Artificial Intelligence
Amazon Comprehend announces lower annotation limits for custom entity recognition
Amazon Comprehend is a natural-language processing (NLP) service you can use to automatically extract entities, key phrases, language, sentiments, and other insights from documents. For example, you can immediately start detecting entities such as people, places, commercial items, dates, and quantities via the Amazon Comprehend console, AWS Command Line Interface, or Amazon Comprehend APIs. In addition, if you need to extract entities that aren’t part of the Amazon Comprehend built-in entity types, you can create a custom entity recognition model (also known as custom entity recognizer) to extract terms that are more relevant for your specific use case, like names of items from a catalog of products, domain-specific identifiers, and so on. Creating an accurate entity recognizer on your own using machine learning libraries and frameworks can be a complex and time-consuming process. Amazon Comprehend simplifies your model training work significantly. All you need to do is load your dataset of documents and annotations, and use the Amazon Comprehend console, AWS CLI, or APIs to create the model.
To train a custom entity recognizer, you can provide training data to Amazon Comprehend as annotations or entity lists. In the first case, you provide a collection of documents and a file with annotations that specify the location where entities occur within the set of documents. Alternatively, with entity lists, you provide a list of entities with their corresponding entity type label, and a set of unannotated documents in which you expect your entities to be present. Both approaches can be used to train a successful custom entity recognition model; however, there are situations in which one method may be a better choice. For example, when the meaning of specific entities could be ambiguous and context-dependent, providing annotations is recommended because this might help you create an Amazon Comprehend model that is capable of better using context when extracting entities.
Annotating documents can require quite a lot of effort and time, especially if you consider that both the quality and quantity of annotations have an impact on the resulting entity recognition model. Imprecise or too few annotations can lead to poor results. To help you set up a process for acquiring annotations, we provide tools such as Amazon SageMaker Ground Truth, which you can use to annotate your documents more quickly and generate an augmented manifest annotations file. However, even if you use Ground Truth, you still need to make sure that your training dataset is large enough to successfully build your entity recognizer.
Until today, to start training an Amazon Comprehend custom entity recognizer, you had to provide a collection of at least 250 documents and a minimum of 100 annotations per entity type. Today, we’re announcing that, thanks to recent improvements in the models underlying Amazon Comprehend, we’ve reduced the minimum requirements for training a recognizer with plain text CSV annotation files. You can now build a custom entity recognition model with as few as three documents and 25 annotations per entity type. You can find further details about new service limits in Guidelines and quotas.
To showcase how this reduction can help you getting started with the creation of a custom entity recognizer, we ran some tests on a few open-source datasets and collected performance metrics. In this post, we walk you through the benchmarking process and the results we obtained while working on subsampled datasets.
Dataset preparation
In this post, we explain how we trained an Amazon Comprehend custom entity recognizer using annotated documents. In general, annotations can be provided as a CSV file, an augmented manifest file generated by Ground Truth, or a PDF file. Our focus is on CSV plain text annotations, because this is the type of annotation impacted by the new minimum requirements. CSV files should have the following structure:
The relevant fields are as follows:
- File – The name of the file containing the documents
- Line – The number of the line containing the entity, starting with line 0
- Begin Offset – The character offset in the input text (relative to the beginning of the line) that shows where the entity begins, considering that the first character is at position 0
- End Offset – The character offset in the input text that shows where the entity ends
- Type – The name of the entity type you want to define
Additionally, when using this approach, you have to provide a collection of training documents as .txt files with one document per line, or one document per file.
For our tests, we used the SNIPS Natural Language Understanding benchmark, a dataset of crowdsourced utterances distributed among seven user intents (AddToPlaylist, BookRestaurant, GetWeather, PlayMusic, RateBook, SearchCreativeWork, SearchScreeningEvent). The dataset was published in 2018 in the context of the paper Snips Voice Platform: an embedded Spoken Language Understanding system for private-by-design voice interfaces by Coucke, et al.
The SNIPS dataset is made of a collection of JSON files condensing both annotations and raw text files. The following is a snippet from the dataset:
Before creating our entity recognizer, we transformed the SNIPS annotations and raw text files into a CSV annotations file and a .txt documents file.
The following is an excerpt from our annotations.csv file:
The following is an excerpt from our documents.txt file:
Sampling configuration and benchmarking process
For our experiments, we focused on a subset of entity types from the SNIPS dataset:
- BookRestaurant – Entity types:
spatial_relation,poi,party_size_number,restaurant_name,city,timeRange,restaurant_type,served_dish,party_size_description,country,facility,state,sort,cuisine - GetWeather – Entity types:
condition_temperature,current_location,geographic_poi,timeRange,state,spatial_relation,condition_description,city,country - PlayMusic – Entity types:
track,artist,music_item,service,genre,sort,playlist,album,year
Moreover, we subsampled each dataset to obtain different configurations in terms of number of documents sampled for training and number of annotations per entity (also known as shots). This was done by using a custom script designed to create subsampled datasets in which each entity type appears at least k times, within a minimum of n documents.
