of reusing query results is easier and more versatile.
When Athena receives a query with Query Result Reuse enabled, it looks for a result for a query with the same query string that was run in the same workgroup. The query string has to be identical in order to match.
Query Result Reuse is enabled on a per query basis. When you run a query, you specify how old a result can be for it to be reused, from 1 minute up to 7 days. If the query has been run before, and a result exists that matches the request, it’s returned, otherwise the query is run and a new result is calculated. This new result is then available to be reused by subsequent queries.
You can run the query multiple times with different settings for how old a result you can accept. Results can be reused within the same workgroup, even if a different user ran the query previously.
Before a query result is reused, Athena does a few checks to make sure that the user is still allowed to see the results. It checks that the user has access to the tables involved in the query and permission to read the result file on Amazon S3.
There are some situations where query results can’t be reused, for example if the query uses non-deterministic functions, or has AWS Lake Form ation fine-grained access controls enabled. These limitations are described in more detail later in this post.
Run queries with Query Result Reuse
In this section, we demonstrate how to run queries with the Query Result Reuse feature via the Athena API, the Athena console, and the JDBC and ODBC drivers.
Run queries using the Athena API
For applications that use the Athena API through the AWS Command Line Interface (AWS CLI) or the AWS SDKs, the StartQueryExecution API call now has the additional parameter ResultReuseConfiguration, where you can enable Query Result Reuse and specify the maximum age of results. For example, when using the AWS CLI, you can run a query with Query Result Reuse enabled as follows:
The following code shows how to do this with the AWS SDK for Python:
These examples assume that my_work_group uses Athena engine v3, that the workgroup has an output location configured, and that the AWS Region has been set in the AWS CLI configuration.
When a query result is reused, you can see in the statistics section of the response from the GetQueryExecution API call that no data was scanned and that results were reused:
Run queries using the Athena console
When you run queries on the Athena console, Query Result Reuse is now enabled by default. You can enable and disable Query Result Reuse in the query editor. You can also choose the pen icon to change the maximum age of results. This setting applies to all queries run on the Athena console.
The following screenshot shows an example query run against AWS CloudTrail logs with Query Result Reuse enabled.
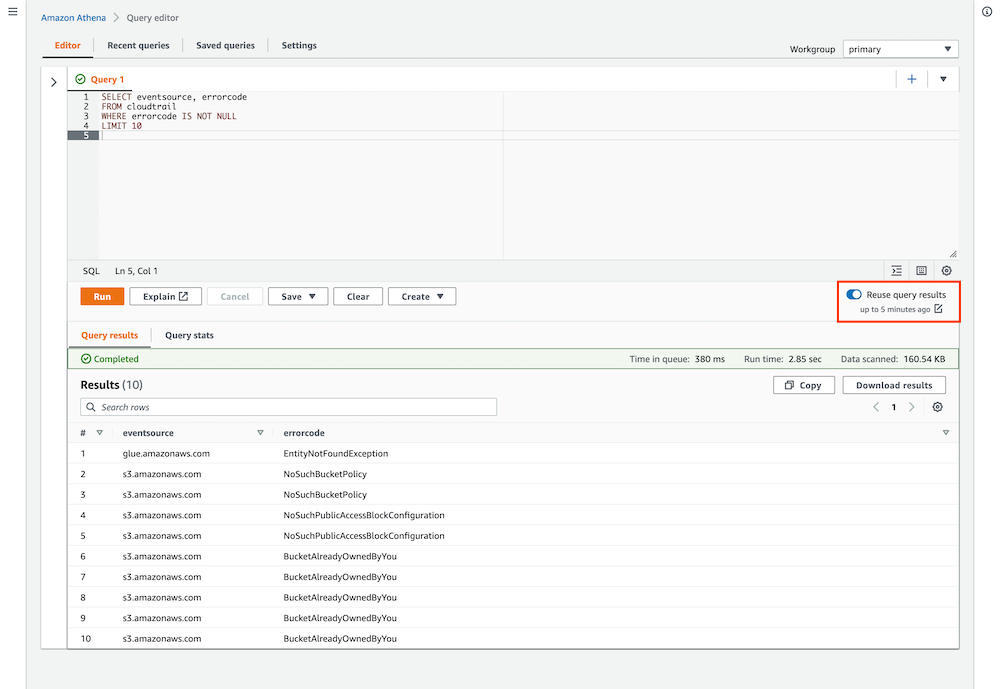
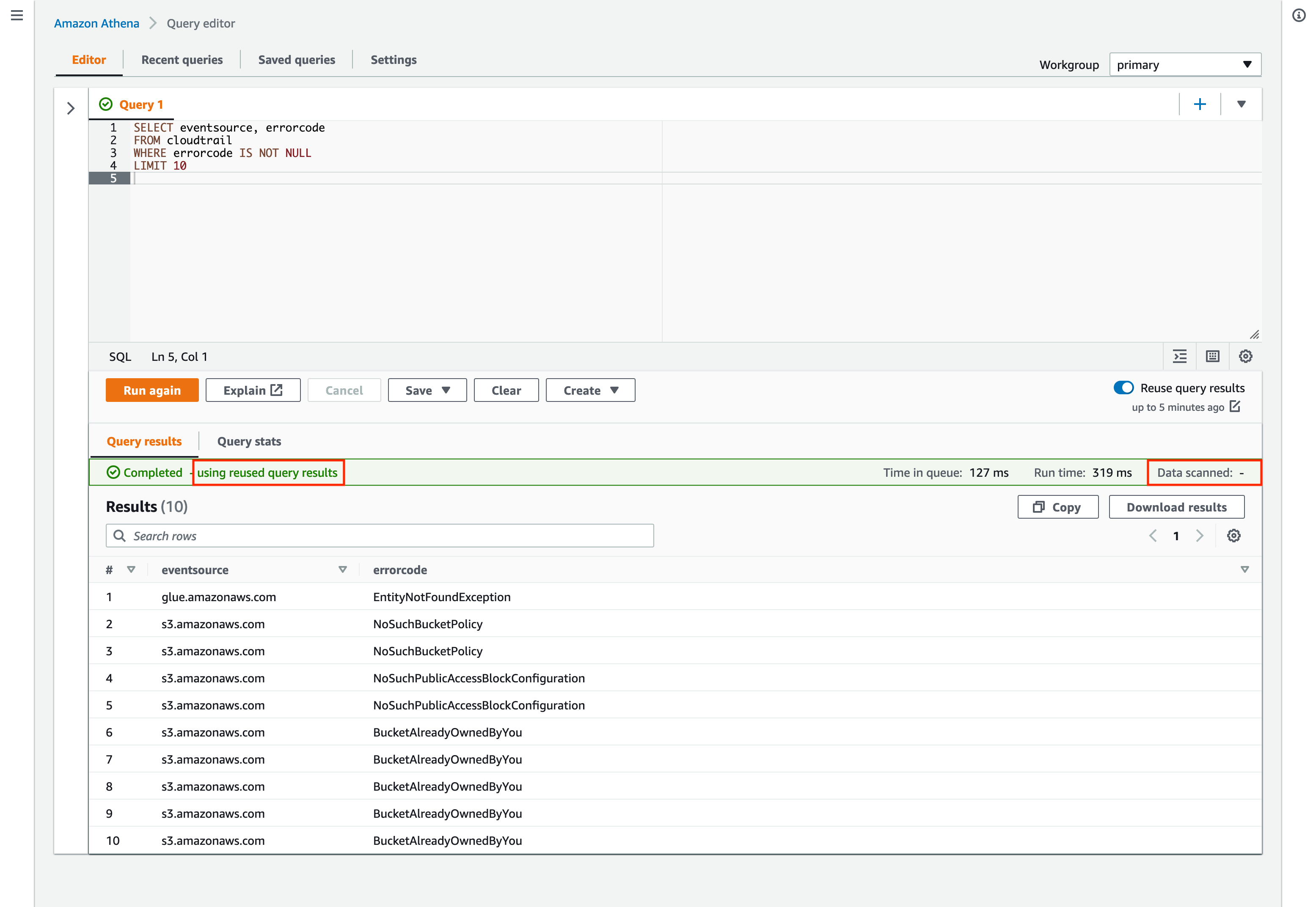
When we ran the query again, the results showed up immediately, and we could see the message “using reused query results” in the Query results pane as a confirmation that the results of our first query had been reused. The Data scanned statistic also showed “-” to indicate that no data was scanned.
Limitations and considerations
