AWS DevOps & Developer Productivity Blog
Deploy data lake ETL jobs using CDK Pipelines
This post is co-written with Isaiah Grant, Cloud Consultant at 2nd Watch.
Many organizations are building data lakes on AWS, which provides the most secure, scalable, comprehensive, and cost-effective portfolio of services. Like any application development project, a data lake must answer a fundamental question: “What is the DevOps strategy?” Defining a DevOps strategy for a data lake requires extensive planning and multiple teams. This typically requires multiple development and test cycles before maturing enough to support a data lake in a production environment. If an organization doesn’t have the right people, resources, and processes in place, this can quickly become daunting.
What if your data engineering team uses basic building blocks to encapsulate data lake infrastructure and data processing jobs? This is where CDK Pipelines brings the full benefit of infrastructure as code (IaC). CDK Pipelines is a high-level construct library within the AWS Cloud Development Kit (AWS CDK) that makes it easy to set up a continuous deployment pipeline for your AWS CDK applications. The AWS CDK provides essential automation for your release pipelines so that your development and operations team remain agile and focus on developing and delivering applications on the data lake.
In this post, we discuss a centralized deployment solution utilizing CDK Pipelines for data lakes. This implements a DevOps-driven data lake that delivers benefits such as continuous delivery of data lake infrastructure, data processing, and analytical jobs through a configuration-driven multi-account deployment strategy. Let’s dive in!
Data lakes on AWS
A data lake is a centralized repository where you can store all of your structured and unstructured data at any scale. Store your data as is, without having to first structure it, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning in order to guide better decisions. To further explore data lakes, refer to What is a data lake?
