Artificial Intelligence
Automate digitization of transactional documents with human oversight using Amazon Textract and Amazon A2I
In this post, we present a solution for digitizing transactional documents using Amazon Textract and incorporate a human review using Amazon Augmented AI (A2I). You can find the solution source at our GitHub repository.
Organizations must frequently process scanned transactional documents with structured text so they can perform operations such as fraud detection or financial approvals. Some common examples of transactional documents that contain tabular data include bank statements, invoices, and bills of materials. Manually extracting data from such documents is expensive, time-consuming, and often requires a significant investment in training a specialized workforce. With the architecture outlined in this post, you can digitize tabular data from even low-quality scanned documents and achieve a high degree of accuracy.
Significant strides have been made with machine learning (ML)-based algorithms to increase accuracy and reliability when processing scanned text documents. These algorithms often match human-level performance in recognizing text and extracting content. Amazon Textract is a fully managed service that automatically extracts printed text, handwriting, and other data from scanned documents. Additionally, Amazon Textract can automatically identify and extract forms and tables from scanned documents.
Companies dealing with complex, varying, and sensitive documents often need human oversight to ensure accuracy, consistency, and compliance of the extracted data. As human reviewers provide input, you can fine-tune AI models to capture subtle nuances of a particular business process. Amazon A2I is an ML service that makes it easy to build the workflows required for human review. Amazon A2I removes the undifferentiated heavy lifting associated with building human review systems or managing a large number of human reviewers, and provides a unified and secure experience to your workforce.
Extracting transactional data from scanned documents, such as a list of debit card transactions on a bank statement, poses a unique set of challenges. Combining artificial intelligence with human review provides a practical approach to overcome these hurdles. An integrated solution that combines Amazon Textract and Amazon A2I is one such compelling example.

Consumers routinely use their smartphones to scan and upload transactional documents. Depending on the overall scan quality, including lighting conditions, skewed perspective, and less-than-adequate image resolution, it’s not uncommon to see suboptimal accuracy when these documents are processed using computer vision (CV) techniques. At the same time, handling scanned documents using manual labor can result in increased processing costs and processing time, and can limit your ability to scale up the volume of documents a pipeline can handle.
Solution overview
The following diagram illustrates the workflow of our solution:

Our end-to-end workflow performs the following steps:
- Extracts tables from scanned source documents.
- Applies custom business rules when extracting data from the tables.
- Selectively escalates challenging documents for human review.
- Performs postprocessing on the extracted data.
- Stores the results.
A custom user interface built with ReactJS is provided to human reviewers to intuitively and efficiently review and correct issues in the documents when Amazon Textract provides a low-confidence extraction score, for example when text is obscured, fuzzy, or otherwise unclear.
