Artificial Intelligence
Active learning workflow for Amazon Comprehend custom classification models – Part 1
Update Sep 2021: Amazon Comprehend has launched a suite of features for Comprehend Custom to enable continuous model improvements by giving developers the ability to version custom models, new training options for custom entity recognition models that reduce data preprocessing, ability to provide specific test sets during training, and live migration to new model endpoints. Refer to our documentation for more details.
The Amazon Comprehend custom classification API enables you to easily build custom text classification models using your business-specific labels without learning ML. For example, your customer support organization can use custom classification to automatically categorize inbound requests by problem type based on how the customer has described the issue. You can use custom classifiers to automatically label support emails with appropriate issue types, route customer phone calls to the right agents, and categorize social media posts into user segments.
For custom classification, you start by creating a training job with a ground truth dataset comprising a collection of text and corresponding category labels. When the job is complete, you have a classifier that can classify any new text into one or more named categories. When the custom classification model classifies a new unlabeled text document, it predicts what it has learned from the training data. Sometimes you may not have a training dataset with various language patterns, or once you deploy the model, you start seeing completely new data patterns. In these cases, the model may not be able to classify these new data patterns accurately. How can we ensure continuous model training to keep it up to date with new data and patterns?
Feedback loops play a pivotal role in keeping the models up to date. This feedback helps the models learn about their misclassifications and learn the right ones. This process of teaching the models continuously through feedback and deploying them is called active learning.
This is Part 1 in a two part series on Amazon Comprehend custom classification models.
|
Solution architecture
In this two-part series, we discuss an architecture pattern that allows you to build an active learning workflow for Amazon Comprehend custom classification models. The first post will cover an AWS Step Functions workflow that automates model building, selecting the best model, and deploying an endpoint of the chosen model. The second post describes a workflow comprising real-time classification, feedback pipelines, and human review workflows using Amazon Augmented AI (Amazon A2I).

Step Functions workflow
The following diagram shows the Step Functions workflow for automatic model building, endpoint creation, and deploying Amazon Comprehend custom classification models.
In the following sections, we discuss the six steps in more detail:
- Model building: Steps 1–2
- Model selection: Step 3
- Model deployment: Steps 4–6
Model building
Steps 1–2 in the workflow cover model building, which includes incorporating new data into the ground truth dataset and retraining the model. If the model is being built for the first time, the new dataset will be marked as ground truth dataset, and the Model selection step would be skipped. This new data can come from different sources, including feedback data that was human reviewed and reclassified, as discussed in Part 2 of this series. The new data is uploaded to an Amazon Simple Storage Service (Amazon S3) bucket, which starts a workflow that includes merging the new data with the ground truth dataset and starting a custom classification model training job that uses the newly merged dataset.
Model selection
Step 3 covers model selection, which includes testing the newly created model with a validation dataset, computing the test results, comparing the results of the new model with the current model in production, and finally selecting the model that performs best with respect to a chosen metric like accuracy, precision, recall, or F1 score. All these steps are orchestrated using the same Step Functions workflow after the model is built.
Model deployment
Steps 4–6 cover model deployment. If the new model outperforms the current model in production, the Step Functions workflow continues to the next step, where a new endpoint is created for the newly created custom classification model, and then updates the AWS Systems Manager Parameter Store values to this new classifier ARN and the new endpoint ARN to be used by the real-time classification API, upgrades the newly merged training dataset as the primary training dataset, and deletes the endpoint of the previous model that was in production. If the newer model doesn’t perform well in production, you can roll back to the previous model and endpoint by manually updating the Parameter Store values to refer to the earlier model and endpoint ARNs.
Deploying the AWS CloudFormation template
You can deploy this architecture using the provided AWS CloudFormation template in us-east-1.
- Choose Launch Stack:
![]()
- For Stack Name, enter the name of your CloudFormation stack.
- For StepFunctionName, enter the Step Functions name for automatic model building, endpoint creation, and deploying Amazon Comprehend custom classification models (can be left at the default value of
ComprehendModelStepFunction). - For TestThresholdParameterName, choose Accuracy, Precision, Recall, or F1score. (For this post, we leave it at the default value of F1 Score).
We use this metric to check if the newer model is better than the previous model.
- Choose Next.
- Choose Next again.
- In the Capabilities and transforms section, select all three check boxes to provide acknowledgment to AWS CloudFormation to create AWS Identity and Access Management (IAM) resources and expand the template.
- Choose Create stack.
This process might take 15 minutes or more to complete, and creates the following resources:
- Systems Manager parameters to store intermediate parameters, like the current classifier endpoint ARN
- An S3 bucket for the custom classification model training data
- An S3 bucket for the custom classification model prediction job on the test data
- Amazon DynamoDB tables for model predictions on the test data and status of custom classification prediction jobs
- AWS Lambda functions:
- StartCustomClassificationModelBuilding – Starts the custom classification model building
- GetCustomClassificationModelStatus – Gets the status of the model building stage
- StartCustomClassificationJob – Starts the prediction job using the test dataset
- GetCustomClassificationJobStatus – Gets the status of the prediction job
- CustomClassificationModelSelection – Starts the custom classification model selection stage
- StartCustomClassificationEndpointBuilding – Starts the custom classification model endpoint building stage
- GetCustomClassificationEndpointStatus – Gets the status of model endpoint building stage
- DeleteCustomClassificationEndpoint – Deletes the old model endpoint
- Step Functions to automate the workflow of building, testing, selecting, and deleting the models
- IAM roles:
- A Lambda execution role to run Amazon Comprehend custom classification jobs
- A Lambda execution role to trigger Step Functions
- A Step Functions role to trigger Lambda functions
- An Amazon Comprehend data access role to give Amazon Comprehend access to the training data in the S3 bucket
Testing
For testing this blog, you can use your own training dataset or you can download the news dataset and upload it to Amazon S3. The news dataset comprises a collection of news articles and their corresponding category labels.