We design a data lake with the following elements:
- Secure data storage
- Data cataloging in a central repository
- Data movement
- Data analysis
The following figure represents our data lake.
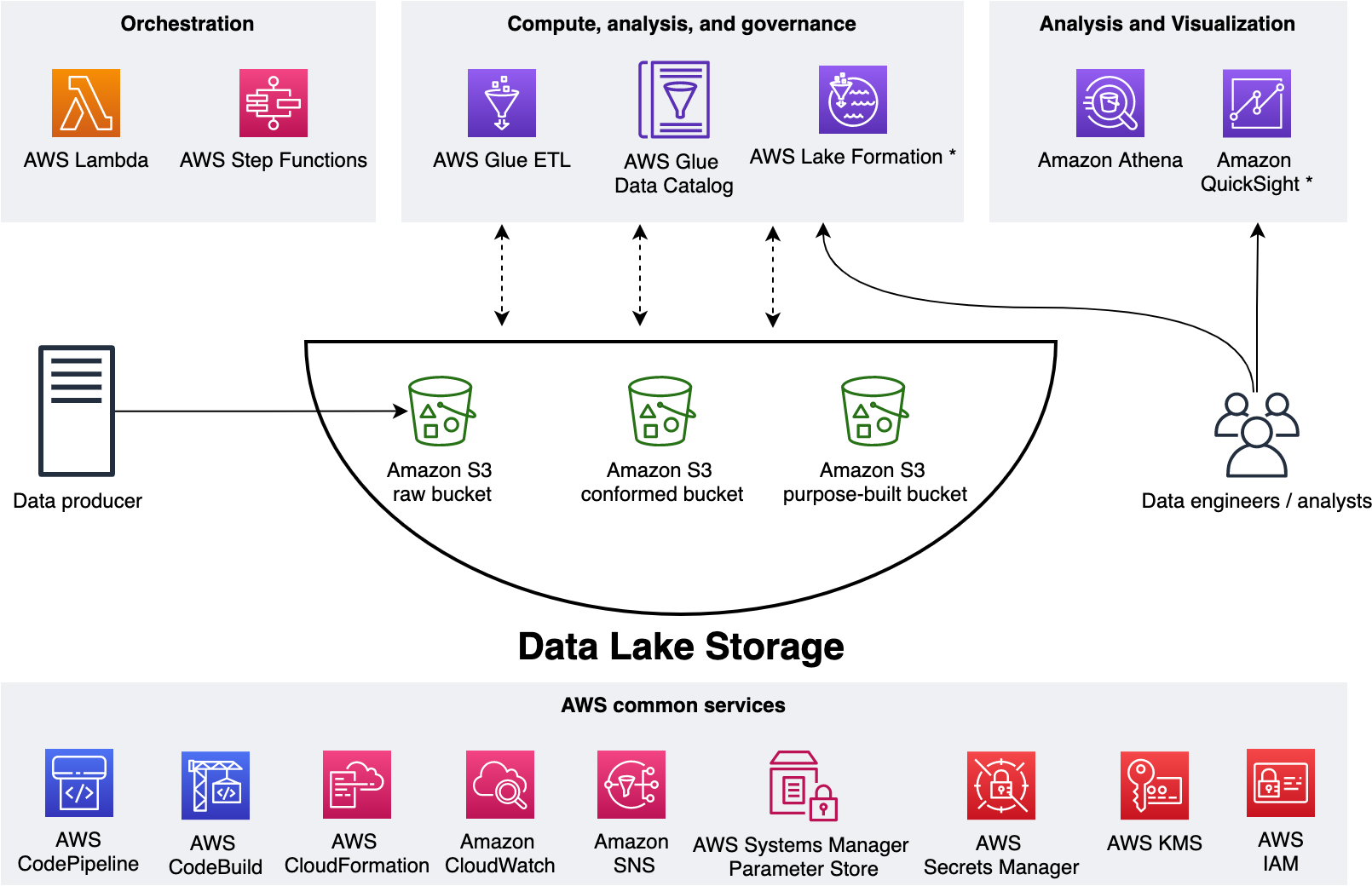
We use three Amazon Simple Storage Service (Amazon S3) buckets:
- raw – Stores the input data in its original format
- conformed – Stores the data that meets the data lake quality requirements
- purpose-built – Stores the data that is ready for consumption by applications or data lake consumers
The data lake has a producer where we ingest data into the raw bucket at periodic intervals. We utilize the following tools: AWS Glue processes and analyzes the data. AWS Glue Data Catalog persists metadata in a central repository. AWS Lambda and AWS Step Functions schedule and orchestrate AWS Glue extract, transform, and load (ETL) jobs. Amazon Athena is used for interactive queries and analysis. Finally, we engage various AWS services for logging, monitoring, security, authentication, authorization, alerting, and notification.
A common data lake practice is to have multiple environments such as dev, test, and production. Applying the IaC principle for data lakes brings the benefit of consistent and repeatable runs across multiple environments, self-documenting infrastructure, and greater flexibility with resource management. The AWS CDK offers high-level constructs for use with all of our data lake resources. This simplifies usage and streamlines implementation.
Before exploring the implementation, let’s gain further scope of how we utilize our data lake.
The solution
Our goal is to implement a CI/CD solution that automates the provisioning of data lake infrastructure resources and deploys ETL jobs interactively. We accomplish this as follows: 1) applying separation of concerns (SoC) design principle to data lake infrastructure and ETL jobs via dedicated source code repositories, 2) a centralized deployment model utilizing CDK pipelines, and 3) AWS CDK enabled ETL pipelines from the start.
