Artificial Intelligence
Announcing model improvements and lower annotation limits for Amazon Comprehend custom entity recognition
Update August 3, 2022: Minimum requirements for training entity recognizers have been further reduced. You can now build a custom entity recognition model with as few as three documents and 25 annotations per entity type. Additional details available in the Amazon Comprehend Guidelines and quotas webpage and in the blog post announcing the limit reduction.
Amazon Comprehend is a natural language processing (NLP) service that provides APIs to extract key phrases, contextual entities, events, sentiment from unstructured text, and more. Entities refer to things in your document such as people, places, organizations, credit card numbers, and so on. But what if you want to add entity types unique to your business, like proprietary part codes or industry-specific terms? Custom entity recognition (CER) in Amazon Comprehend enables you to train models with entities that are unique to your business in just a few easy steps. You can identify almost any kind of entity, simply by providing a sufficient number of details to train your model effectively.
Training an entity recognizer from the ground up requires extensive knowledge of machine learning (ML) and a complex process for model optimization. Amazon Comprehend makes this easy for you using a technique called transfer learning to help build your custom model. Internally, Amazon Comprehend uses base models that have been trained on data collected by Amazon Comprehend and optimized for the purposes of entity recognition. With this in place, all you need to supply is the data. ML model accuracy is typically dependent on both the volume and quality of data. Getting good quality annotation data is a laborious process.
Until today, you could train an Amazon Comprehend custom entity recognizer with only 1,000 documents and 200 annotations per entity. Today, we’re announcing that we have improved underlying models for the Amazon Comprehend custom entity API by reducing the minimum requirements to train the model. Now, with as few as 250 documents and 100 annotations per entity (also referred to as shots), you can train Amazon Comprehend CER models to predict entities with greater accuracy. To take advantage of the updated performance offered by the new CER model framework, you can simply retrain and deploy improved models.
To illustrate the model improvements, we compare the result of previous models with that of the new release. We selected a diverse set of entity recognition datasets across different domains and languages from the open-source domain to showcase the model improvements. In this post, we walk you through the results from our training and inference process between the previous CER model version and the new CER model.
Datasets
When you train an Amazon Comprehend CER model, you provide the entities that you want the custom model to recognize, and the documents with text containing these entities. You can train Amazon Comprehend CER models using entity lists or annotations. Entity lists are CSV files that contain the text (a word or words) of an entity example from the training document along with a label, which is the entity type that the text is categorized as. With annotations, you can provide the positional offset of entities in a sentence along with the entity type being represented. When you use the entire sentence, you’re providing the contextual reference for the entities, which increases the accuracy of the model you’re training.
We selected the annotations option for labeling our entities because the datasets we selected already contained the annotations for each of the entity types represented. In this section, we discuss the datasets we selected and what they describe.
CoNLL
The Conference on Computational Natural Language Learning (CoNLL) provides datasets for language-independent (doesn’t use language-specific resources for performing the task) named entity recognition with entities provided in English, Spanish, and German. Four types of named entities are provided in the dataset: persons, locations, organizations, and names of miscellaneous entities that don’t belong to the previous three types.
We used the CoNLL-2003 dataset for English, and the CoNLL-2002 dataset for Spanish languages for our entity recognition training. We ran some basic transformations to convert the annotations data to a format that is required by Amazon Comprehend CER. We converted the entity types from their semantic notation to actual words they represent, such as person, organization, location, and miscellaneous.
SNIPS
The SNIPS dataset was created in 2017 as part of benchmarking tests for natural language understanding (NLU) by Snips. The results from these tests are available in the 2018 paper “Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces” by Coucke, et al. We used the GetWeather and the AddToPlaylist datasets for our experiments. The entities for the GetWeather dataset we considered are timerange, city, state, condition_description, country, and condition_temperature. For AddToPlaylist, we considered the entities artist, playlist_owner, playlist, music_item, and entity_name.
Sampling configuration
The following table represents the dataset configuration for our tests. Each row represents an Amazon Comprehend CER model that was trained, deployed, and used for entity prediction with our test dataset.
