Artificial Intelligence
Achieve high performance with lowest cost for generative AI inference using AWS Inferentia2 and AWS Trainium on Amazon SageMaker
The world of artificial intelligence (AI) and machine learning (ML) has been witnessing a paradigm shift with the rise of generative AI models that can create human-like text, images, code, and audio. Compared to classical ML models, generative AI models are significantly bigger and more complex. However, their increasing complexity also comes with high costs for inference and a growing need for powerful compute resources. The high cost of inference for generative AI models can be a barrier to entry for businesses and researchers with limited resources, necessitating the need for more efficient and cost-effective solutions. Furthermore, the majority of generative AI use cases involve human interaction or real-world scenarios, necessitating hardware that can deliver low-latency performance. AWS has been innovating with purpose-built chips to address the growing need for powerful, efficient, and cost-effective compute hardware.
Today, we are excited to announce that Amazon SageMaker supports AWS Inferentia2 (ml.inf2) and AWS Trainium (ml.trn1) based SageMaker instances to host generative AI models for real-time and asynchronous inference. ml.inf2 instances are available for model deployment on SageMaker in US East (Ohio) and ml.trn1 instances in US East (N. Virginia).
You can use these instances on SageMaker to achieve high performance at a low cost for generative AI models, including large language models (LLMs), Stable Diffusion, and vision transformers. In addition, you can use Amazon SageMaker Inference Recommender to help you run load tests and evaluate the price-performance benefits of deploying your model on these instances.
You can use ml.inf2 and ml.trn1 instances to run your ML applications on SageMaker for text summarization, code generation, video and image generation, speech recognition, personalization, fraud detection, and more. You can easily get started by specifying ml.trn1 or ml.inf2 instances when configuring your SageMaker endpoint. You can use ml.trn1 and ml.inf2 compatible AWS Deep Learning Containers (DLCs) for PyTorch, TensorFlow, Hugging Face, and large model inference (LMI) to easily get started. For the full list with versions, see Available Deep Learning Containers Images.
In this post, we show the process of deploying a large language model on AWS Inferentia2 using SageMaker, without requiring any extra coding, by taking advantage of the LMI container. We use the GPT4ALL-J, a fine-tuned GPT-J 7B model that provides a chatbot style interaction.
Overview of ml.trn1 and ml.inf2 instances
ml.trn1 instances are powered by the Trainium accelerator, which is purpose built mainly for high-performance deep learning training of generative AI models, including LLMs. However, these instances also support inference workloads for models that are even larger than what fits into Inf2. The largest instance size, trn1.32xlarge instances, features 16 Trainium accelerators with 512 GB of accelerator memory in a single instance delivering up to 3.4 petaflops of FP16/BF16 compute power. 16 Trainium accelerators are connected with ultra-high-speed NeuronLinkv2 for streamlined collective communications.
ml.Inf2 instances are powered by the AWS Inferentia2 accelerator, a purpose built accelerator for inference. It delivers three times higher compute performance, up to four times higher throughput, and up to 10 times lower latency compared to first-generation AWS Inferentia. The largest instance size, Inf2.48xlarge, features 12 AWS Inferentia2 accelerators with 384 GB of accelerator memory in a single instance for a combined compute power of 2.3 petaflops for BF16/FP16. It enables you to deploy up to a 175-billion-parameter model in a single instance. Inf2 is the only inference-optimized instance to offer this interconnect, a feature that is only available in more expensive training instances. For ultra-large models that don’t fit into a single accelerator, data flows directly between accelerators with NeuronLink, bypassing the CPU completely. With NeuronLink, Inf2 supports faster distributed inference and improves throughput and latency.
Both AWS Inferentia2 and Trainium accelerators have two NeuronCores-v2, 32 GB HBM memory stacks, and dedicated collective-compute engines, which automatically optimize runtime by overlapping computation and communication when doing multi-accelerator inference. For more details on the architecture, refer to Trainium and Inferentia devices.
The following diagram shows an example architecture using AWS Inferentia2.

AWS Neuron SDK
AWS Neuron is the SDK used to run deep learning workloads on AWS Inferentia and Trainium based instances. AWS Neuron includes a deep learning compiler, runtime, and tools that are natively integrated into TensorFlow and PyTorch. With Neuron, you can develop, profile, and deploy high-performance ML workloads on ml.trn1 and ml.inf2.
The Neuron Compiler accepts ML models in various formats (TensorFlow, PyTorch, XLA HLO) and optimizes them to run on Neuron devices. The Neuron compiler is invoked within the ML framework, where ML models are sent to the compiler by the Neuron framework plugin. The resulting compiler artifact is called a NEFF file (Neuron Executable File Format) that in turn is loaded by the Neuron runtime to the Neuron device.
