AWS Big Data Blog
How Tipico democratized data transformations using Amazon Managed Workflows for Apache Airflow and AWS Batch
This is a guest post by Jake J. Dalli, Data Platform Team Lead at Tipico, in partnership with AWS.
Tipico is the number one name in sports betting in Germany. Every day, we connect millions of fans to the thrill of sport, combining technology, passion, and trust to deliver fast, secure, and exciting betting, both online and in more than a thousand retail shops across Germany. We also bring this experience to Austria, where we proudly operate a strong sports betting business.
In this post, we show how Tipico built a unified data transformation platform using Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and AWS Batch.
Solution overview
To support critical needs such as product monitoring, customer insights, and revenue assurance, our central data function needed to provide the tools for several cross-functional analytics and data science teams to run scalable batch workloads on the existing data warehouse, powered by Amazon Redshift. The workloads of Tipico’s data community included extract, transform, and load (ELT), statistical modeling, machine learning (ML) training, and reporting across diverse frameworks and languages.
In the past, analytics teams operated in isolation, distinct from each other and the central data function. Different teams maintained their own set of tools, often performing the same function and creating data silos. Lack of visibility meant a lack of standardization. This siloed approach slowed down the delivery of insights and prevented the company from achieving a unified data strategy that ensured availability and scalability.
The need to introduce a single, unified platform that promoted visibility and collaboration became clear. However, the diversity of workloads brought another layer of complexity. Teams needed to tackle different types of problems and brought distinct skillsets and preferences in tooling. Analysts might rely heavily on SQL and business intelligence (BI) platforms, whereas data scientists preferred Python or R, and engineers leaned on containerized workflows or orchestration frameworks.
Our goal was to architect a new system that supports diversity while maintaining operational control, delivering an open orchestration platform with built-in security isolation, scheduling, retry mechanisms, fine-grained role-based access control (RBAC), and governance features such as two-person approval for production workflows. We achieved this by designing a system with the following principles:
- Bring Your Own Container (BYOC) – Teams are given the flexibility to package their workloads as containers and are free to choose dependencies, libraries, or runtime environments. For teams with highly specialized workloads, this meant that they could work in a setup tailored to their needs while also operating within a harmonized platform. On the other hand, teams that didn’t require fully customized environments could redesign their workloads to align with existing workloads.
- Centralized orchestration for full transparency – All teams can see all workflows and build interdependencies between them
- Shared orchestration, isolated compute – Workloads run in team-specific Docker containers within a unified compute environment, providing scalability while keeping execution traceable to each team.
- Standardized interfaces, flexible execution – Common patterns (operators, hooks, logging, or monitoring) reduce complexity, and teams retain freedom to innovate within their containers.
- Cross-team approvals for critical workflows stored inside version control – Changes follow a four-eye principle, requiring review and approval from another team before execution, providing accountability and reducing risk. This allowed our core data function to monitor and contribute suggestions to work across different analytics teams.
We devised a system wherein orchestration and execution of tasks operate on shared infrastructure, which teams interact with through domain-specific infrastructure. In Tipico’s case, each team pushes images to team-owned container instances. Such containers provide code for workflows, including execution of ELT pipelines or transformations on top of domain-specific data lakes.
The following diagram shows the solution architecture.