- Find the S3 bucket created by the CloudFormation to store the training data. This can be found by going to the
Resourcessection of the CloudFormation and looking upComprehendInputDataS3Bucket. - On the Amazon S3 console, inside the input data bucket, create a folder named
train. - Upload the training data to the
trainfolder. - On the Step Functions console, choose the new state machine you created.
- In the Executions section, choose the latest run.

The following screenshot shows the Graph inspector view. On the Details tab, you can check that Step Functions ran successfully.
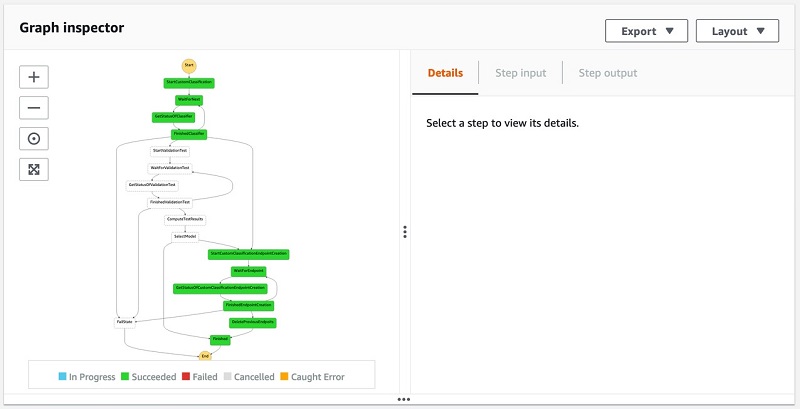
It takes approximately 1 hour for the Step Functions state machine to complete.
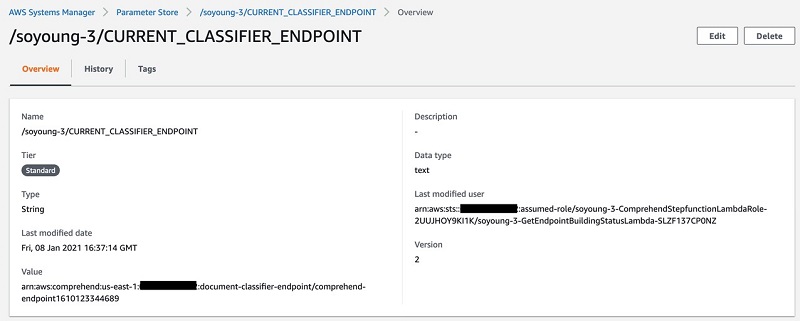
- After Step Functions has successfully ran, on the Systems Manager console, in the navigation pane, under Application Management, choose Parameter Store.
You can check the updated classifier and endpoint from the Parameter Store.
Cleaning up
To avoid incurring any charges in the future, delete the CloudFormation stack. This removes all the resources you created as part of this post.
Conclusion
Active learning in custom classification models ensures that your models are kept up to date with new data and patterns. This two-part series provides you with a reference architecture to build an active learning workflow comprised of real-time classification APIs, feedback loops, a human review workflow, model building, model selection, and model deployment. For more information about the feedback loops and human review workflow, see the second part of this blog series, Active learning workflow for Amazon Comprehend custom classification models – Part 2.
For more information about custom classification in Amazon Comprehend, see Custom Classification. You can discover other Amazon Comprehend features and get inspiration from other AWS blog posts about how to use Amazon Comprehend beyond classification.
About the Authors
 Shanthan Kesharaju is a Senior Architect in the AWS ProServe team. He helps our customers with AI/ML strategy, architecture, and developing products with a purpose. Shanthan has an MBA in Marketing from Duke University and an MS in Management Information Systems from Oklahoma State University.
Shanthan Kesharaju is a Senior Architect in the AWS ProServe team. He helps our customers with AI/ML strategy, architecture, and developing products with a purpose. Shanthan has an MBA in Marketing from Duke University and an MS in Management Information Systems from Oklahoma State University.
 Marty Jiang is a Conversational AI Consultant with AWS Professional Services. Outside of work, he loves spending time outdoors with his family and exploring new technologies.
Marty Jiang is a Conversational AI Consultant with AWS Professional Services. Outside of work, he loves spending time outdoors with his family and exploring new technologies.
 So Young Yoon is a Conversation A.I. Architect at AWS Professional Services where she works with customers across multiple industries to develop specialized conversational assistants which have helped these customers provide their users faster and accurate information through natural language. Soyoung has M.S. and B.S. in Electrical and Computer Engineering from Carnegie Mellon University.
So Young Yoon is a Conversation A.I. Architect at AWS Professional Services where she works with customers across multiple industries to develop specialized conversational assistants which have helped these customers provide their users faster and accurate information through natural language. Soyoung has M.S. and B.S. in Electrical and Computer Engineering from Carnegie Mellon University.