Artificial Intelligence
Accelerate computer vision training using GPU preprocessing with NVIDIA DALI on Amazon SageMaker
AWS customers are increasingly training and fine-tuning large computer vision (CV) models with hundreds of terabytes of data and millions of parameters. For example, advanced driver assistance systems (ADAS) train perception models to detect pedestrians, road signs, vehicles, traffic lights, and other objects. Identity verification systems for the financial services industry train CV models to verify the authenticity of the person claiming the service with live camera images and official ID documents.
With growing data sizes and increasing model complexity, there is a need to address performance bottlenecks within training jobs to reduce costs and turnaround times. Training bottlenecks include storage space and network throughput to move data in addition to updating model gradients, parameters, and checkpoints. Another common bottleneck with deep learning models is under-utilization of expensive GPU resources due to CPU-bound preprocessing bottlenecks.
Customers want to identify these bottlenecks with debugging tools and improve preprocessing with optimized libraries and other best practices.
Amazon SageMaker allows machine learning (ML) practitioners to build, train, and deploy high-quality models with a broad set of purpose-built ML capabilities. These fully managed services take care of the undifferentiated infrastructure heavy lifting involved in ML projects. SageMaker provides innovative open-source training containers for deep learning frameworks like PyTorch (toolkit, SDK), TensorFlow (toolkit, SDK), and Apache MXNet (toolkit, SDK).
In a previous post, the author highlights the options for optimizing I/O for GPU performance tuning of deep learning training with SageMaker. In this post, we focus specifically on identifying CPU bottlenecks in a SageMaker training job with SageMaker Debugger and moving data preprocessing operations to GPU with NVIDIA Data Loading library (DALI). We’ve made the sample code used for the benchmarking experiment available on GitHub. The repository uses SageMaker training with two implementations of data preprocessing: NVIDIA DALI on GPU, and PyTorch dataloader on CPU, as illustrated in the following diagram.
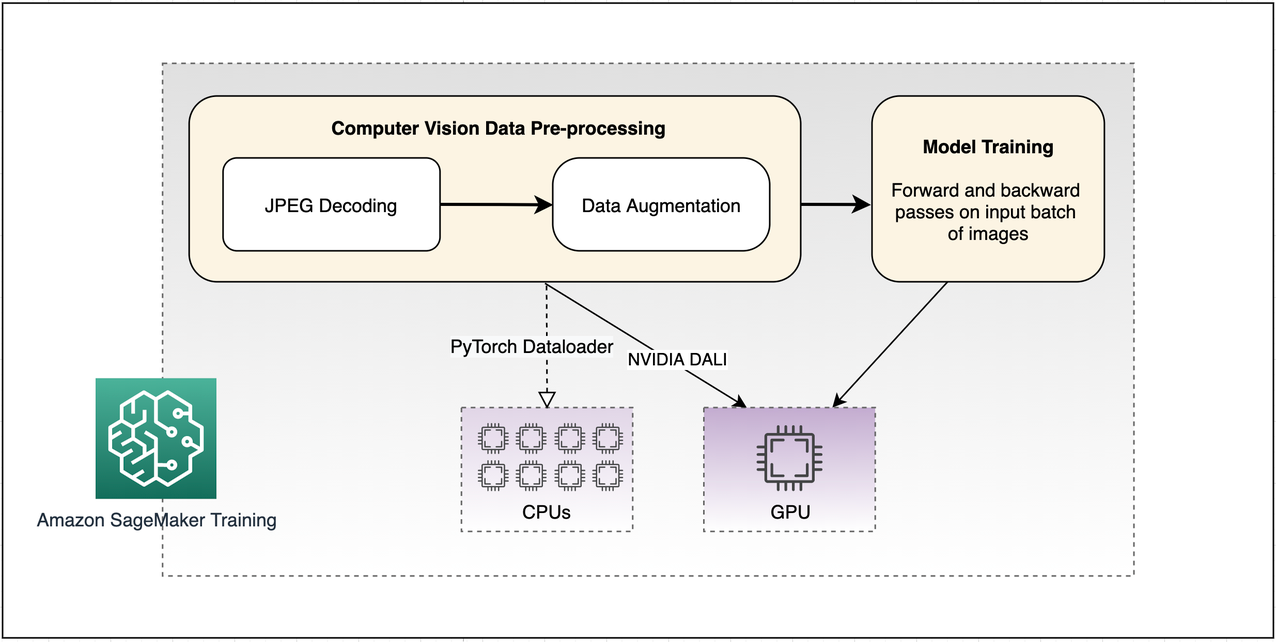
CV data preprocessing typically comprises two compute-intensive steps on CPUs—JPEG decoding and use-case specific augmentations. GPUs can perform some operations faster than CPU with tera-floating point operations per second (tFLOPS). But for the GPU to perform such operations, the data must be available in the GPU memory. The utilization of GPUs varies with model complexity, with larger models requiring more GPU resources. The challenge lies in optimizing the steps of the training pipeline so that the GPU doesn’t starve for the data to perform its computations, thereby maximizing overall resource utilization. The ratio between the required data preprocessing load on the CPU and the amount of model computation on the GPU often depends on the use-case. As explained in another post, a CPU bottleneck typically occurs when this ratio exceeds the ratio between the overall CPU and GPU compute capacity.