Each model was trained using a specific subsample of the training datasets; the nine model configurations are illustrated in the following table.
| Subsampled dataset name | Number of documents sampled for training | Number of documents sampled for testing | Average number of annotations per entity type (shots) |
snips-BookRestaurant-subsample-A |
132 | 17 | 33 |
snips-BookRestaurant-subsample-B |
257 | 33 | 64 |
snips-BookRestaurant-subsample-C |
508 | 64 | 128 |
snips-GetWeather-subsample-A |
91 | 12 | 25 |
snips-GetWeather-subsample-B |
185 | 24 | 49 |
snips-GetWeather-subsample-C |
361 | 46 | 95 |
snips-PlayMusic-subsample-A |
130 | 17 | 30 |
snips-PlayMusic-subsample-B |
254 | 32 | 60 |
snips-PlayMusic-subsample-C |
505 | 64 | 119 |
To measure the accuracy of our models, we collected evaluation metrics that Amazon Comprehend automatically computes when training an entity recognizer:
- Precision – This indicates the fraction of entities detected by the recognizer that are correctly identified and labeled. From a different perspective, precision can be defined as tp / (tp + fp), where tp is the number of true positives (correct identifications) and fp is the number of false positives (incorrect identifications).
- Recall – This indicates the fraction of entities present in the documents that are correctly identified and labeled. It’s calculated as tp / (tp + fn), where tp is the number of true positives and fn is the number of false negatives (missed identifications).
- F1 score – This is a combination of the precision and recall metrics, which measures the overall accuracy of the model. The F1 score is the harmonic mean of the precision and recall metrics, and is calculated as 2 * Precision * Recall / (Precision + Recall).
For comparing performance of our entity recognizers, we focus on F1 scores.
Considering that, given a dataset and a subsample size (in terms of number of documents and shots), you can generate different subsamples, we generated 10 subsamples for each one of the nine configurations, trained the entity recognition models, collected performance metrics, and averaged them using micro-averaging. This allowed us to get more stable results, especially for few-shot subsamples.
Results
The following table shows the micro-averaged F1 scores computed on performance metrics returned by Amazon Comprehend after training each entity recognizer.
| Subsampled dataset name | Entity recognizer micro-averaged F1 score (%) |
snips-BookRestaurant-subsample-A |
86.89 |
snips-BookRestaurant-subsample-B |
90.18 |
snips-BookRestaurant-subsample-C |
92.84 |
snips-GetWeather-subsample-A |
84.73 |
snips-GetWeather-subsample-B |
93.27 |
snips-GetWeather-subsample-C |
93.43 |
snips-PlayMusic-subsample-A |
80.61 |
snips-PlayMusic-subsample-B |
81.80 |
snips-PlayMusic-subsample-C |
85.04 |
The following column chart shows the distribution of F1 scores for the nine configurations we trained as described in the previous section.
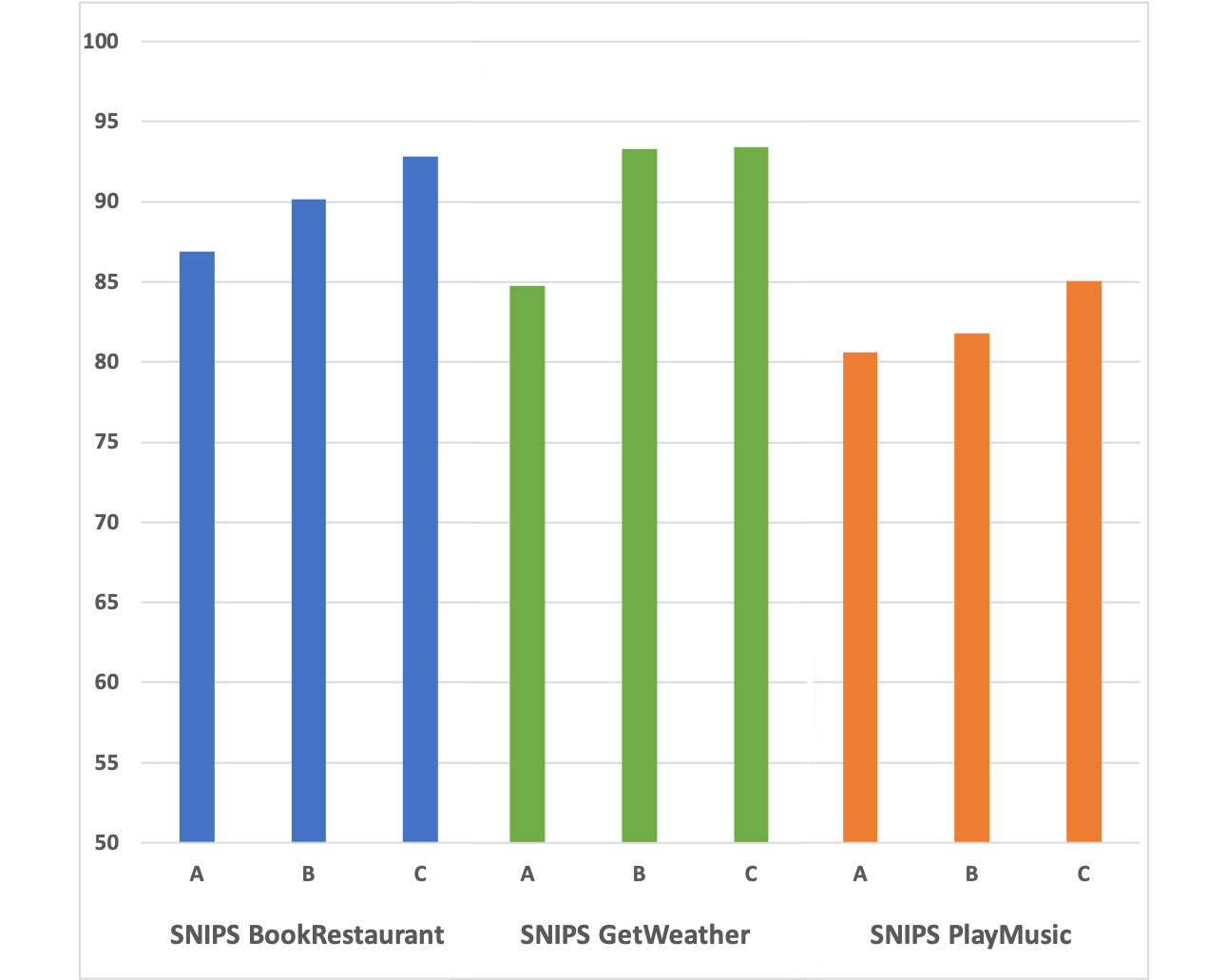