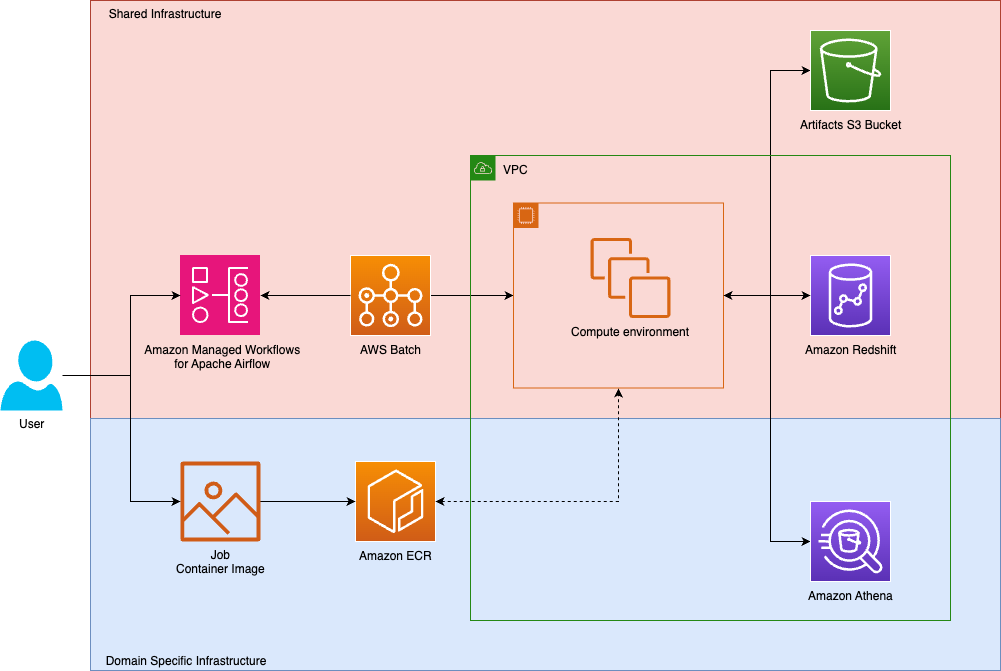
The technical challenge was to architect a flexible and high-performance orchestration layer that could scale reliably while also remaining framework-agnostic, integrating seamlessly with existing infrastructure.
When designing our system, we were aware of the several container orchestration solutions offered by Amazon Web Services (AWS), including Amazon Elastic Kubernetes Service (Amazon EKS), Amazon Elastic Container Service (Amazon ECS), and AWS Batch, among others. In the end, the team selected AWS Batch because it abstracts away cluster management, provides elastic scaling, and inherently supports batch workloads as a design feature.
Solution details
Before adopting the current solution, Tipico experimented with operating a self-managed Apache Airflow setup. Although it was functional, it became increasingly burdensome to maintain. The shift toward a managed and scalable solution was driven by the need to focus more on empowering teams to deliver rather than maintaining the infrastructure. Tipico replatformed the central orchestration solution using Amazon MWAA and AWS Batch.
Amazon MWAA is a fully managed service that simplifies running open source Apache Airflow on AWS. Users can build and execute data processing workflows while integrating seamlessly with various AWS services, which means developers and data engineers can concentrate on building workflows rather than managing infrastructure.
AWS Batch is a fully managed service that simplifies batch computing in the cloud so users can run batch jobs without needing to provision, manage, or maintain clusters. It automates resource provisioning and workload distribution, with users only paying for the underlying AWS resources consumed.
The new design provides a unified framework where analytics workloads are containerized, orchestrated, and executed on scalable compute and integrated with persistent storage:
- Containerization – Analytics workloads are packaged into Docker containers, with dependencies bundled to provide reproducibility. These images are versioned and stored in Amazon Elastic Container Registry (Amazon ECR). This approach decouples execution from infrastructure and enables consistent behavior across environments.
- Workflow orchestration – Airflow Directed Acyclic Graphs (DAGs) are version-controlled in Git and deployed to Amazon MWAA using a continuous integration and continuous delivery (CI/CD) pipeline. Amazon MWAA schedules and orchestrates tasks, triggering AWS Batch jobs using custom operators. Logs and metrics are streamed to Amazon CloudWatch, enabling real-time observability and alerting.
- Data persistence – Workflows interact with Amazon Simple Storage Service (Amazon S3) for durable storage of inputs, outputs, and intermediate artifacts. Amazon Elastic File System (Amazon EFS) is mounted to Amazon MWAA for fast access to shared code and configuration files, synchronized continuously from the Git repository.
- Scalable compute – Amazon MWAA triggers AWS Batch jobs using standardized job definitions. These jobs run in elastic compute environments such as Amazon Elastic Compute Cloud (Amazon EC2) or AWS Fargate, with secrets securely injected using AWS Secrets Manager. AWS Batch environments auto scale based on workload demand, optimizing cost and performance.
- Security and governance – AWS Identity and Access Management (IAM) roles are scoped per team and workload, providing least-privilege access. Job executions are logged and auditable, with fine-grained access control enforced across Amazon S3, Amazon ECR, and AWS Batch.
Common operators
To streamline the execution of batch jobs across teams, we developed a shared operator that wraps the built-in Airflow AWS Batch operator. This abstraction simplifies the execution of containerized workloads by encapsulating common logic such as:
- Job definition selection
- Job queue targeting
- Environment variable injection
- Secrets resolution
- Retry policies and logging configuration
Parameterization is handled using Airflow Variables and XComs, enabling dynamic behavior across DAG runs. The operator is maintained in a shared Git repository, versioned and centrally governed, but accessible to all teams.