Experiment overview
In this post, we demonstrate an example with a PyTorch CV model to visualize resource bottlenecks with Debugger. We compare and contrast performance gains by offloading data preprocessing to GPU using NVIDIA DALI across three model architectures with increasing augmentation load factors.
The following is the complete architecture for the training setup using SageMaker that we use to benchmark the different training job trials.
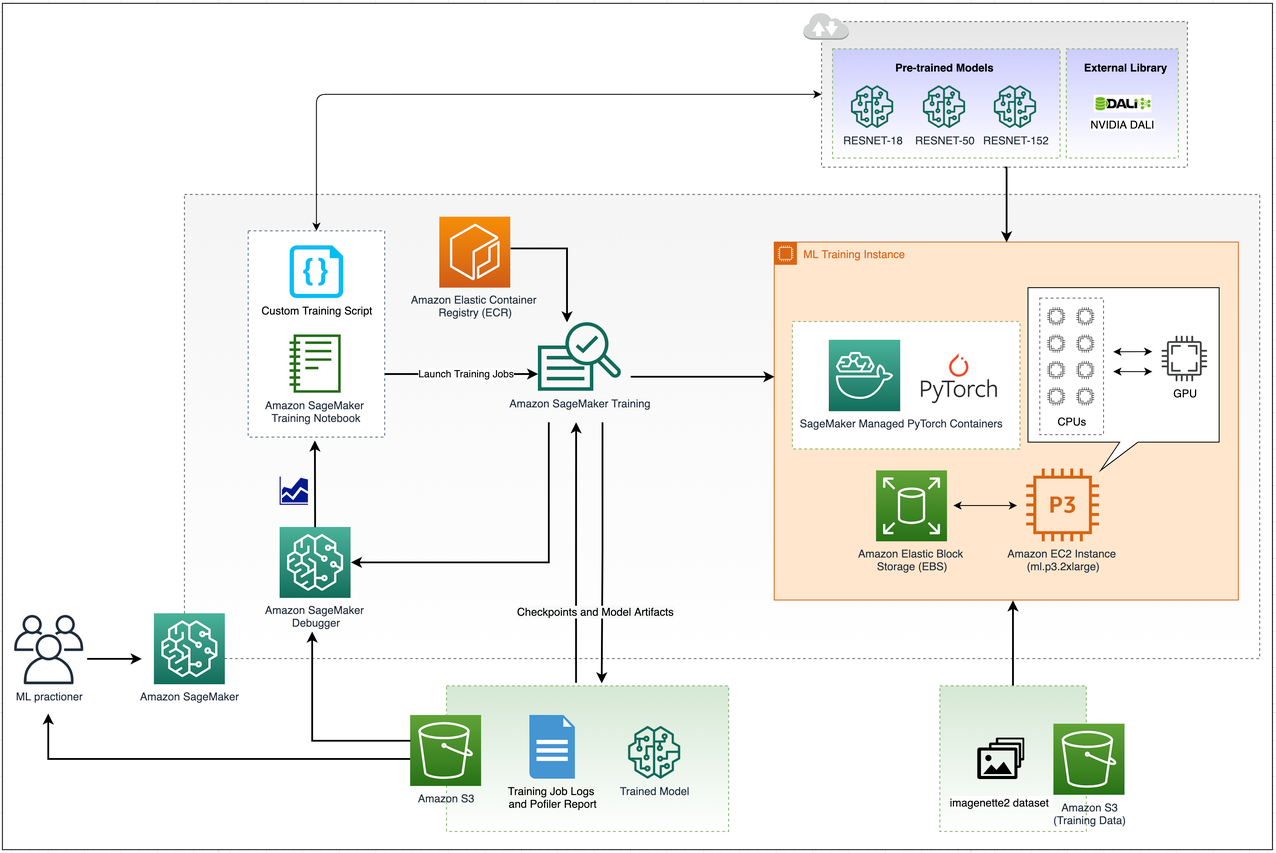
We perform the following trials:
- Trial A – We decode JPEG images on CPUs with libjpeg-turbo, which is a built-in PyTorch dataloader library. We perform augmentation operations on CPUs using PyTorch transform operations. We use this as a baseline to compare the training time with Trial B. You can refer to the augmentation_pytorch method in the training script.
