AWS Big Data Blog
Orchestrate big data jobs on on-premises clusters with AWS Step Functions
Customers with specific needs to run big data compute jobs on an on-premises infrastructure often require a scalable orchestration solution. For large-scale distributed compute clusters, the orchestration of jobs must be scalable to maximize their utilization, while at the same time remain resilient to any failures to prevent blocking the ever-growing influx of data and jobs. Moreover, on-premises compute resources can’t be extended on demand, therefore, the jobs may be competing for the same resources with different priorities.
This post showcases serverless building blocks for orchestrating big data jobs using AWS Step Functions, AWS Lambda, and Amazon DynamoDB with a focus on reliability, maintainability, and monitoring. In this solution, Step Functions enables thousands of workflows to run parallel. Additionally, Lambda provides flexibility implementing arbitrary interfaces to the on-premises infrastructure and its compute resources. With additional steps in the orchestration, the solution also allows operations to monitor thousands of parallel jobs in a visual interface for better debugging.
Architecture
The proposed serverless solution consists of the following main components:
- Job trigger – Requests new compute jobs to run on the on-premises cluster. For simplicity, in this architecture we assume that the trigger is a client calling Step Functions directly. However, you could extend this to include Amazon API Gateway to create a job API to interface with the orchestration solution or a rule engine to trigger jobs when relevant data becomes available.
- Job manager – This Step Functions workflow runs once per compute job, with multiple workflows running in parallel. It tracks the status of a job from queueing, scheduling, running, retrying, all the way to its completion. Ideally, a job can be scheduled immediately, but workflows can run for days if a job is very low priority and compute resources are sparse. The job manager delegates the decision when or where to run the job to the job queue manager. Communication to the on-premises cluster is abstracted through a Lambda adapter.
- Job queue manager – Maintains a queue of all jobs. With the given job properties (for example based on priority), the job queue manager decides the running time of jobs, and the cluster on which they run. To illustrate the concept, the architecture considers real-time information on the resource utilization of the compute clusters (memory, CPU) for scheduling. However, you could apply different scheduling algorithms as required given the flexibility of Lambda.
- On-premises compute cluster – Provides the computing resources, data nodes, and tools to run compute jobs.
The following diagram illustrates the solution architecture.

The main process of the solution consists of seven steps:
- The job trigger runs a new Step Functions workflow to run a compute job on premises and provides the necessary information (such as priority and required resources).
- The job manager creates a new record in DynamoDB to add the job to the queue of the job queue manager, and the workflow waits for the job queue manager to call back.
- Amazon EventBridge triggers a scheduled Lambda function in the job queue manager periodically (for example, every 5 minutes), decoupled from the job requests.
- The job scheduler Lambda function retrieves real-time information from cluster metrics to see whether jobs can be scheduled at this point in time.
- The job scheduler function fetches all queued jobs from DynamoDB and tries to schedule as many of those jobs as possible to available compute resources based on priority, as well as memory and CPU demands.
- For each job that can be scheduled to the compute cluster, the job scheduler function communicates back to the job manager to signal the workflow to continue and that the job can be run.
- The job manager communicates with the on-premises cluster through the compute cluster adapter Lambda function to run the job, track its status periodically, and retry in case of errors.
On-premises compute cluster
In this post, we assume the on-premises compute cluster offers interfaces to interact with the compute resources. For example, customers could run a Spark compute cluster on premises that allows the following basic interactions through an API:
- Upload and trigger a compute job on a cluster (for example, upload a Spark JAR file and submit)
- Get the status of a compute job (such as running, stopped, or error)
- Get error output in case of failures in the compute job (for example, the job failed due to access denied)
In addition, we assume the cluster can provide metrics on its current utilization. For example, the cluster could provide Prometheus metrics as aggregates over all resources within a compute cluster:
- Memory utilization (for example, 2 TB with 80% utilization)
- CPU utilization (for example, 5,000 cores with 50% utilization)
We use the terminology introduced here for the example in this post. Depending on the capabilities of the on-premises cluster, you can adjust these concepts. For example, the compute cluster could use Kubernetes or SLURM instead of Spark.