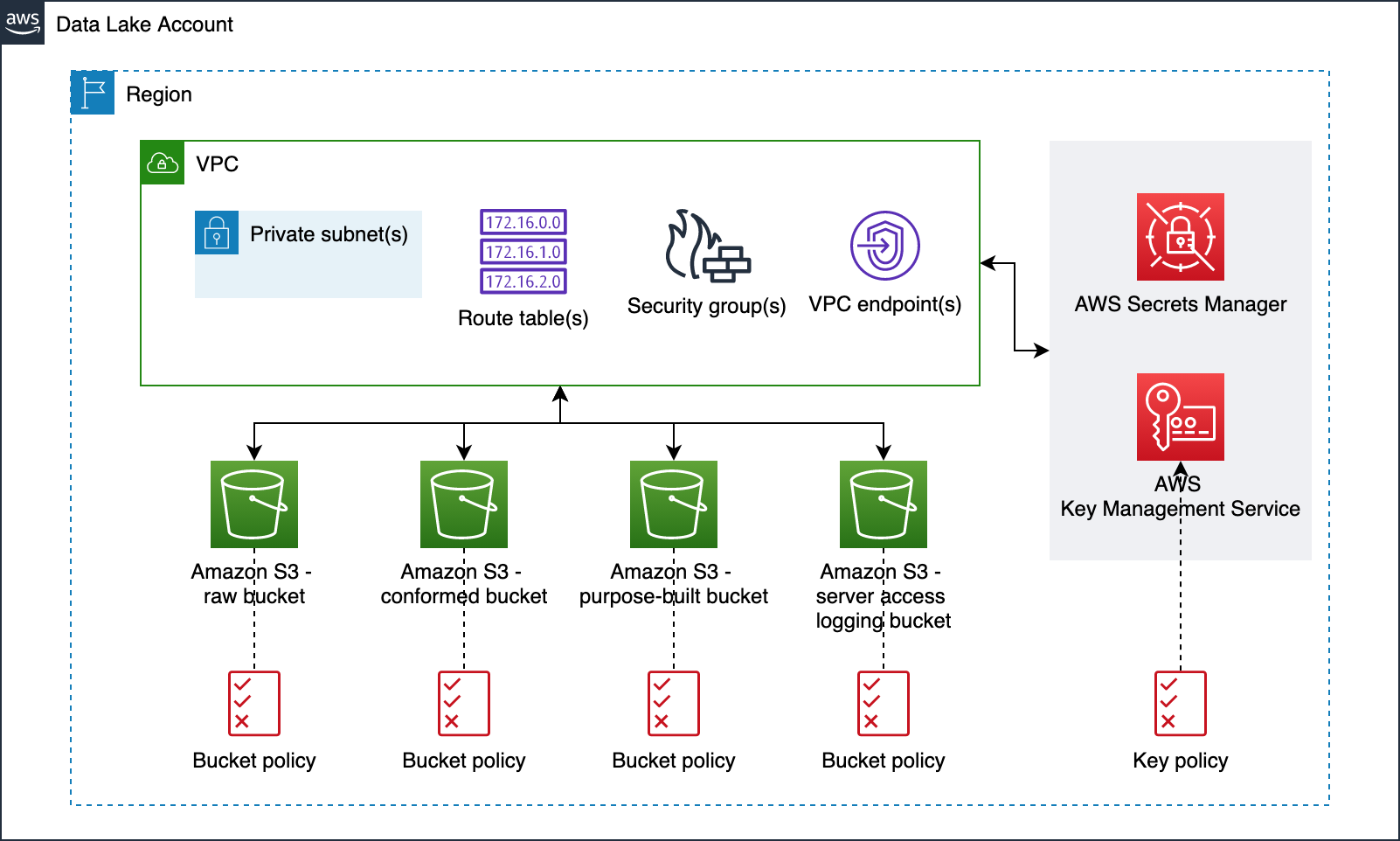
Data lake infrastructure
Our data lake infrastructure provisioning includes Amazon S3 buckets, S3 bucket policies, AWS Key Management Service (KMS) encryption keys, Amazon Virtual Private Cloud (Amazon VPC), subnets, route tables, security groups, VPC endpoints, and secrets in AWS Secrets Manager. The following diagram illustrates this.
Data lake ETL jobs
For our ETL jobs, we process New York City TLC Trip Record Data. The following figure displays our ETL process, wherein we run two ETL jobs within a Step Functions state machine.
