Artificial Intelligence
Build a predictive maintenance solution with Amazon Kinesis, AWS Glue, and Amazon SageMaker
Organizations are increasingly building and using machine learning (ML)-powered solutions for a variety of use cases and problems, including predictive maintenance of machine parts, product recommendations based on customer preferences, credit profiling, content moderation, fraud detection, and more. In many of these scenarios, the effectiveness and benefits derived from these ML-powered solutions can be further enhanced when they can process and derive insights from data events in near-real time.
Although the business value and benefits of near-real-time ML-powered solutions are well established, the architecture required to implement these solutions at scale with optimum reliability and performance is complicated. This post describes how you can combine Amazon Kinesis, AWS Glue, and Amazon SageMaker to build a near-real-time feature engineering and inference solution for predictive maintenance.
Use case overview
We focus on a predictive maintenance use case where sensors deployed in the field (such as industrial equipment or network devices), need to replaced or rectified before they become faulty and cause downtime. Downtime can be expensive for businesses and can lead to poor customer experience. Predictive maintenance powered by an ML model can also help in augmenting the regular schedule-based maintenance cycles by informing when a machine part in good condition should not be replaced, therefore avoiding unnecessary cost.
In this post, we focus on applying machine learning to a synthetic dataset containing machine failures due to features such as air temperature, process temperature, rotation speed, torque, and tool wear. The dataset used is sourced from the UCI Data Repository.
Machine failure consists of five independent failure modes:
- Tool Wear Failure (TWF)
- Heat Dissipation Failure (HDF)
- Power Failure (PWF)
- Over-strain Failure (OSF)
- Random Failure (RNF)
The machine failure label indicates whether the machine has failed for a particular data point if any of the preceding failure modes are true. If at least one of the failure modes is true, the process fails and the machine failure label is set to 1. The objective for the ML model is to identify machine failures correctly, so a downstream predictive maintenance action can be initiated.
Solution overview
For our predictive maintenance use case, we assume that device sensors stream various measurements and readings about machine parts. Our solution then takes a slice of streaming data each time (micro-batch), and performs processing and feature engineering to create features. The created features are then used to generate inferences from a trained and deployed ML model in near-real time. The generated inferences can be further processed and consumed by downstream applications, to take appropriate actions and initiate maintenance activity.
The following diagram shows the architecture of our overall solution.

The solution broadly consists of the following sections, which are explained in detail later in this post:
- Streaming data source and ingestion – We use Amazon Kinesis Data Streams to collect streaming data from the field sensors at scale and make it available for further processing.
- Near-real-time feature engineering – We use AWS Glue streaming jobs to read data from a Kinesis data stream and perform data processing and feature engineering, before storing the derived features in Amazon Simple Storage Service (Amazon S3). Amazon S3 provides a reliable and cost-effective option to store large volumes of data.
- Model training and deployment – We use the AI4I predictive maintenance dataset from the UCI Data Repository to train an ML model based on the XGBoost algorithm using SageMaker. We then deploy the trained model to a SageMaker asynchronous inference endpoint.
- Near-real-time ML inference – After the features are available in Amazon S3, we need to generate inferences from the deployed model in near-real time. SageMaker asynchronous inference endpoints are well suited for this requirement because they support larger payload sizes (up to 1 GB) and can generate inferences within minutes (up to a maximum of 15 minutes). We use S3 event notifications to run an AWS Lambda function to invoke a SageMaker asynchronous inference endpoint. SageMaker asynchronous inference endpoints accept S3 locations as input, generate inferences from the deployed model, and write these inferences back to Amazon S3 in near-real time.
The source code for this solution is located on GitHub. The solution has been tested and should be run in us-east-1.
We use an AWS CloudFormation template, deployed using AWS Serverless Application Model (AWS SAM), and SageMaker notebooks to deploy the solution.
Prerequisites
To get started, as a prerequisite, you must have the SAM CLI, Python 3, and PIP installed. You must also have the AWS Command Line Interface (AWS CLI) configured properly.
Deploy the solution
You can use AWS CloudShell to run these steps. CloudShell is a browser-based shell that is pre-authenticated with your console credentials and includes pre-installed common development and operations tools (such as AWS SAM, AWS CLI, and Python). Therefore, no local installation or configuration is required.
- We begin by creating an S3 bucket where we store the script for our AWS Glue streaming job. Run the following command in your terminal to create a new bucket:
- Note down the name of the bucket created.

