AWS Big Data Blog

Managing COVID-19 exposure with crowd tracing
This is a guest blog post by AWS partner Aspire Ventures As we enter winter, with fewer options to be outdoors, our personal choices can impact our risk of contracting the COVID-19 virus even more. The New England Journal of Medicine publication showed real-world examples of the effectiveness of masks and social distancing in mitigating […]

Detect change points in your event data stream using Amazon Kinesis Data Streams, Amazon DynamoDB and AWS Lambda
The success of many modern streaming applications depends on the ability to sequentially detect each change as soon as possible after it occurs, while continuing to monitor the data stream as it evolves. Applications of change point detection range across genomics, marketing, and finance, to name a few. In genomics, change point detection can help […]

Building Python modules from a wheel for Spark ETL workloads using AWS Glue 2.0
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load your data for analytics. AWS Glue 2.0 features an upgraded infrastructure for running Apache Spark ETL jobs in AWS Glue with reduced startup times. With reduced startup delay time and lower minimum billing duration, overall […]

Creating a source to Lakehouse data replication pipe using Apache Hudi, AWS Glue, AWS DMS, and Amazon Redshift
February 2021 update – Please refer to the post Writing to Apache Hudi tables using AWS Glue Custom Connector to learn about an easier mechanism to write to Hudi tables using AWS Glue Custom Connector. In this post, we include the modified Apache Hudi JARs as an external dependency. The AWS Glue Custom Connector feature […]

Migrating from Vertica to Amazon Redshift
Amazon Redshift powers analytical workloads for Fortune 500 companies, startups, and everything in between. With Amazon Redshift, you can query petabytes of structured and semi-structured data across your data warehouse, operational database, and your data lake using standard SQL. When you use Vertica, you have to install and upgrade Vertica database software and manage the […]

Building an event-driven application with AWS Lambda and the Amazon Redshift Data API
Event–driven applications are becoming popular with many customers, where applications run in response to events. A primary benefit of this architecture is the decoupling of producer and consumer processes, allowing greater flexibility in application design and building decoupled processes. An example of an even-driven application is an automated workflow being triggered by an event, which […]

Redacting sensitive information with user-defined functions in Amazon Athena
Amazon Athena now supports user-defined functions (in Preview), a feature that enables you to write custom scalar functions and invoke them in SQL queries. Although Athena provides built-in functions, UDFs enable you to perform custom processing such as compressing and decompressing data, redacting sensitive data, or applying customized decryption. You can write your UDFs in […]

Federated API access to Amazon Redshift using an Amazon Redshift connector for Python
July 2023: This post was reviewed for accuracy. Amazon Redshift is the leading cloud data warehouse that delivers performance 10 times faster at one-tenth of the cost of traditional data warehouses by using massively parallel query execution, columnar storage on high-performance disks, and results caching. You can confidently run mission-critical workloads, even in highly regulated […]
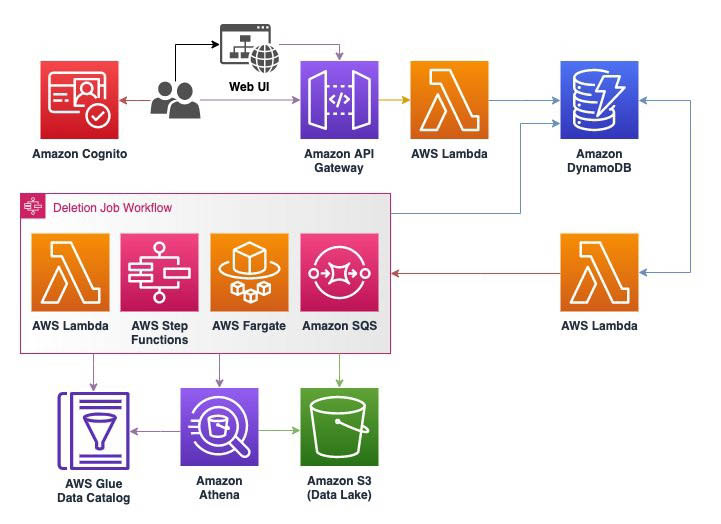
Handling data erasure requests in your data lake with Amazon S3 Find and Forget
February 2024: This post was reviewed and updated for accuracy. Data lakes are a popular choice for organizations to store data around their business activities. Best practice design of data lakes impose that data is immutable once stored, but new regulations such as the European General Data Protection Regulation (GDPR), California Consumer Privacy Act (CCPA), […]

Extracting and joining data from multiple data sources with Athena Federated Query
With modern day architectures, it’s common to have data sitting in various data sources. We need proper tools and technologies across those sources to create meaningful insights from stored data. Amazon Athena is primarily used as an interactive query service that makes it easy to analyze unstructured, semi-structured, and structured data stored in Amazon Simple […]