Query Result Reuse is supported for most Athena queries, but there are some limitations. We want to ensure that reusing results doesn’t create surprising situations, or expose results that a user shouldn’t have access to. For that reason, Athena always runs a fresh query in the following situations:
- Non-deterministic functions – Some functions and expressions produce different results from query to query, such as
CURRENT_TIMEandRAND(). Results for queries that use temporal and non-deterministic expressions and functions aren’t reusable because that could create surprising and inconsistent results. - Fine-grained access controls – Row-level and column-level permissions are configured in Lake Formation, and Athena can’t know if these have changed since a previous query result was created. Users using the same workgroup can also have different permissions, and checking all permissions would undo many of the cost and performance savings you get from Query Result Reuse.
- Federated queries, user-defined functions (UDFs), and external Hive metastores – Users using the same workgroup can have different permissions to invoke the AWS Lambda functions that these features rely on. Athena isn’t able to check that a user that wants to reuse a result has permission to invoke these Lambda functions without running the query, which would negate the cost and performance savings.
Athena detects these conditions automatically and runs the query as if Query Result Reuse wasn’t enabled. You won’t get errors, but you can determine that Query Result Reuse wasn’t in effect by inspecting the query status (see our earlier examples).
Query Result Reuse is available in Athena engine version 3 only.
Conclusion
Query Result Reuse is a new feature in Athena that aims to reduce cost and query response times for datasets that change less frequently than they are queried. For teams that often run the same query, or have dashboards that are used more often than the data changes, Query Result Reuse can result in lower costs and faster results. It’s easy to get started with Query Result Reuse via the Athena console, API, and JDBC/ODBC; all you have to do is set the maximum age of results, and run your queries as usual.
We hope that you will like this new feature, and that it will save cost and improve performance for you and your team!
About the authors
 Theo Tolv is a Senior Big Data Architect in the Athena team. He’s worked with small and big data for most of his career and often hangs out on Stack Overflow answering questions about Athena.
Theo Tolv is a Senior Big Data Architect in the Athena team. He’s worked with small and big data for most of his career and often hangs out on Stack Overflow answering questions about Athena.
 Vijay Jain is a Senior Product Manager in Amazon Web Services (AWS) Athena team. He is passionate about building scalable analytics technologies and products working closely with enterprise customers. Outside of work, Vijay likes running and spending time with his family.
Vijay Jain is a Senior Product Manager in Amazon Web Services (AWS) Athena team. He is passionate about building scalable analytics technologies and products working closely with enterprise customers. Outside of work, Vijay likes running and spending time with his family.