We can observe that we were able to successfully train custom entity recognition models even with as few as 25 annotations per entity type. If we focus on the three smallest subsampled datasets (snips-BookRestaurant-subsample-A, snips-GetWeather-subsample-A, and snips-PlayMusic-subsample-A), we see that, on average, we were able to achieve a F1 score of 84%, which is a pretty good result considering the limited number of documents and annotations we used. If we want to improve the performance of our model, we can collect additional documents and annotations and train a new model with more data. For example, with medium-sized subsamples (snips-BookRestaurant-subsample-B, snips-GetWeather-subsample-B, and snips-PlayMusic-subsample-B), which contain twice as many documents and annotations, we obtained on average a F1 score of 88% (5% improvement with respect to subsample-A datasets). Finally, larger subsampled datasets (snips-BookRestaurant-subsample-C, snips-GetWeather-subsample-C, and snips-PlayMusic-subsample-C), which contain even more annotated data (approximately four times the number of documents and annotations used for subsample-A datasets), provided a further 2% improvement, raising the average F1 score to 90%.
Conclusion
In this post, we announced a reduction of the minimum requirements for training a custom entity recognizer with Amazon Comprehend, and ran some benchmarks on open-source datasets to show how this reduction can help you get started. Starting today, you can create an entity recognition model with as few as 25 annotations per entity type (instead of 100), and at least three documents (instead of 250). With this announcement, we’re lowering the barrier to entry for users interested in using Amazon Comprehend custom entity recognition technology. You can now start running your experiments with a very small collection of annotated documents, analyze preliminary results, and iterate by including additional annotations and documents if you need a more accurate entity recognition model for your use case.
To learn more and get started with a custom entity recognizer, refer to Custom entity recognition.
Special thanks to my colleagues Jyoti Bansal and Jie Ma for their precious help with data preparation and benchmarking.
About the author
 Luca Guida is a Solutions Architect at AWS; he is based in Milan and supports Italian ISVs in their cloud journey. With an academic background in computer science and engineering, he started developing his AI/ML passion at university. As a member of the natural language processing (NLP) community within AWS, Luca helps customers be successful while adopting AI/ML services.
Luca Guida is a Solutions Architect at AWS; he is based in Milan and supports Italian ISVs in their cloud journey. With an academic background in computer science and engineering, he started developing his AI/ML passion at university. As a member of the natural language processing (NLP) community within AWS, Luca helps customers be successful while adopting AI/ML services.