- Next, we clone the code repository locally, which contains the CloudFormation template to deploy the stack. Run the following command in your terminal:
- Navigate to the sam-template directory:

- Run the following command to copy the AWS Glue job script (from glue_streaming/app.py) to the S3 bucket you created:

- You can now go ahead with the build and deployment of the solution, through the CloudFormation template via AWS SAM. Run the following command:

- Provide arguments for the deployment such as the stack name, preferred AWS Region (
us-east-1), andGlueScriptsBucket.
Make sure you provide the same S3 bucket that you created earlier for the AWS Glue script S3 bucket (parameter GlueScriptsBucket in the following screenshot).
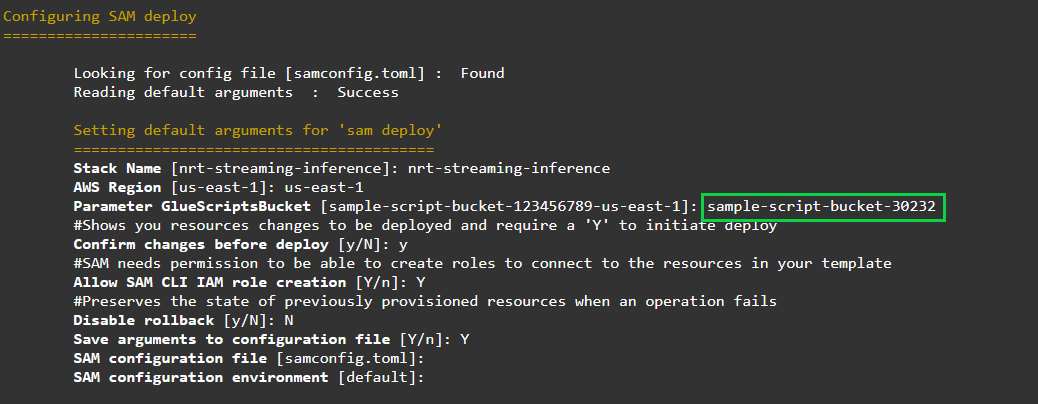
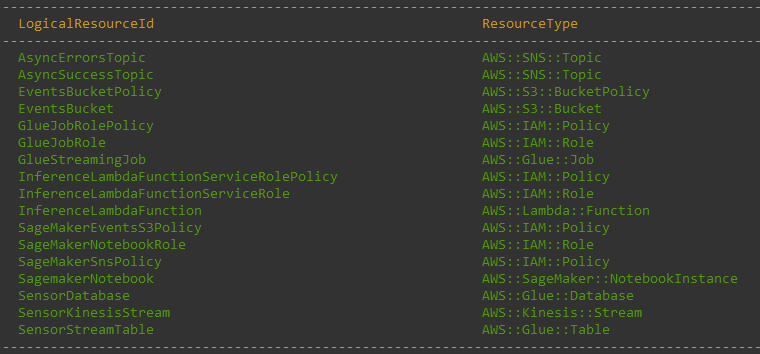
After you provide the required arguments, AWS SAM starts the stack deployment. The following screenshot shows the resources created.
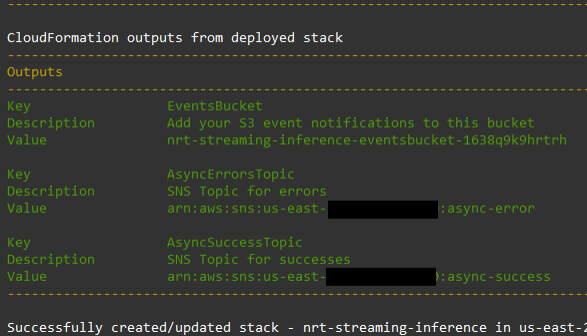
After the stack is deployed successfully, you should see the following message.
- On the AWS CloudFormation console, open the stack (for this post,
nrt-streaming-inference) that was provided when deploying the CloudFormation template. - On the Resources tab, note the SageMaker notebook instance ID.

- On the SageMaker console, open this instance.