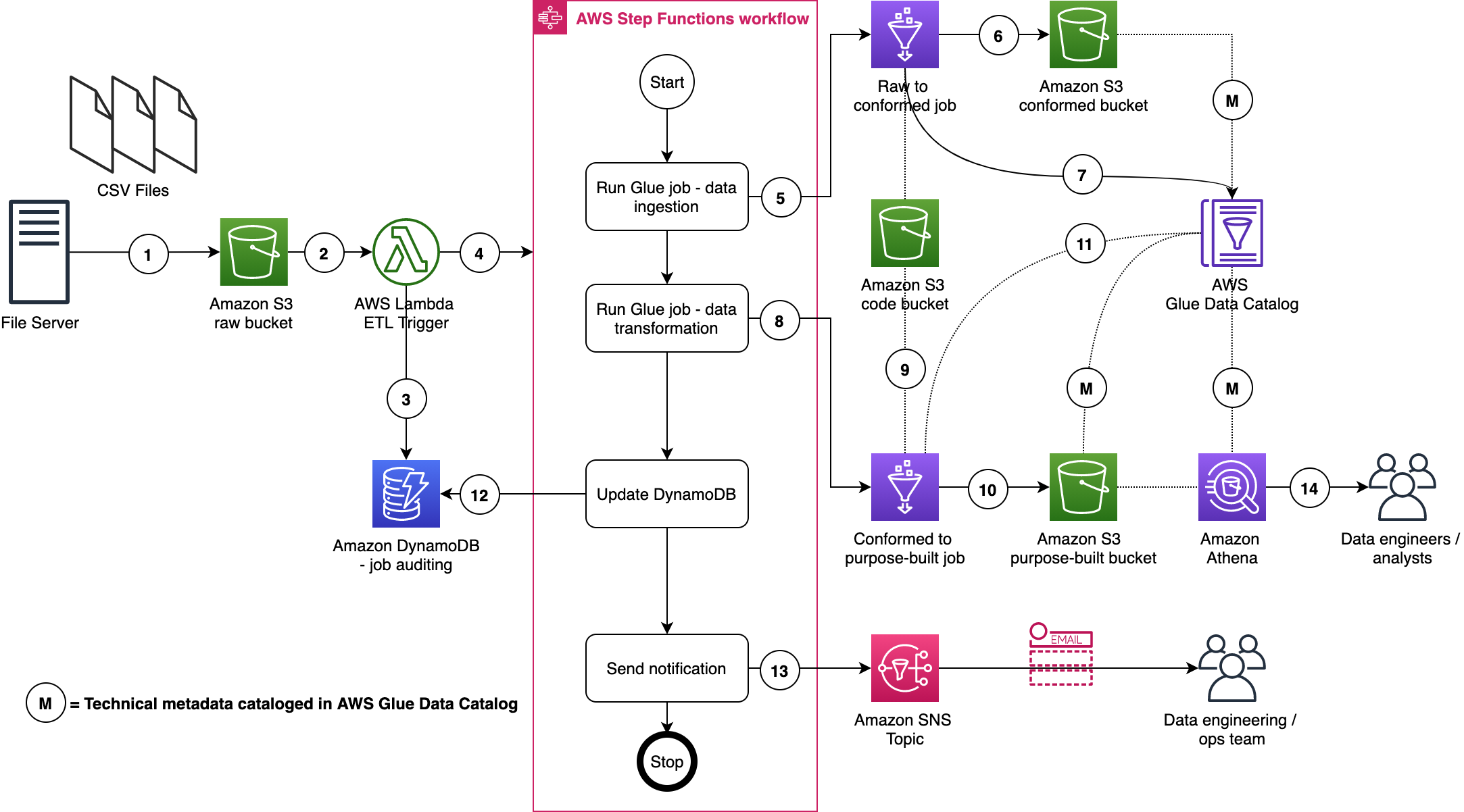
Here are a few important details:
- A file server uploads files to the S3 raw bucket of the data lake. The file server is a data producer and source for the data lake. We assume that the data is pushed to the raw bucket.