Our reference solution uses a highly resilient pipeline, as detailed in the following diagram, to coordinate the various document processing stages.
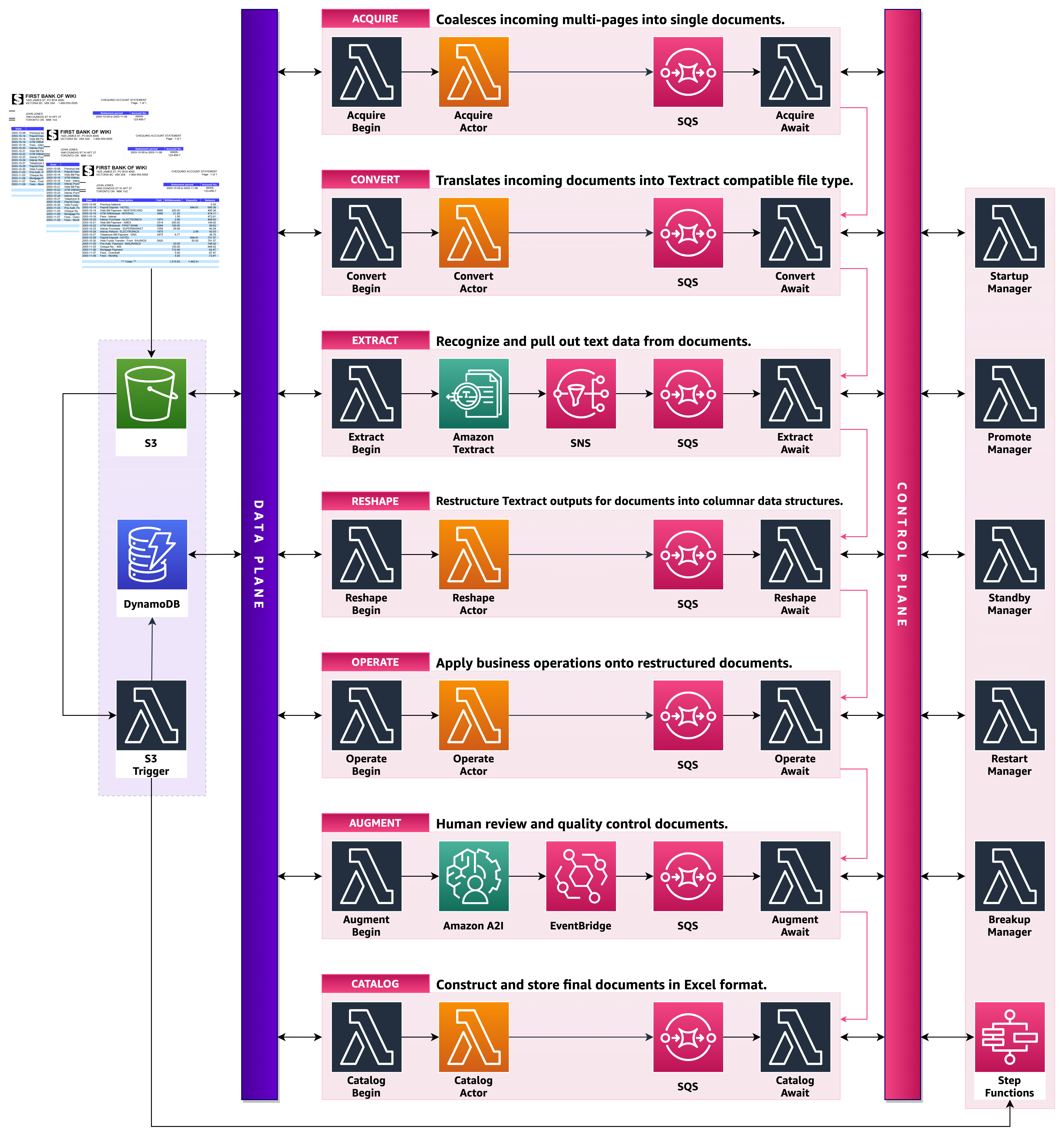
The solution incorporates several architectural best practices:
- Batch processing – When possible, the solution should collect multiple documents and perform batch operations so we can optimize throughput and use resources more efficiently. For example, calling a custom AI model to run inference one time for a group of documents, as opposed to calling the model for each document individually. The design of our solution should enable batching when appropriate.
- Priority adjustment – When the volume of documents in the queue increases and the solution is no longer able to process them in a timely manner, we need a way to indicate that certain documents are higher priority, and therefore must be processed ahead of other documents in the queue.
- Auto scaling – The solution should be capable of scaling up and down dynamically. Many document processing workflows need to support the cyclical nature of demand. We should design the solution such that it can seamlessly scale up to handle spikes in load and scale back down when the load subsides.
- Self-regulation – The solution should be capable of gracefully handling external service outages and rate limitations.
Document processing stages
In this section, we walk you through the details of each stage in the document processing workflow:
- Acquisition
- Conversion
- Extraction
- Reshaping
- Custom business operations
- Augmentation
- Cataloging
Acquisition
The first stage of the pipeline acquires input documents from Amazon Simple Storage Service (Amazon S3). In this stage, we store initial document information in an Amazon DynamoDB table after receiving an S3 event notification via Amazon Simple Queue Service (Amazon SQS). We use this table record to track the progression of this document across the entire pipeline.
The order of priority for each document is determined by sorting the alphanumeric input key prefix in the document path. For example, a document stored with key acquire/p0/doc.pdf results in priority p0, and takes precedence over another document stored with key acquire/p1/doc.pdf (resulting in priority p1). Documents with no priority indicator in the key are processed at the end.
Conversion
Documents acquired from the previous stage are converted into PDF format, so we can provide a consistent data format for the rest of the pipeline. This allows us to batch multiple pages of a related document.
Extraction
PDF documents are sent to Amazon Textract to perform optical character recognition (OCR). Results from Amazon Textract are stored as JSON in a folder in Amazon S3.
Reshaping
Amazon Textract provides detailed information from the processed document, including raw text, key-value pairs, and tables. A significant amount of additional metadata identifies the location and relationship between the detected entity blocks. The transactional data is selected for further processing at this stage.
Custom business operations
Custom business rules are applied to the reshaped output containing information about tables in the document. Custom rules may include table format detection (such as detecting that a table contains checking transactions) or column validation (such as verifying that a product code column only contains valid codes).