The Neuron runtime consists of kernel driver and C/C++ libraries, which provide APIs to access AWS Inferentia and Trainium Neuron devices. The Neuron ML frameworks plugins for TensorFlow and PyTorch use the Neuron runtime to load and run models on the NeuronCores. The Neuron runtime loads compiled deep learning models (NEFF) to the Neuron devices and is optimized for high throughput and low latency.
Host NLP models using SageMaker ml.inf2 instances
Before we dive deep into serving LLMs with transformers-neuronx, which is an open-source library to shard the model’s large weight matrices onto multiple NeuronCores, let’s briefly go through the typical deployment flow for a model that can fit onto the single NeuronCore.
Check the list of supported models to ensure the model is supported on AWS Inferentia2. Next, the model needs to be pre-compiled by the Neuron Compiler. You can use a SageMaker notebook or an Amazon Elastic Compute Cloud (Amazon EC2) instance to compile the model. You can use the SageMaker Python SDK to deploy models using popular deep learning frameworks such as PyTorch, as shown in the following code. You can deploy your model to SageMaker hosting services and get an endpoint that can be used for inference. These endpoints are fully managed and support auto scaling.
Refer to Developer Flows for more details on typical development flows of Inf2 on SageMaker with sample scripts.
Host LLMs using SageMaker ml.inf2 instances
Large language models with billions of parameters are often too big to fit on a single accelerator. This necessitates the use of model parallel techniques for hosting LLMs across multiple accelerators. Another crucial requirement for hosting LLMs is the implementation of a high-performance model-serving solution. This solution should efficiently load the model, manage partitioning, and seamlessly serve requests via HTTP endpoints.
SageMaker includes specialized deep learning containers (DLCs), libraries, and tooling for model parallelism and large model inference. For resources to get started with LMI on SageMaker, refer to Model parallelism and large model inference. SageMaker maintains DLCs with popular open-source libraries for hosting large models such as GPT, T5, OPT, BLOOM, and Stable Diffusion on AWS infrastructure. These specialized DLCs are referred to as SageMaker LMI containers.
SageMaker LMI containers use DJLServing, a model server that is integrated with the transformers-neuronx library to support tensor parallelism across NeuronCores. To learn more about how DJLServing works, refer to Deploy large models on Amazon SageMaker using DJLServing and DeepSpeed model parallel inference. The DJL model server and transformers-neuronx library serve as core components of the container, which also includes the Neuron SDK. This setup facilitates the loading of models onto AWS Inferentia2 accelerators, parallelizes the model across multiple NeuronCores, and enables serving via HTTP endpoints.
The LMI container supports loading models from an Amazon Simple Storage Service (Amazon S3) bucket or Hugging Face Hub. The default handler script loads the model, compiles and converts it into a Neuron-optimized format, and loads it. To use the LMI container to host LLMs, we have two options:
- A no-code (preferred) – This is the easiest way to deploy an LLM using an LMI container. In this method, you can use the provided default handler and just pass the model name and the parameters required in
serving.propertiesfile to load and host the model. To use the default handler, we provide theentryPointparameter asdjl_python.transformers-neuronx. - Bring your own script – In this approach, you have the option to create your own model.py file, which contains the code necessary for loading and serving the model. This file acts as an intermediary between the
DJLServingAPIs and thetransformers-neuronxAPIs. To customize the model loading process, you can provideserving.propertieswith configurable parameters. For a comprehensive list of available configurable parameters, refer to All DJL configuration options. Here is an example of a model.py file.
