AWS Big Data Blog
Category: Serverless

Integrate AWS Glue Schema Registry with the AWS Glue Data Catalog to enable effective schema enforcement in streaming analytics use cases
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Metadata is an integral part of data management and governance. The AWS Glue Data Catalog can provide a uniform repository to store and share metadata. The main […]

Synchronize your AWS Glue Studio Visual Jobs to different environments
June 2023: This post was reviewed and updated for accuracy. AWS Glue has become a popular option for integrating data from disparate data sources due to its ability to integrate large volumes of data using distributed data processing frameworks. Many customers use AWS Glue to build data lakes and data warehouses. Data engineers who prefer […]

Orchestrate big data jobs on on-premises clusters with AWS Step Functions
Customers with specific needs to run big data compute jobs on an on-premises infrastructure often require a scalable orchestration solution. For large-scale distributed compute clusters, the orchestration of jobs must be scalable to maximize their utilization, while at the same time remain resilient to any failures to prevent blocking the ever-growing influx of data and […]

Author AWS Glue jobs with PyCharm using AWS Glue interactive sessions
Data lakes, business intelligence, operational analytics, and data warehousing share a common core characteristic—the ability to extract, transform, and load (ETL) data for analytics. Since its launch in 2017, AWS Glue has provided serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. AWS […]
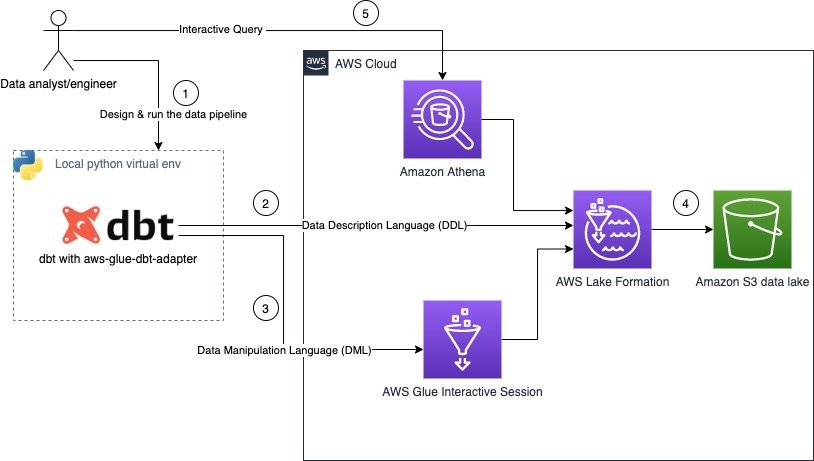
Build your data pipeline in your AWS modern data platform using AWS Lake Formation, AWS Glue, and dbt Core
dbt has established itself as one of the most popular tools in the modern data stack, and is aiming to bring analytics engineering to everyone. The dbt tool makes it easy to develop and implement complex data processing pipelines, with mostly SQL, and it provides developers with a simple interface to create, test, document, evolve, […]

Introducing AWS Glue Auto Scaling: Automatically resize serverless computing resources for lower cost with optimized Apache Spark
October 2024: This post has been updated along with Interactive Sessions support for AWS Glue Auto scaling. June 2023: This post was reviewed and updated for accuracy. Data created in the cloud is growing fast in recent days, so scalability is a key factor in distributed data processing. Many customers benefit from the scalability of […]

Enhance analytics with Google Trends data using AWS Glue, Amazon Athena, and Amazon QuickSight
In today’s market, business success often lies in the ability to glean accurate insights and predictions from data. However, data scientists and analysts often find that the data they have at their disposal isn’t enough to help them make accurate predictions for their use cases. A variety of factors might alter an outcome and should […]

Develop and test AWS Glue version 3.0 and 4.0 jobs locally using a Docker container
Mar 2025: This post was written for AWS Glue 3.0 and 4.0. For AWS Glue 5.0, visit Develop and test AWS Glue 5.0 jobs locally using a Docker container. Apr 2023: This post was reviewed and updated with enhanced support for Glue 4.0 Streaming jobs. Jan 2023: This post was reviewed and updated with enhanced […]

Best practices to optimize data access performance from Amazon EMR and AWS Glue to Amazon S3
June 2024: This post was reviewed for accuracy and updated to cover Apache Iceberg. June 2023: This post was reviewed and updated for accuracy. Customers are increasingly building data lakes to store data at massive scale in the cloud. It’s common to use distributed computing engines, cloud-native databases, and data warehouses when you want to […]

Introducing Protocol buffers (protobuf) schema support in AWS Glue Schema Registry
September 2025: This post was reviewed for accuracy. AWS Glue Schema Registry now supports Protocol buffers (protobuf) schemas in addition to JSON and Avro schemas. This allows application teams to use protobuf schemas to govern the evolution of streaming data and centrally control data quality from data streams to data lake. AWS Glue Schema Registry […]