Job manager
The job manager is responsible for communicating with on-premises clusters to trigger big data jobs and query their status. It’s a Step Functions state machine that consists of three steps, as illustrated in the following figure.

The first step is JobQueueRequest, which makes a request to the job queue manager component and waits for the callback. When the job queue manager sends OK to the waiting step with a callback pattern, the second step StartJobRun runs.
The StartJobRun step communicates with the on-premises environment (for example, via HTTP post to a REST API endpoint) to trigger an on-premises job.
The third step GetJobStatus queries the job status from the on-premises cluster. If the job status is InProgress, the state machine waits for a configured time. When the Wait state is over, it returns to the GetJobStatus step to query the job status again in a loop. When the job returns a successful state from the on-premises cluster, the state machine completes its cycle with a Success state. If the job fails with a timeout or with an error, the state machine completes its cycle with a Fail state.
The following screenshot shows the details of the state machine on the Step Functions console.

Job queue manager
The job queue manager is responsible for managing job queues based on job priorities and cluster utilization. It consists of DynamoDB, Lambda, and EventBridge.
The JobQueue table keeps data of waiting jobs, including jobId as the primary key, priority as the sort key, needed memory and CPU consumptions, callbackId, and timestamp information. You can add further information to the table dynamically if required by the scheduling algorithm.
The following screenshot shows the attribute details of the JobQueue table.
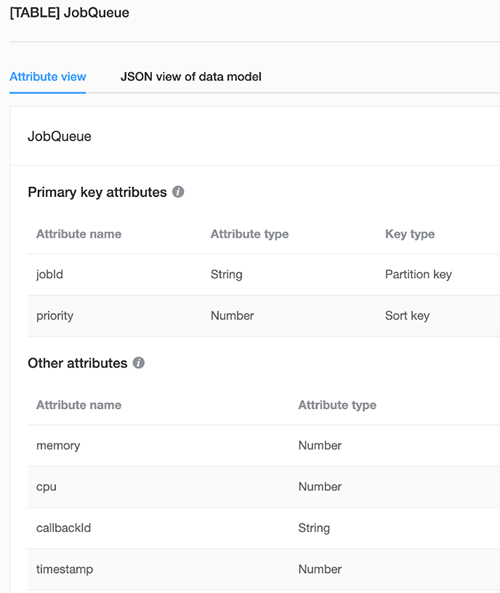
EventBridge triggers the job scheduler Lambda function on a regular bases in a configured interval. First, the job scheduler function gets waiting jobs data from the JobQueue table in DynamoDB. Then it establishes a connection with the on-premises cluster to fetch cluster metrics such as memory and CPU utilization. Based on this information, the function decides which jobs are ready to be triggered on the on-premises cluster.
The scheduling algorithm proposed here follows a simple concept to maximize resource utilization, while respecting the job priority. Essentially, for an on-premises cluster (we could potentially have multiple in different geographies), the job scheduler Lambda function builds a queue of jobs according to their priority, while allocating the first job in the queue to compute resources on the cluster. If enough resources are available, the scheduler moves to the next job in the queue and repeats.
Due to the flexibility of Lambda functions, you can tailor the scheduling algorithm for a specific use case. Cluster scheduling algorithms are still an open research topic with different optimization goals, such as throughput, data location, fairness, deadlines, and more.
Get started
In this section, we provide a starting point for the solution described in this post. The steps walk you through creating a Step Functions state machine with the appropriate template, and the necessary Lambda and DynamoDB interactions to create the job manager and job queue manager building blocks. Example code for the Lambda functions is excluded from this post, because the communication with the on-premises cluster to trigger jobs can vary depending on your on-premises interface.
- On the Step Functions console, choose State machines.
- Choose Create state machine.
- Select Run a sample project.
- Select Job Poller.