Augmentation
Human annotators use Amazon A2I to review the document and augment it with any information that was missed. The review includes analyzing each table in the document for errors such as incorrect table types, field headers, and individual cell text that was incorrectly predicted. Confidence scores provided by the extraction stage are displayed in the UI to help human reviewers locate less accurate predictions easily. The following screenshot shows the custom UI used for this purpose.

Our solution uses a private human review workforce consisting of in-house annotators. This is an ideal option when dealing with sensitive documents or documents that require highly specialized domain knowledge. Amazon A2I also supports human review workforces through Amazon Mechanical Turk and Amazon’s authorized data labeling partners.
Cataloging
Documents that pass human review are cataloged into an Excel workbook so your business teams can easily consume them. The workbook contains each table detected and processed in the source document in their respective sheet, which is labeled with table type and page number. These Excel files are stored in a folder in Amazon S3 for consumption by business applications, for example, performing fraud detection using ML techniques.
Deploy the solution
This reference solution is available on GitHub, and you can deploy it with the AWS Cloud Development Kit (AWS CDK). The AWS CDK uses the familiarity and expressive power of programming languages for modeling your applications. It provides high-level components called constructs that preconfigure cloud resources with proven defaults, so you can build cloud applications with ease.
For instructions on deploying the cloud application, refer to the README file in the GitHub repo.
Solution demonstration
The following video walks you through a demonstration of the solution.
Conclusion
This post showed how you can build a custom digitization solution to process transactional documents with Amazon Textract and Amazon A2I. We automated and augmented input manifests, and enforced custom business rules. We also provided an intuitive user interface for human workforces to review data with low confidence scores, make necessary adjustments, and use feedback to improve the underlying ML models. The ability to use a custom frontend framework like ReactJS allows us to create modern web applications that serve our precise needs, especially when using public, private, or third-party data labeling workforces.
For more information about Amazon Textract and Amazon A2I, see Using Amazon Augmented AI to Add Human Review to Amazon Textract Output. For video presentations, sample Jupyter notebooks, or information about use cases like document processing, content moderation, sentiment analysis, text translation, and more, see Amazon Augmented AI Resources.
About the Team
The Amazon ML Solutions Lab pairs your organization with ML experts to help you identify and build ML solutions to address your organization’s highest return-on-investment ML opportunities. Through discovery workshops and ideation sessions, the ML Solutions Lab “works backward” from your business problems to deliver a roadmap of prioritized ML use cases with an implementation plan to address them. Our ML scientists design and develop advanced ML models in areas such as computer vision, speech processing, and natural language processing to solve customers’ problems, including solutions requiring human review.
About the Authors
 Pri Nonis is a Deep Learning Architect at the Amazon ML Solutions Lab, where he works with customers across various verticals, and helps them accelerate their cloud migration journey, and to solve their ML problems using state-of-the-art solutions and technologies.
Pri Nonis is a Deep Learning Architect at the Amazon ML Solutions Lab, where he works with customers across various verticals, and helps them accelerate their cloud migration journey, and to solve their ML problems using state-of-the-art solutions and technologies.
 Dan Noble is a Software Development Engineer at Amazon where he helps build delightful user experiences. In his spare time, he enjoys reading, exercising, and having adventures with his family.
Dan Noble is a Software Development Engineer at Amazon where he helps build delightful user experiences. In his spare time, he enjoys reading, exercising, and having adventures with his family.
 Jae Sung Jang is a Software Development Engineer. His passion lies with automating manual process using AI Solutions and Orchestration technologies to ensure business execution.
Jae Sung Jang is a Software Development Engineer. His passion lies with automating manual process using AI Solutions and Orchestration technologies to ensure business execution.
 Jeremy Feltracco is a Software Development Engineer with the Amazon ML Solutions Lab at Amazon Web Services. He uses his background in computer vision, robotics, and machine learning to help AWS customers accelerate their AI adoption.
Jeremy Feltracco is a Software Development Engineer with the Amazon ML Solutions Lab at Amazon Web Services. He uses his background in computer vision, robotics, and machine learning to help AWS customers accelerate their AI adoption.
 David Dasari is a manager at the Amazon ML Solutions Lab, where he helps AWS customers accelerate their AI and cloud adoption in the Human-In-The-Loop solutions across various industry verticals. With ERP and payment services as his background, was obsessed towards ML/AI taking strides in delighting customers that drove him to this field.
David Dasari is a manager at the Amazon ML Solutions Lab, where he helps AWS customers accelerate their AI and cloud adoption in the Human-In-The-Loop solutions across various industry verticals. With ERP and payment services as his background, was obsessed towards ML/AI taking strides in delighting customers that drove him to this field.