- Amazon S3 triggers an event notification to the Lambda function.
- The function inserts an item in the Amazon DynamoDB table in order to track the file processing state. The first state written indicates the AWS Step Function start.
- The function starts the state machine.
- The state machine runs an AWS Glue job (Apache Spark).
- The job processes input data from the raw zone to the data lake conformed zone. The job also converts CSV input data to Parquet formatted data.
- The job updates the Data Catalog table with the metadata of the conformed Parquet file.
- A second AWS Glue job (Apache Spark) processes the input data from the conformed zone to the purpose-built zone of the data lake.
- The job fetches ETL transformation rules from the Amazon S3 code bucket and transforms the input data.
- The job stores the result in Parquet format in the purpose-built zone.
- The job updates the Data Catalog table with the metadata of the purpose-built Parquet file.
- The job updates the DynamoDB table and updates the job status to completed.
- An Amazon Simple Notification Service (Amazon SNS) notification is sent to subscribers that states the job is complete.
- Data engineers or analysts can now analyze data via Athena.
We will discuss data formats, Glue jobs, ETL transformation logics, data cataloging, auditing, notification, orchestration, and data analysis in more detail in AWS CDK Pipelines for Data Lake ETL Deployment GitHub repository. This will be discussed in the subsequent section.
Centralized deployment
Now that we have data lake infrastructure and ETL jobs ready, let’s define our deployment model. This model is based on the following design principles:
- A dedicated AWS account to run CDK pipelines.
- One or more AWS accounts into which the data lake is deployed.
- The data lake infrastructure has a dedicated source code repository. Typically, data lake infrastructure is a one-time deployment and rarely evolves. Therefore, a dedicated code repository provides a landing zone for your data lake.
- Each ETL job has a dedicated source code repository. Each ETL job may have unique AWS service, orchestration, and configuration requirements. Therefore, a dedicated source code repository will help you more flexibly build, deploy, and maintain ETL jobs.