Runtime architecture
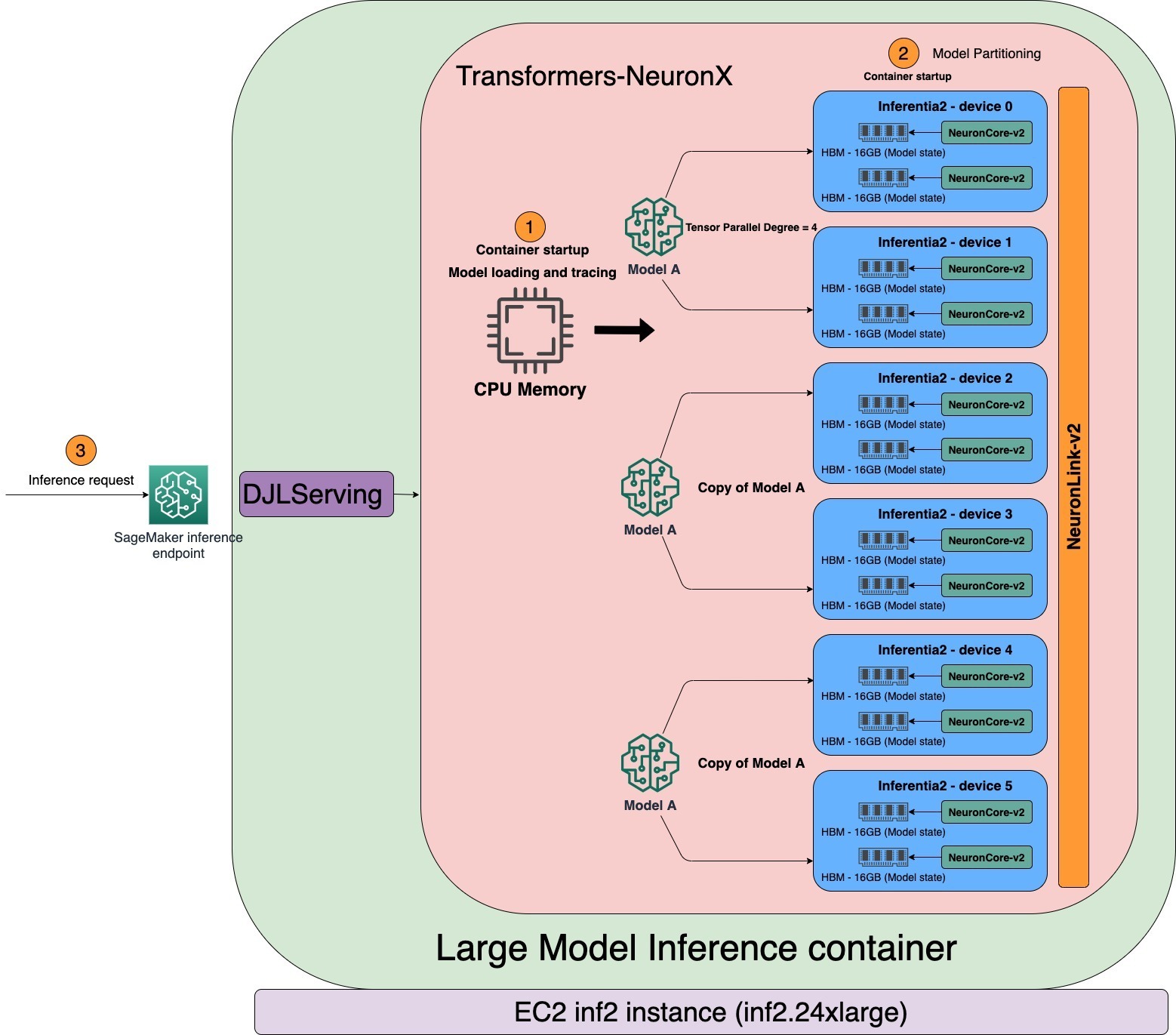
The tensor_parallel_degree property value determines the distribution of tensor parallel modules across multiple NeuronCores. For instance, inf2.24xlarge has six AWS Inferentia2 accelerators. Each AWS Inferentia2 accelerator has two NeuronCores. Each NeuronCore has a dedicated high bandwidth memory (HBM) of 16 GB storing tensor parallel modules. With a tensor parallel degree of 4, the LMI will allocate three model copies of the same model, each utilizing four NeuronCores. As shown in the following diagram, when the LMI container starts, the model will be loaded and traced first in the CPU addressable memory. When the tracing is complete, the model is partitioned across the NeuronCores based on the tensor parallel degree.
LMI uses DJLServing as its model serving stack. After the container’s health check passes in SageMaker, the container is ready to serve the inference request. DJLServing launches multiple Python processes equivalent to the TOTAL NUMBER OF NEURON CORES/TENSOR_PARALLEL_DEGREE. Each Python process contains threads in C++ equivalent to TENSOR_PARALLEL_DEGREE. Each C++ threads holds one shard of the model on one NeuronCore.
Many practitioners (Python process) tend to run inference sequentially when the server is invoked with multiple independent requests. Although it’s easier to set up, it’s usually not the best practice to utilize the accelerator’s compute power. To address this, DJLServing offers the built-in optimizations of dynamic batching to combine these independent inference requests on the server side to form a larger batch dynamically to increase throughput. All the requests reach the dynamic batcher first before entering the actual job queues to wait for inference. You can set your preferred batch sizes for dynamic batching using the batch_size settings in serving.properties. You can also configure max_batch_delay to specify the maximum delay time in the batcher to wait for other requests to join the batch based on your latency requirements. The throughput also depends on the number of model copies and the Python process groups launched in the container. As shown in the following diagram, with the tensor parallel degree set to 4, the LMI container launches three Python process groups, each holding the full copy of the model. This allows you to increase the batch size and get higher throughput.
SageMaker notebook for deploying LLMs
In this section, we provide a step-by-step walkthrough of deploying GPT4All-J, a 6-billion-parameter model that is 24 GB in FP32. GPT4All-J is a popular chatbot that has been trained on a vast variety of interaction content like word problems, dialogs, code, poems, songs, and stories. GPT4all-J is a fine-tuned GPT-J model that generates responses similar to human interactions.