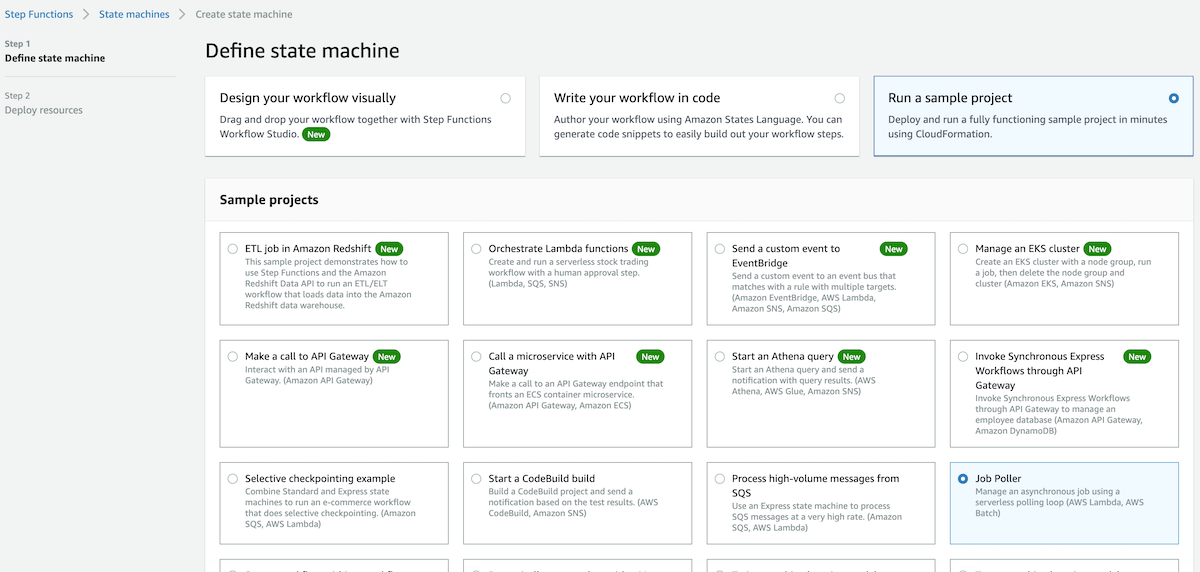
- Scroll down to see the sample projects, which are defined using Amazon States Language (ASL).
- Review the example definition, then choose Next.
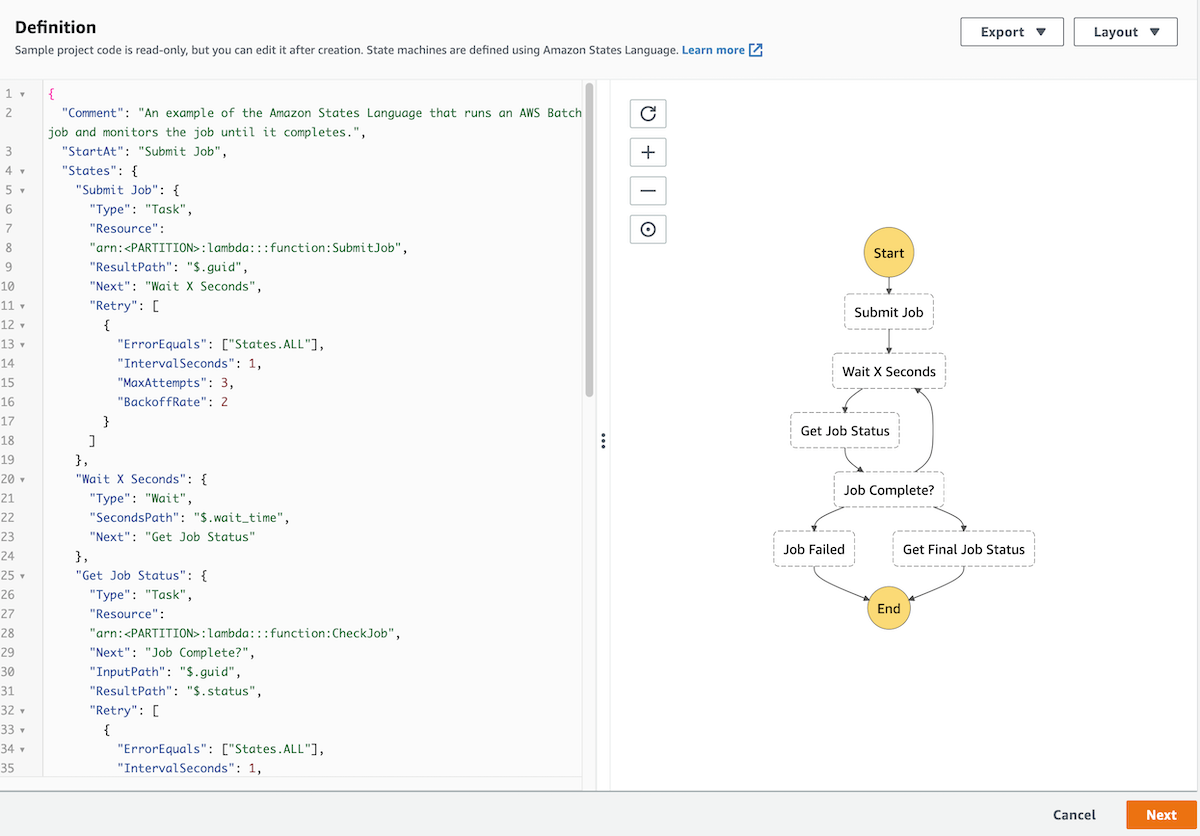
- Choose Deploy resources.
Deployment can take up to 10 minutes.
The deployment creates the state machine that is responsible for job management. After you deploy the resources, you need to edit the sample ASL code to add the extra JobQueueRequest step in the state machine. - Select the created state machine.
- Choose Edit to add ARNs of the three Lambda functions to make a request in the job queue manager (Job Queue Request), to submit a job to the on-premises cluster (Submit Job), and to poll the status of the jobs (Get Job Status).

Now you’re ready to create the job queue manager. - On the DynamoDB console, create a table for storing job metadata.
- On the EventBridge console, create a scheduled rule that triggers the Lambda function at a configured interval.
- On the Lambda console, create the function that communicates with the on-premises cluster to fetch cluster metrics. It also gets jobs from the DynamoDB table to retrieve information including job priorities, required memory, and CPU to run the job on the on-premises cluster.
Limitations
This solution uses Step Functions to track all jobs until completion, and therefore the Step Functions quotas must be considered for potential use cases. Mainly, a workflow can run for a maximum of 1 year (cannot be increased) and by default 1 million parallel runs can run in a single account (can be increased to millions). See Quotas for further details.
Conclusion