- Trial B – We perform GPU-accelerated JPEG image decoding with nvJPEG, which is a built-in library with NVIDIA DALI. We perform augmentation on GPUs by configuring with NVIDIA DALI Pipeline operations, which is a framework for building optimized preprocessing pipelines for NVIDIA GPU chips. You can refer to the create_dali_pipeline and augmentation_dali methods in the training script.
The goal is to balance the load between the CPUs and GPUs by moving the compute intensive operations of JPEG decoding and augmentation to the GPU. Because we’re increasing the size of the computation graph that is running on GPUs, we need to make sure that there is enough unused memory for data preprocessing operations. You can do this with a smaller training batch size.
For both trials, we use the full-size version of imagenette2 dataset (1.3 GB), which has 13,395 JPEGs with an average size of 144 KB. We run SageMaker training jobs with the PyTorch Estimator 1.8.1 for two epochs with a batch-size of 32 images (298 steps per epoch). We use an Amazon Elastic Compute Cloud (Amazon EC2) P3 instance of ml.p3.2xlarge that has 8 CPUs with 61 GB memory and 1 NVIDIA V100 Tensor Core with 16 GB memory. We use three different CV models of increasing complexities ResNet18, ResNet50, and ResNet152 from the PyTorch pretrained model repository, Torchvision.
Depending on the use case, training CV models often requires heavy data augmentation operations, such as dilation and gaussian blur. We replicate a real-world scenario by introducing a heavy data augmentation load. We use a load factor to repeat the operations of horizontal flip, vertical flip, and random rotation Nx times before resizing, normalizing, and cropping the image.
Identify and compare CPU bottlenecks with Debugger
We measure training time and system metrics with Debugger to identify possible root causes and bottlenecks. Debugger helps capture and visualize real-time model training metrics and resource utilization statistics. They can be captured programmatically using the SageMaker Python SDK or visually through SageMaker Studio.
For the trials conducted with ResNet18 model with an augmentation load of 12x, we used the smdebug library in util_debugger.py to generate the following heat map of CPU and GPU utilization for the two training jobs.
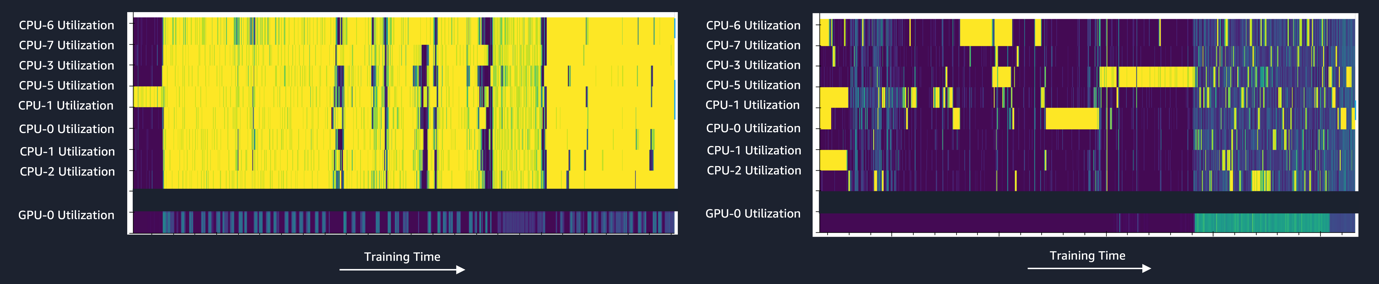
The colors yellow and purple in the heat map indicate utilization close to 100% and 0%, respectively. Trial A shows the CPU bottleneck with all CPU cores at maximum utilization, while the GPU is under-utilized with frequently stalled cycles. This bottleneck is addressed in Trial B with less than 100% CPU utilization and higher GPU utilization during the data preprocessing phase.