To further accelerate development, some teams use a DAG Factory pattern, which programmatically generates DAGs from configuration files. This reduces boilerplate and enforces consistency so teams can define new workflows declaratively.
By standardizing this operator and supporting patterns, Tipico reduces onboarding friction, promotes reuse, and provides consistent observability and error handling across the analytics ecosystem.
Governance
Governance is enforced through a combination of fine-grained IAM roles, AWS IAM Identity Center and automated role mapping. Each team is assigned a dedicated IAM role, which governs access to AWS services such as Amazon S3, Amazon ECR, AWS Batch and Secrets Manager. These roles are tightly scoped to minimize the extent of damage and provide traceability.
Given that the airflow environment runs version 2.9.2, which doesn’t support multi-tenant access, Tipico developed a custom component that dynamically maps AWS IAM roles to Airflow roles. The component, which executes periodically using Airflow itself, dynamically syncs IAM role assignments with Airflow’s internal RBAC model. Airflow tags are used to govern access to different DAGs, governing which teams have access to execute or modify the settings on the DAG. This aligns access permissions remain with organizational structure and team responsibilities.
Adoption
The shift toward a managed, scalable solution was driven by the need for greater team autonomy, standardization, and scalability. The journey began with a single analytics team validating the new approach. When it was successful, the platform team generalized the solution and rolled it out incrementally to other teams, refining it with each iteration.One of the biggest challenges was migrating legacy code, which often included outdated logic and undocumented dependencies. To support adoption, Tipico introduced a structured onboarding process with hands-on training, real use cases, and internal champions. In some cases, teams also had to adopt Git for the first time—marking a broader shift toward modern engineering practices within the analytics organization.
Key benefits
One of the most valuable outcomes of our new architecture that is primarily built around Amazon MWAA and AWS Batch is to accelerate analytics teams’ time to value. Analysts can now focus on building transformation logic and workloads without worrying about the underlying infrastructure. With this system, analysts can rely on preprepared integrations and analytics patterns used across different teams, supported by standard interfaces developed by the core data team.
Aside from building analytics on Amazon Redshift, the orchestration solution also interfaces with several other analytics services such as Amazon Athena and AWS Glue ETL, providing maximum flexibility on the type of workloads being delivered. Teams within the organization have also shared practices in using different frameworks, such as dbt Labs, to reuse custom developments to carry out standard processes.
Another valuable outcome is the ability to clearly segregate costs across teams. Within the architecture, Airflow delegates heavy lifting to AWS Batch, providing task isolation that spans beyond Airflow’s built-in workers. Through this, we gain granular visibility into resource usage and accurate cost attribution, promoting financial accountability across the organization.
Finally, the platform also provides embedded governance and security, with RBAC and standardized secrets management providing an operationalized model for securing and governing working flows across different teams.
Teams can now focus on building and iterating quickly, knowing that the surrounding structures provide full transparency and are coherent with the organization’s governance, architecture, and FinOps goals. At the same time, centralized orchestration fosters a collaborative environment where teams can discover, reuse, and build upon each other’s workflows, driving innovation and reducing duplication across the data landscape.
Conclusion
By reimagining our orchestration layer with Amazon MWAA and AWS Batch, Tipico has unlocked a new level of agility and transparency across its data workflows.
Previously, analytics teams faced long lead times, often stretching into weeks, to implement new reporting use cases. Much of this time was spent identifying datasets, aligning transformation logic, discovering integration options, and navigating inconsistent quality assurance processes. Today, that has changed. Analysts can now develop and deploy a use case within a single business day, shifting their focus from groundwork to action.
The modern architecture empowers teams to move faster and more independently within a secure, governed, and scalable framework. The result is a collaborative data ecosystem where experimentation is encouraged, operational overhead is reduced, and insights are delivered at speed.
To start building your own orchestrated data platform, explore the Get started with Amazon Managed Workflows for Apache Airflow and AWS Batch User Guide. These services can help you achieve similar results in democratizing data transformations across your organization. For hands-on experience with these solutions, try our Amazon MWAA for Analytics Workshop or contact your AWS account team to learn more.