This post described how to orchestrate big data jobs running in parallel on on-premises clusters with a Step Functions workflow. To learn more about how to use Step Functions workflows for serverless orchestration, visit Serverless Land.
About the Authors
 Göksel Sarikaya is a Senior Cloud Application Architect at AWS Professional Services. He enables customers to design scalable, high-performance, and cost effective applications using the AWS Cloud. He helps them to be more flexible and competitive during their digital transformation journey.
Göksel Sarikaya is a Senior Cloud Application Architect at AWS Professional Services. He enables customers to design scalable, high-performance, and cost effective applications using the AWS Cloud. He helps them to be more flexible and competitive during their digital transformation journey.
 Nicolas Jacob Baer is a Senior Cloud Application Architect with a strong focus on data engineering and machine learning, based in Switzerland. He works closely with enterprise customers to design data platforms and build advanced analytics/ml use-cases.
Nicolas Jacob Baer is a Senior Cloud Application Architect with a strong focus on data engineering and machine learning, based in Switzerland. He works closely with enterprise customers to design data platforms and build advanced analytics/ml use-cases.
 Shukhrat Khodjaev is a Senior Engagement Manager at AWS ProServe, based out of Berlin. He focuses on delivering engagements in the field of Big Data and AI/ML that enable AWS customers to uncover and to maximize their value through efficient use of data.
Shukhrat Khodjaev is a Senior Engagement Manager at AWS ProServe, based out of Berlin. He focuses on delivering engagements in the field of Big Data and AI/ML that enable AWS customers to uncover and to maximize their value through efficient use of data.