Apart from that, the Debugger ProfilerReport aggregates monitoring and profiling rules analysis into a comprehensive report that can help right-size resources and fix bottlenecks using the insights from the profiling results. You can either access this report from Studio or the Amazon Simple Storage Service (Amazon S3) bucket where we have the training outputs. For this experiment trial, the following is a subsection of the Debugger ProfilerReport. It shows the compute usage improvement statistics of CPU and GPU for minimum, maximum, p99, p90, and p50 percentiles for the training jobs.
The following screenshot shows systems statistics for Trial A.

The following screenshot shows systems statistics for Trial B.

We can observe that the p95 CPU utilization dropped from 100% in Trial A to 64.87% in Trial B, thereby addressing the data preprocessing bottleneck. The p95 GPU utilization boosted from 31% to 55% and has further potential to process more load.
For more information about the different options of using Debugger to gain further insights and recommendations, see Identify bottlenecks, improve resource utilization, and reduce ML training costs with the deep profiling feature in Amazon SageMaker Debugger.
Experiment results
The following table shows the training time in seconds per epoch for different augmentation loads for both the trials when using a batch size of 32 in training the three ResNet models for two epochs. The visualization charts following the table summarize the insights from these results.
| Model | Augmentation Load Factor | Trial A (Seconds/Epoch) | Trial B (Seconds/Epoch) | Improvement Training Time (%) |
| ResNet18 | 1 | 41.67 | 21.3 | 48.88 |
| 4 | 49.95 | 21.37 | 57.21 | |
| 8 | 61.92 | 21.08 | 65.95 | |
| 12 | 77.82 | 21.33 | 72.59 | |
| ResNet50 | 1 | 72.64 | 46.94 | 35.37 |
| 4 | 75.21 | 45.02 | 40.14 | |
| 8 | 81.22 | 46.29 | 43.00 | |
| 12 | 88.89 | 46.43 | 47.76 | |
| ResNet152 | 1 | 166.96 | 119.96 | 28.15 |
| 4 | 169.68 | 115.23 | 32.08 | |
| 8 | 169.03 | 117.73 | 30.34 | |
| 12 | 173.18 | 114.38 | 33.95 |
The following chart depicts how Trial B has consistently lower training time than Trial A across all the three models with increasing augmentation load factors. This is due to efficient resource utilization with data preprocessing offloaded to the GPU in Trial B. A complex model (ResNet152 over ResNet18) has more parameters to train and therefore more time is spent in forward and backward pass on the GPU. This results in an increase in overall training time as compared to a less complex model across both trials.