We organize our source code repo into three branches: dev (main), test, and prod. In the deployment account, we manage three separate CDK Pipelines and each pipeline is sourced from a dedicated branch. Here we choose a branch-based software development method in order to demonstrate the strategy in more complex scenarios where integration testing and validation layers require human intervention. As well, these may not immediately follow with a corresponding release or deployment due to their manual nature. This facilitates the propagation of changes through environments without blocking independent development priorities. We accomplish this by isolating resources across environments in the central deployment account, allowing for the independent management of each environment, and avoiding cross-contamination during each pipeline’s self-mutating updates. The following diagram illustrates this method.
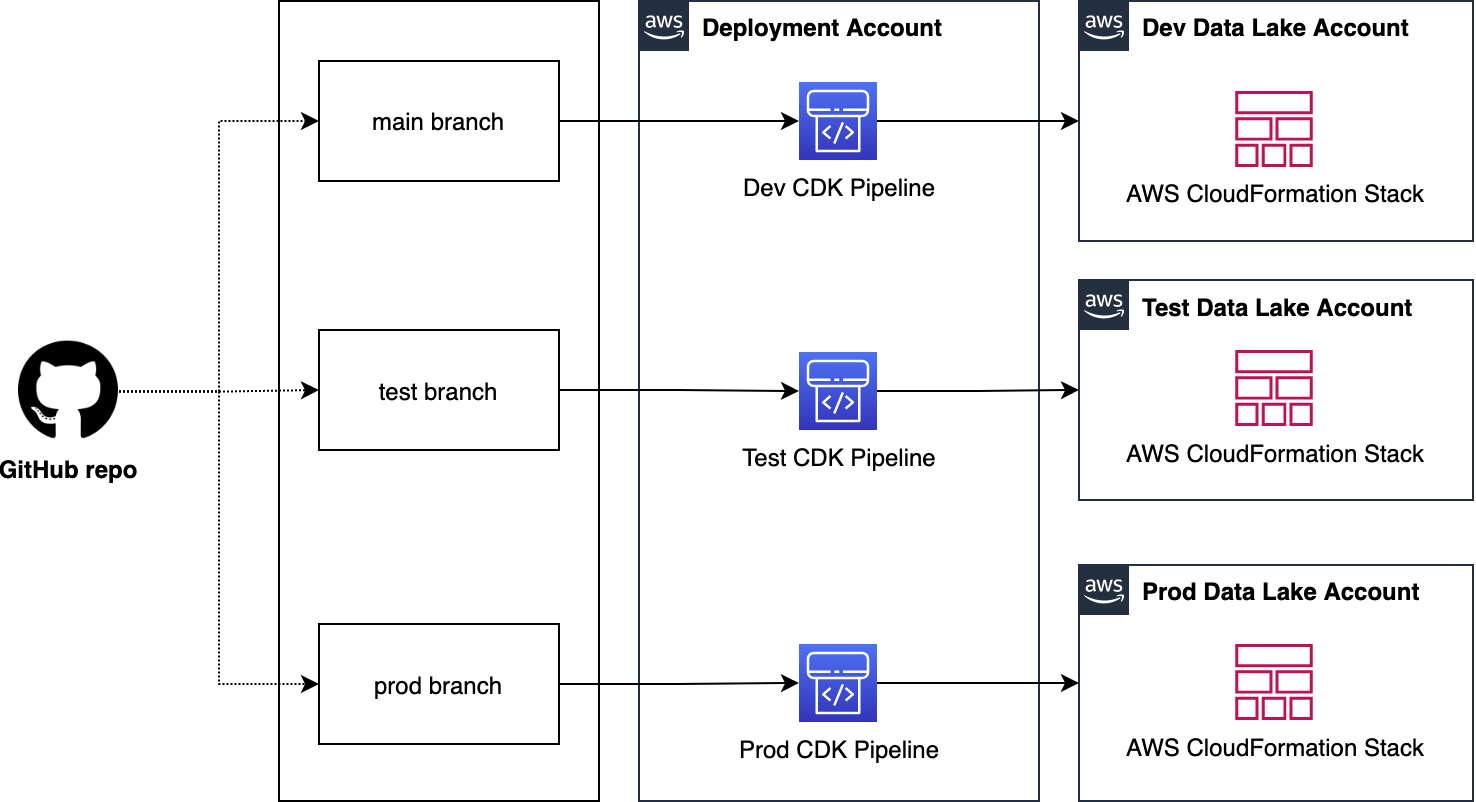
Note: This centralized deployment strategy can be adopted for trunk-based software development with minimal solution modification.
Deploying data lake ETL jobs
The following figure illustrates how we utilize CDK Pipelines to deploy data lake infrastructure and ETL jobs from a central deployment account. This model follows standard nomenclature from the AWS CDK. Each repository represents a cloud infrastructure code definition. This includes the pipelines construct definition. Pipelines have one or more actions, such as cloning the source code (source action) and synthesizing the stack into an AWS CloudFormation template (synth action). Each pipeline has one or more stages, such as testing and deploying. In an AWS CDK app context, the pipelines construct is a stack like any other stack. Therefore, when the AWS CDK app is deployed, a new pipeline is created in AWS CodePipeline.
This provides incredible flexibility regarding DevOps. In other words, as a developer with an understanding of AWS CDK APIs, you can harness the power and scalability of AWS services such as CodePipeline, AWS CodeBuild, and AWS CloudFormation.