| Dataset | Published year | Language | Number of documents sampled for training | Number of entities sampled | Number of annotations per entity (shots) | Number of documents sampled for blind test inference (never seen during training) |
| SNIPS-AddToPlaylist | 2017 | English | 254 | 5 | artist – 101
playlist_owner – 148 playlist – 254 music_item – 100 entity_name – 100 |
100 |
| SNIPS-GetWeather | 2017 | English | 600 | 6 | timeRange – 281
city – 211 state – 111 condition_description – 121 country – 117 condition_temperature – 115 |
200 |
| SNIPS-GetWeather | 2017 | English | 1000 | 6 | timeRange -544
city – 428 state -248 condition_description -241 country -230 condition_temperature – 228 |
200 |
| SNIPS-GetWeather | 2017 | English | 2000 | 6 | timeRange -939
city -770 state – 436 condition_description – 401 country – 451 condition_temperature – 431 |
200 |
| CoNLL | 2003 | English | 350 | 3 | Location – 183
Organization – 111 Person – 229 |
200 |
| CoNLL | 2003 | English | 600 | 3 | Location – 384
Organization – 210 Person – 422 |
200 |
| CoNLL | 2003 | English | 1000 | 4 | Location – 581
Miscellaneous – 185 Organization – 375 Person – 658 |
200 |
| CoNLL | 2003 | English | 2000 | 4 | Location – 1133
Miscellaneous – 499 Organization – 696 Person – 1131 |
200 |
| CoNLL | 2002 | Spanish | 380 | 4 | Location – 208
Miscellaneous – 103 Organization – 404 Person – 207 |
200 |
| CoNLL | 2002 | Spanish | 600 | 4 | Location – 433
Miscellaneous – 220 Organization – 746 Person – 436 |
200 |
| CoNLL | 2002 | Spanish | 1000 | 4 | Location – 578
Miscellaneous – 266 Organization – 929 Person – 538 |
200 |
| CoNLL | 2002 | Spanish | 2000 | 4 | Location – 1184
Miscellaneous – 490 Organization – 1726 Person – 945 |
200 |
For more details on how to format data to create annotations and entity lists for Amazon Comprehend CER, see Training Custom Entity Recognizers. We created a benchmarking approach based on the sampling configuration for our tests, and we discuss the results in the following sections.
Benchmarking process
As shown in the sampling configuration in the preceding section, we trained a total of 12 models, with four models each for CoNLL English and Spanish datasets with varying document and annotation configurations, three models for the SNIPS-GetWeather dataset, again with varying document and annotation configurations, and one model with the SNIPS-AddToPlaylist dataset, primarily to test the new minimums of 250 documents and 100 annotations per entity.
Two inputs are required to train an Amazon CER model: entity representations and the documents containing these entities. For an example of how to train your own CER model, refer to Setting up human review of your NLP-based entity recognition models with Amazon SageMaker Ground Truth, Amazon Comprehend, and Amazon A2I. We measure the accuracy of our models using metrics such as F1 score, precision, and recall for the test set at training and the blind test set at inference. We run subsequent inference on these models using a blind test dataset of documents that we set aside from our original datasets.
Precision indicates how many times the model makes a correct entity identification compared to the number of attempted identifications. Recall indicates how many times the model makes a correct entity identification compared to the number of instances of that the entity is actually present, as defined by the total number of correct identifications (true positives) and missed identifications (false negatives). F1 score indicates a combination of the precision and recall metrics, which measures the overall accuracy of the model for custom entity recognition. To learn more about these metrics, refer to Custom Entity Recognizer Metrics.
Amazon Comprehend CER provides support for both real-time endpoints and batch inference requirements. We used the asynchronous batch inference API for our experiments. Finally, we calculated the F1 score, precision, and recall for the inference by comparing what the model predicted with what was originally annotated for the test documents. The metrics are calculated by doing a strict match for the span offsets, and a partial match isn’t considered nor given partial credit.
Results
The following tables document the results from our experiments we ran using the sampling configuration and the benchmarking process we explained previously.
Previous limits vs. new limits
The limits have reduced from 1,000 documents and 200 annotations per entity for CER training in the previous model to 250 documents and 100 annotations per entity in the improved model.
The following table shows the absolute improvement in F1 scores measured at training, between the old and new models. The new model improves the accuracy of your entity recognition models even when you have a lower count of training documents.
| Model | Previous F1 during training | New F1 during training | F1 point gains |
| CoNLL-2003-EN-600 | 85 | 96.2 | 11.2 |
| CoNLL-2003-EN-1000 | 80.8 | 91.5 | 10.7 |
| CoNLL-2003-EN-2000 | 92.2 | 94.1 | 1.9 |
| CoNLL-2003-ES-600 | 81.3 | 86.5 | 5.2 |
| CoNLL-2003-ES-1000 | 85.3 | 92.7 | 7.4 |
| CoNLL-2003-ES-2000 | 86.1 | 87.2 | 1.1 |
| SNIPS-Weather-600 | 74.7 | 92.1 | 17.4 |
| SNIPS-Weather-1000 | 93.1 | 94.8 | 1.7 |
| SNIPS-Weather-2000 | 92.1 | 95.9 | 3.8 |
Next, we report the evaluation on a blind test set that was split before the training process from the dataset.
| Previous model with at least 200 annotations | New (improved) model with approximately 100 annotations | |||||
| Dataset | Number of entities | F1 | Blind test set F1 | F1 | Blind test set F1 | F1 point gains on blind test set |
| CoNLL-2003 – English | 3 | 84.9 | 79.4 | 90.2 | 87.9 | 8.5 |
| CoNLL-2003 – Spanish | 4 | 85.8 | 76.3 | 90.4 | 81.8 | 5.5 |
| SNIPS-Weather | 6 | 74.74 | 80.64 | 92.14 | 93.6 | 12.96 |
Overall, we observe an improvement in F1 scores with the new model even with half the number of annotations provided, as seen in the preceding table.