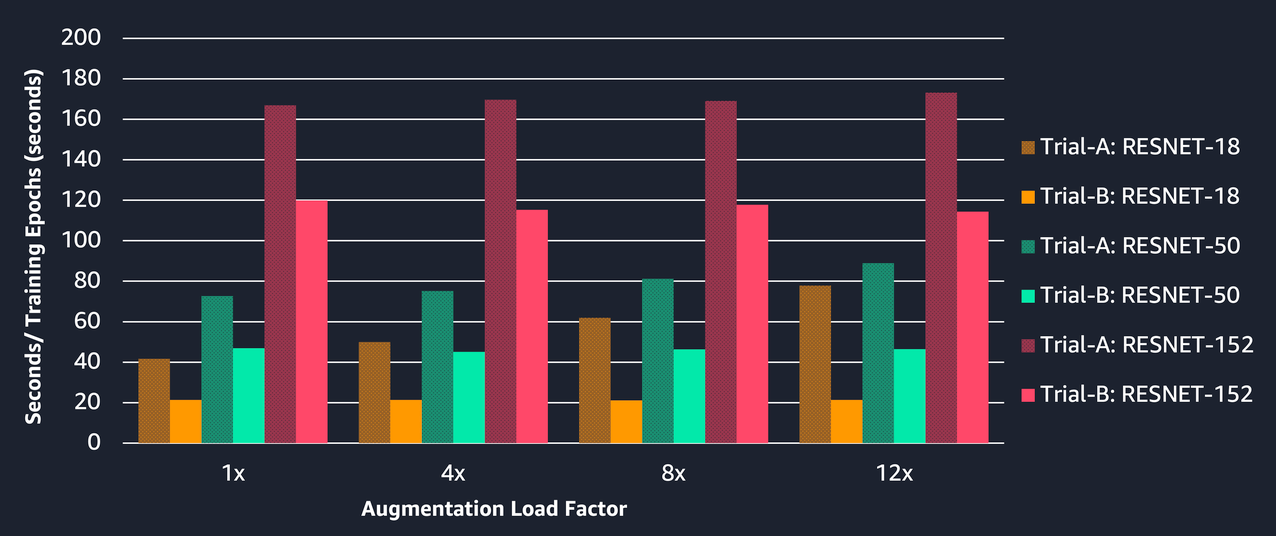
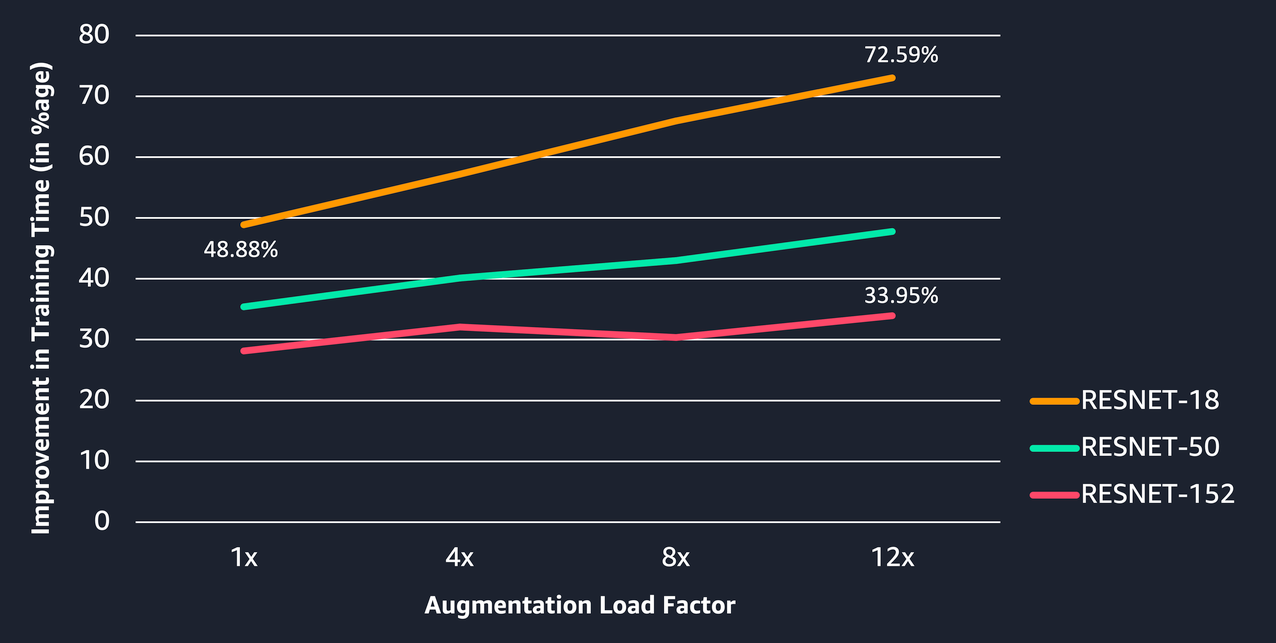
The following chart depicts the percentage improvement in training times with Trial B over Trial A across different models and augmentation loads. The improvement in training time increases with increasing augmentation load and decreases with increasing model complexity. We can observe the following:
- ResNet18 shows an increase in improvement from 48.88% to 72.59% when training with 1x and 12x augmentation load, respectively
- ResNet152 shows an improvement of 33.95% compared to ResNet18 with 72.59% for the same augmentation load of 12x
- The improvement in training time lowers with increasing model complexity because the GPU utilization is higher for training tasks and is less available for the data preprocessing task
Best practices to address data preprocessing CPU bottlenecks
Beyond the approach we discussed in this post, the following are additional best practices for addressing preprocessing CPU bottlenecks:
- Identify the right instance type – Depending on the data preprocessing load and model complexity, choosing instances with an optimal ratio of number of CPUs and GPUs can balance the load to reduce bottlenecks. This in turn accelerates training. SageMaker offers an array of instances with different CPU/GPU ratios, memory, storage types, and bandwidth to choose from. Understanding more about choosing right-sized resources and choosing the right GPU can help you select the appropriate instance.