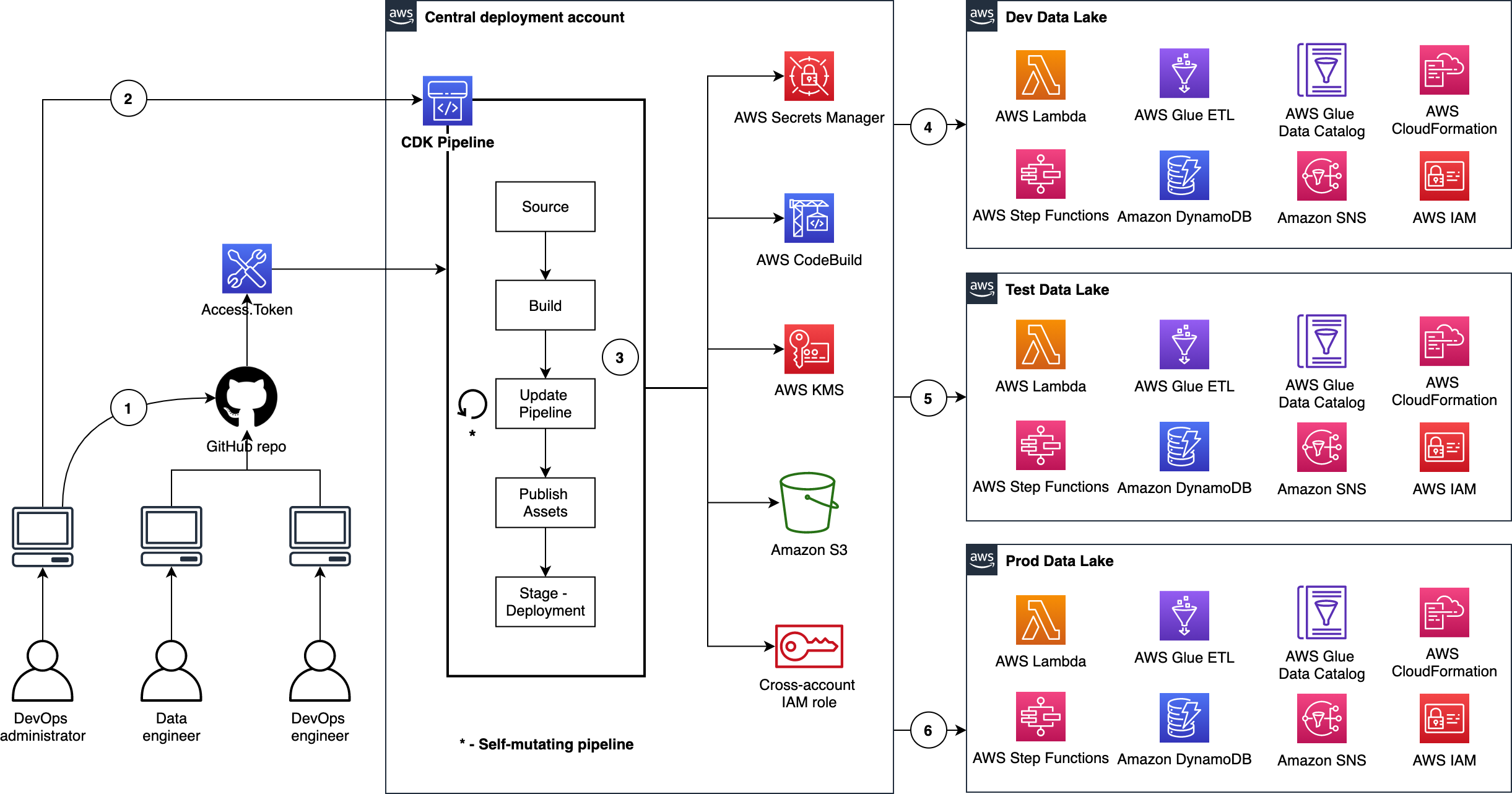
Here are a few important details:
- The DevOps administrator checks in the code to the repository.
- The DevOps administrator (with elevated access) facilitates a one-time manual deployment on a target environment. Elevated access includes administrative privileges on the central deployment account and target AWS environments.
- CodePipeline periodically listens to commit events on the source code repositories. This is the self-mutating nature of CodePipeline. It’s configured to work with and can update itself according to the provided definition.
- Code changes made to the main repo branch are automatically deployed to the data lake dev environment.