The complete notebook for this example is provided on GitHub. We can use the SageMaker Python SDK to deploy the model to an Inf2 instance. We use the provided default handler to load the model. With this, we just need to provide a servings.properties file. This file has the required configurations for the DJL model server to download and host the model. We can specify the name of the Hugging Face model using the model_id parameter to download the model directly from the Hugging Face repo. Alternatively, you can download the model from Amazon S3 by providing the s3url parameter. The entryPoint parameter is configured to point to the library to load the model. For more details on djl_python.fastertransformer, refer to the GitHub code.
The tensor_parallel_degree property value determines the distribution of tensor parallel modules across multiple devices. For instance, with 12 NeuronCores and a tensor parallel degree of 4, LMI will allocate three model copies, each utilizing four NeuronCores. You can also define the precision type using the property dtype. n_position parameter defines the sum of max input and output sequence length for the model. See the following code:
Construct the tarball containing serving.properties and upload it to an S3 bucket. Although the default handler is used in this example, you can develop a model.py file for customizing the loading and serving process. If there are any packages that need installation, include them in the requirements.txt file. See the following code:
Retrieve the DJL container image and create the SageMaker model:
Next, we create the SageMaker endpoint with the model configuration defined earlier. The container downloads the model into the /tmp space because SageMaker maps the /tmp to Amazon Elastic Block Store (Amazon EBS). We need to add a volume_size parameter to ensure the /tmp directory has enough space to download and compile the model. We set container_startup_health_check_timeout to 3,600 seconds to ensure the health check starts after the model is ready. We use the ml.inf2.8xlarge instance. See the following code:
After the SageMaker endpoint has been created, we can make real-time predictions against SageMaker endpoints using the Predictor object:
Clean up
Delete the endpoints to save costs after you finish your tests:
Conclusion
In this post, we showcased the newly launched capability of SageMaker, which now supports ml.inf2 and ml.trn1 instances for hosting generative AI models. We demonstrated how to deploy GPT4ALL-J, a generative AI model, on AWS Inferentia2 using SageMaker and the LMI container, without writing any code. We also showcased how you can use DJLServing and transformers-neuronx to load a model, partition it, and serve.
Inf2 instances provide the most cost-effective way to run generative AI models on AWS. For performance details, refer to Inf2 Performance.
Check out the GitHub repo for an example notebook. Try it out and let us know if you have any questions!
About the Authors
 Vivek Gangasani is a Senior Machine Learning Solutions Architect at Amazon Web Services. He works with Machine Learning Startups to build and deploy AI/ML applications on AWS. He is currently focused on delivering solutions for MLOps, ML Inference and low-code ML. He has worked on projects in different domains, including Natural Language Processing and Computer Vision.
Vivek Gangasani is a Senior Machine Learning Solutions Architect at Amazon Web Services. He works with Machine Learning Startups to build and deploy AI/ML applications on AWS. He is currently focused on delivering solutions for MLOps, ML Inference and low-code ML. He has worked on projects in different domains, including Natural Language Processing and Computer Vision.
 Hiroshi Tokoyo is a Solutions Architect at AWS Annapurna Labs. Based in Japan, he joined Annapurna Labs even before the acquisition by AWS and has consistently helped customers with Annapurna Labs technology. His recent focus is on Machine Learning solutions based on purpose-built silicon, AWS Inferentia and Trainium.
Hiroshi Tokoyo is a Solutions Architect at AWS Annapurna Labs. Based in Japan, he joined Annapurna Labs even before the acquisition by AWS and has consistently helped customers with Annapurna Labs technology. His recent focus is on Machine Learning solutions based on purpose-built silicon, AWS Inferentia and Trainium.
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence. He focuses on Deep learning including NLP and Computer Vision domains. He helps customers achieve high performance model inference on SageMaker.
 Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.
Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.
 Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
 Alan Tan is a Senior Product Manager with SageMaker leading efforts on large model inference. He’s passionate about applying Machine Learning to the area of Analytics. Outside of work, he enjoys the outdoors.
Alan Tan is a Senior Product Manager with SageMaker leading efforts on large model inference. He’s passionate about applying Machine Learning to the area of Analytics. Outside of work, he enjoys the outdoors.
 Varun Syal is a Software Development Engineer with AWS Sagemaker working on critical customer facing features for the ML Inference platform. He is passionate about working in the Distributed Systems and AI space. In his spare time, he likes reading and gardening.
Varun Syal is a Software Development Engineer with AWS Sagemaker working on critical customer facing features for the ML Inference platform. He is passionate about working in the Distributed Systems and AI space. In his spare time, he likes reading and gardening.