- Balance the load among available CPUs – Assigning an optimal number of workers in a multi-CPU core system can help balance the data preprocessing load and avoid having some CPU cores always being more active than others. When increasing the number of workers, you should account for the potential bottleneck that can occur with respect to the concurrency limits of the file system.
- Optimize the training pipeline – One of the best practices is to trade off the batch size optimally. When it’s too large, there could be potential data preprocessing bottlenecks. If it’s too low, it could increase the training time and affect model convergence. Another best practice is to use low precision types wherever possible and postpone casting to higher precision to the end of the pipeline. The training framework binaries also offer low-level configurations to take full advantage of CPUs, such using the advanced vector extensions, if applicable.
- Move augmentation to the data preparation phase – Identifying operations that can be moved to the raw training data creation phase can free up CPU cycles during training. These are typically preprocessing steps that shouldn’t depend on a hyperparameter or need not be applied randomly. It’s important not to increase the size of the training data excessively because this might increase network traffic to load the data and cause an I/O bottleneck.
- Offload data preprocessing to other machines – GPUs are the most expensive resources when training models. So an approach to address the cost and performance bottleneck is to move some of the CPU heavy data preprocessing activity to dedicated workers on separate instances with only CPU cores. It’s important to consider that such a remote worker machine should have good enough network bandwidth for data transfer so as to ensure overall performance improvement.
Conclusion
Training CV models often requires complex and multi-stage data processing pipelines that include loading, decoding, cropping, resizing, and other use-case specific augmentations. They are natively run on the CPUs and often become a bottleneck, limiting the performance and scalability of training jobs.
In this post, we showed how you can use Debugger to identify resource bottlenecks and improve performance by moving data preprocessing operations to the GPU with SageMaker and NVIDIA DALI. We demonstrated a training time improvement of 72%, 37%, and 43% for ResNet18, ResNet50, and ResNet152, respectively, for a constant augmentation load.
Several factors help determine whether data preprocessing on GPU will improve performance for your CV training pipeline. These include the computational complexity of the model and the augmentation operations, current utilization of GPUs, training instance types, data format, and individual JPEG image sizes. Because the cost of a training job is dependent on the instance type and training time, the demonstrated performance improvement reduces the overall cost.
Try out the sample code used for this benchmarking experiment and the other best practices described in this post.
About the Authors
 Sayon Kumar Saha is a Machine Learning Specialist Solutions Architect at AWS, based in Berlin, Germany. Sayon focuses on helping customers across Europe, Middle East, and Africa to design and deploy ML solutions in production. He enjoys brining value to the AI/ML ecosystem by solving business problems. In his free time, he loves to travel, explore cultures and cuisines, and is passionate about photography.
Sayon Kumar Saha is a Machine Learning Specialist Solutions Architect at AWS, based in Berlin, Germany. Sayon focuses on helping customers across Europe, Middle East, and Africa to design and deploy ML solutions in production. He enjoys brining value to the AI/ML ecosystem by solving business problems. In his free time, he loves to travel, explore cultures and cuisines, and is passionate about photography.
 Hasan Poonawala is a Senior AI/ML Specialist Solutions Architect at AWS, based in London, UK. Hasan helps customers design and deploy machine learning applications in production on AWS. He has over 12 years of work experience as a data scientist, machine learning practitioner and software developer. In his spare time, Hasan loves to explore nature and spend time with friends and family.
Hasan Poonawala is a Senior AI/ML Specialist Solutions Architect at AWS, based in London, UK. Hasan helps customers design and deploy machine learning applications in production on AWS. He has over 12 years of work experience as a data scientist, machine learning practitioner and software developer. In his spare time, Hasan loves to explore nature and spend time with friends and family.