Continued improvement with more data
In addition to the improved F1 scores at lower limits, we noticed a trend where the new model’s accuracy measured with the blind test dataset continued to improve as we trained with increased annotations. For this test, we considered the SNIPS GetWeather and AddToPlaylist datasets.
The following graph shows a distribution of absolute blind test F1 scores for models trained with different datasets and annotation counts.

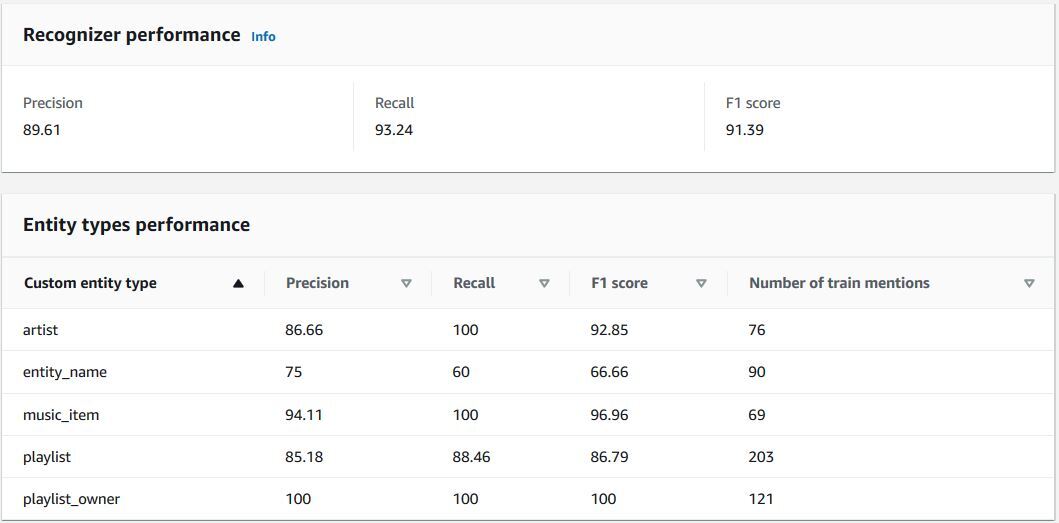
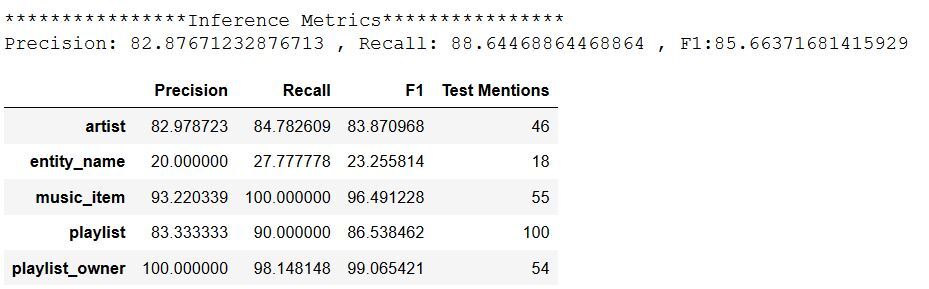
We generated the following metrics during training and inference for the SNIPS-AddToPlaylist model trained with 250 documents in the new Amazon Comprehend CER model.
SNIPS-AddToPlaylist metrics at training time
SNIPS-AddToPlaylist inference metrics with blind test dataset
Conclusion
In our experiments with the model improvements in Amazon Comprehend CER, we observe accuracy improvements with fewer annotations and lower document volumes. Now, we consistently see increased accuracy across multiple datasets even with half the number of data samples. We continue to see improvements to the F1 score as we trained models with different dataset sampling configurations, including multi-lingual models. With this updated model, Amazon Comprehend makes it easy to train custom entity recognition models. Limits have been lowered to 100 annotations per entity and 250 documents for training while offering improved accuracy with your models. You can start training custom entity models on the Amazon Comprehend console or through the API.
About the Authors
 Prem Ranga is an Enterprise Solutions Architect based out of Houston, Texas. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an Autonomous Vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
Prem Ranga is an Enterprise Solutions Architect based out of Houston, Texas. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an Autonomous Vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
 Chethan Krishna is a Senior Partner Solutions Architect in India. He works with Strategic AWS Partners for establishing a robust cloud competency, adopting AWS best practices and solving customer challenges. He is a builder and enjoys experimenting with AI/ML, IoT and Analytics.
Chethan Krishna is a Senior Partner Solutions Architect in India. He works with Strategic AWS Partners for establishing a robust cloud competency, adopting AWS best practices and solving customer challenges. He is a builder and enjoys experimenting with AI/ML, IoT and Analytics.
 Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She helps customers adopt machine learning on a large scale. She is passionate about NLP and ML Explainability areas in AI/ML.
Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She helps customers adopt machine learning on a large scale. She is passionate about NLP and ML Explainability areas in AI/ML.