- Code changes to the repo test branch are automatically deployed to the test environment.
- Code changes to the repo prod branch are automatically deployed to the prod environment.
CDK Pipelines starter kits for data lakes
Want to get going quickly with CDK Pipelines for your data lake? Start by cloning our two GitHub repositories. Here is a summary:
CDK Pipelines for Data Lake Infrastructure Deployment
This repository contains the following reusable resources:
- CDK Application
- CDK Pipelines stack
- CDK Pipelines deploy stage
- Amazon VPC stack
- Amazon S3 stack
It also contains the following automation scripts:
- AWS environments configuration
- Deployment account bootstrapping
- Target account bootstrapping
- Account secrets configuration (e.g., GitHub access tokens)
CDK Pipelines for Data Lake ETL Deployment
This repository contains the following reusable resources:
- CDK Application
- CDK Pipelines stack
- CDK Pipelines deploy stage
- Amazon DynamoDB stack
- AWS Glue stack
- AWS Step Functions stack
It also contains the following:
- AWS Lambda scripts
- AWS Glue scripts
- AWS Step Functions State machine script
Advantages
This section summarizes some of the advantages offered by this solution.
Scalable and centralized deployment model
We utilize a scalable and centralized deployment model to deliver end-to-end automation. This allows DevOps and data engineers to use the single responsibility principal while maintaining precise control over the deployment strategy and code quality. The model can readily be expanded to more accounts, and the pipelines are responsive to custom controls within each environment, such as a production approval layer.
Configuration-driven deployment
Configuration in the source code and AWS Secrets Manager allow deployments to utilize targeted values that are declared globally in a single location. This provides consistent management of global configurations and dependencies such as resource names, AWS account Ids, Regions, and VPC CIDR ranges. Similarly, the CDK Pipelines export outputs from CloudFormation stacks for later consumption via other resources.
Repeatable and consistent deployment of new ETL jobs
Continuous integration and continuous delivery (CI/CD) pipelines allow teams to deploy to production more frequently. Code changes can be safely and securely propagated through environments and released for deployment. This allows rapid iteration on data processing jobs, and these jobs can be changed in isolation from pipeline changes, resulting in reliable workflows.
Cleaning up
You may delete the resources provisioned by utilizing the starter kits. You can do this by running the cdk destroy command using AWS CDK Toolkit. For detailed instructions, refer to the Clean up sections in the starter kit README files.
Conclusion
In this post, we showed how to utilize CDK Pipelines to deploy infrastructure and data processing ETL jobs of your data lake in dev, test, and production AWS environments. We provided two GitHub repositories for you to test and realize the full benefits of this solution first hand. We encourage you to fork the repositories, bring your ETL scripts, bootstrap your accounts, configure account parameters, and continuously delivery your data lake ETL jobs.
Let’s stay in touch via the GitHub—CDK Pipelines for Data Lake Infrastructure Deployment and CDK Pipelines for Data Lake ETL Deployment.
About the authors

Ravi Itha is a Sr. Data Architect at AWS. He works with customers to design and implement Data Lakes, Analytics, and Microservices on AWS. He is an open-source committer and has published more than a dozen solutions using AWS CDK, AWS Glue, AWS Lambda, AWS Step Functions, Amazon ECS, Amazon MQ, Amazon SQS, Amazon Kinesis Data Streams, and Amazon Kinesis Data Analytics for Apache Flink. His solutions can be found at his GitHub handle. Outside of work, he is passionate about books, cooking, movies, and yoga.

Isaiah Grant is a Cloud Consultant at 2nd Watch. His primary function is to design architectures and build cloud-based applications and services. He leads customer engagements and helps customers with enterprise cloud adoptions. In his free time, he is engaged in local community initiatives and enjoys being outdoors with his family.

Zahid Ali is a Data Architect at AWS. He helps customers design, develop, and implement data warehouse and Data Lake solutions on AWS. Outside of work he enjoys playing tennis, spending time outdoors, and traveling.