AWS Big Data Blog
Category: Amazon Simple Storage Service (S3)

Trigger cross-region replication of pre-existing objects using Amazon S3 inventory, Amazon EMR, and Amazon Athena
In Amazon Simple Storage Service (Amazon S3), you can use cross-region replication (CRR) to copy objects automatically and asynchronously across buckets in different AWS Regions. CRR is a bucket-level configuration, and it can help you meet compliance requirements and minimize latency by keeping copies of your data in different Regions. CRR replicates all objects in […]

Improve Apache Spark write performance on Apache Parquet formats with the EMRFS S3-optimized committer
November 2024: This post was reviewed and updated for accuracy. The EMRFS S3-optimized committer is a new output committer available for use with Apache Spark jobs as of Amazon EMR 5.19.0. This committer improves performance when writing Apache Parquet files to Amazon S3 using the EMR File System (EMRFS). In this post, we run a performance […]
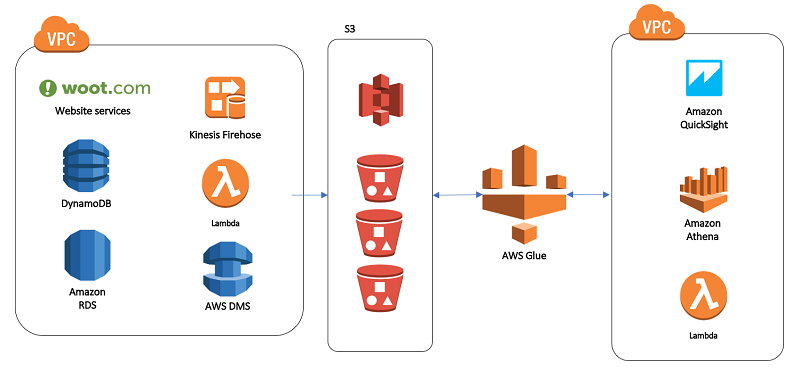
Our data lake story: How Woot.com built a serverless data lake on AWS
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. In this post, we talk about designing a cloud-native data warehouse as a replacement for our legacy data warehouse built on a relational database. At the beginning of the design process, the […]

Migrate to Apache HBase on Amazon S3 on Amazon EMR: Guidelines and Best Practices
This whitepaper walks you through the stages of a migration. It also helps you determine when to choose Apache HBase on Amazon S3 on Amazon EMR, plan for platform security, tune Apache HBase and EMRFS to support your application SLA, identify options to migrate and restore your data, and manage your cluster in production.
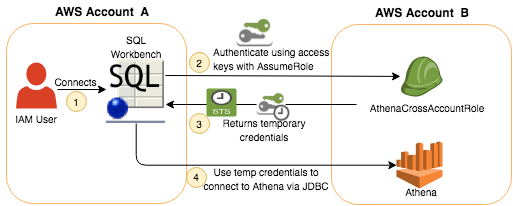
Connect to Amazon Athena with federated identities using temporary credentials
This post walks through three scenarios to enable trusted users to access Athena using temporary security credentials. First, we use SAML federation where user credentials were stored in Active Directory. Second, we use a custom credentials provider library to enable cross-account access. And third, we use an EC2 Instance Profile role to provide temporary credentials for users in our organization to access Athena.

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 2
August 2024: This post was reviewed and updated for accuracy. In part 1 of this series, we demonstrated how to build a data pipeline in support of a data lake. We used key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we discuss […]

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 1
In this two-part series, we show you how to build a data pipeline in support of a data lake. We use key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we focus on generating simple inferences from that data that can support RTP parameters.

Build a Concurrent Data Orchestration Pipeline Using Amazon EMR and Apache Livy
In this post, we explore orchestrating a Spark data pipeline on Amazon EMR using Apache Livy and Apache Airflow, we create a simple Airflow DAG to demonstrate how to run spark jobs concurrently, and we see how Livy helps to hide the complexity to submit spark jobs via REST by using optimal EMR resources.

How Goodreads offloads Amazon DynamoDB tables to Amazon S3 and queries them using Amazon Athena
In this post, we show you how to export data from a DynamoDB table, convert it into a more efficient format with AWS Glue, and query the data with Athena. This approach gives you a way to pull insights from your data stored in DynamoDB.
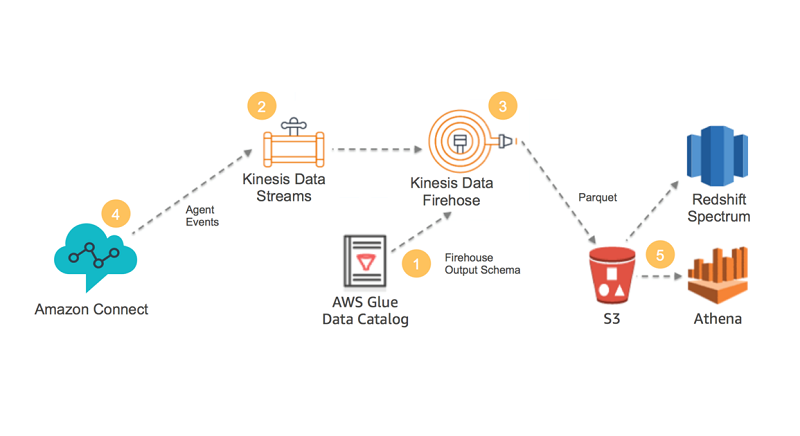
Analyze Apache Parquet optimized data using Amazon Kinesis Data Firehose, Amazon Athena, and Amazon Redshift
Kinesis Data Firehose can now save data to Amazon S3 in Apache Parquet or Apache ORC format. These are optimized columnar formats that are highly recommended for best performance and cost-savings when querying data in S3. This feature directly benefits you if you use Amazon Athena, Amazon Redshift, AWS Glue, Amazon EMR, or any other big data tools that are available from the AWS Partner Network and through the open-source community.