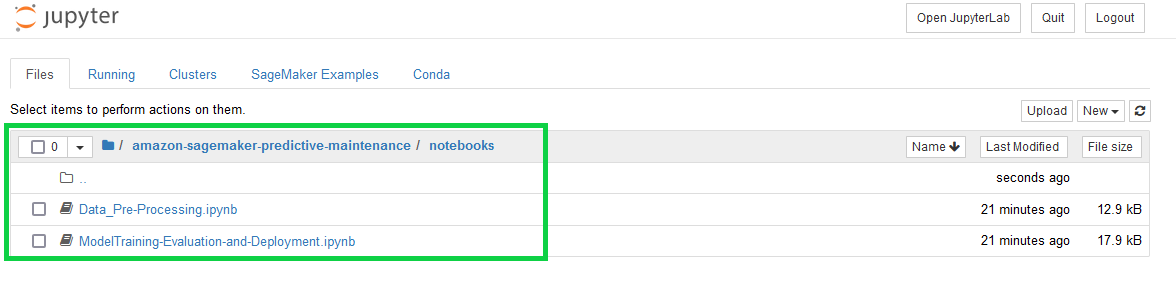
The SageMaker notebook instance already has the required notebooks pre-loaded.
Navigate to the notebooks folder and open and follow the instructions within the notebooks (Data_Pre-Processing.ipynb and ModelTraining-Evaluation-and-Deployment.ipynb) to explore the dataset, perform preprocessing and feature engineering, and train and deploy the model to a SageMaker asynchronous inference endpoint.
Streaming data source and ingestion
Kinesis Data Streams is a serverless, scalable, and durable real-time data streaming service that you can use to collect and process large streams of data records in real time. Kinesis Data Streams enables capturing, processing, and storing data streams from a variety of sources, such as IT infrastructure log data, application logs, social media, market data feeds, web clickstream data, IoT devices and sensors, and more. You can provision a Kinesis data stream in on-demand mode or provisioned mode depending on the throughput and scaling requirements. For more information, see Choosing the Data Stream Capacity Mode.
For our use case, we assume that various sensors are sending measurements such as temperature, rotation speed, torque, and tool wear to a data stream. Kinesis Data Streams acts as a funnel to collect and ingest data streams.
We use the Amazon Kinesis Data Generator (KDG) later in this post to generate and send data to a Kinesis data stream, simulating data being generated by sensors. The data from the data stream sensor-data-stream is ingested and processed using an AWS Glue streaming job, which we discuss next.
Near-real-time feature engineering
AWS Glue streaming jobs provide a convenient way to process streaming data at scale, without the need to manage the compute environment. AWS Glue allows you to perform extract, transform, and load (ETL) operations on streaming data using continuously running jobs. AWS Glue streaming ETL is built on the Apache Spark Structured Streaming engine, and can ingest streams from Kinesis, Apache Kafka, and Amazon Managed Streaming for Apache Kafka (Amazon MSK).
The streaming ETL job can use both AWS Glue built-in transforms and transforms that are native to Apache Spark Structured Streaming. You can also use the Spark ML and MLLib libraries in AWS Glue jobs for easier feature processing using readily available helper libraries.
If the schema of the streaming data source is pre-determined, you can specify it in an AWS Data Catalog table. If the schema definition can’t be determined beforehand, you can enable schema detection in the streaming ETL job. The job then automatically determines the schema from the incoming data. Additionally, you can use the AWS Glue Schema Registry to allow central discovery, control, and evolution of data stream schemas. You can further integrate the Schema Registry with the Data Catalog to optionally use schemas stored in the Schema Registry when creating or updating AWS Glue tables or partitions in the Data Catalog.
For this post, we create an AWS Glue Data Catalog table (sensor-stream) with our Kinesis data stream as the source and define the schema for our sensor data.
We create an AWS Glue dynamic dataframe from the Data Catalog table to read the streaming data from Kinesis. We also specify the following options:
- A window size of 60 seconds, so that the AWS Glue job reads and processes data in 60-second windows
- The starting position
TRIM_HORIZON, to allow reading from the oldest records in the Kinesis data stream
We also use Spark MLlib’s StringIndexer feature transformer to encode the string column type into label indexes. This transformation is implemented using Spark ML Pipelines. Spark ML Pipelines provide a uniform set of high-level APIs for ML algorithms to make it easier to combine multiple algorithms into a single pipeline or workflow.
We use the foreachBatch API to invoke a function named processBatch, which in turn processes the data referenced by this dataframe. See the following code:
The function processBatch performs the specified transformations and partitions the data in Amazon S3 based on year, month, day, and batch ID.
We also re-partition the AWS Glue partitions into a single partition, to avoid having too many small files in Amazon S3. Having several small files can impede read performance, because it amplifies the overhead related to seeking, opening, and reading each file. We finally write the features to generate inferences into a prefix (features) within the S3 bucket. See the following code:
Model training and deployment
SageMaker is a fully managed and integrated ML service that enables data scientists and ML engineers to quickly and easily build, train, and deploy ML models.
Within the Data_Pre-Processing.ipynb notebook, we first import the AI4I Predictive Maintenance dataset from the UCI Data Repository and perform exploratory data analysis (EDA). We also perform feature engineering to make our features more useful for training the model.
For example, within the dataset, we have a feature named type, which represents the product’s quality type as L (low), M (medium), or H (high). Because this is categorical feature, we need to encode it before training our model. We use Scikit-Learn’s LabelEncoder to achieve this:
After the features are processed and the curated train and test datasets are generated, we’re ready to train an ML model to predict whether the machine failed or not based on system readings. We train a XGBoost model, using the SageMaker built-in algorithm. XGBoost can provide good results for multiple types of ML problems, including classification, even when training samples are limited.
SageMaker training jobs provide a powerful and flexible way to train ML models on SageMaker. SageMaker manages the underlying compute infrastructure and provides multiple options to choose from, for diverse model training requirements, based on the use case.
When the model training is complete and the model evaluation is satisfactory based on the business requirements, we can begin model deployment. We first create an endpoint configuration with the AsyncInferenceConfig object option and using the model trained earlier:
We then create a SageMaker asynchronous inference endpoint, using the endpoint configuration we created. After it’s provisioned, we can start invoking the endpoint to generate inferences asynchronously.
Near-real-time inference
SageMaker asynchronous inference endpoints provide the ability to queue incoming inference requests and process them asynchronously in near-real time. This is ideal for applications that have inference requests with larger payload sizes (up to 1 GB), may require longer processing times (up to 15 minutes), and have near-real-time latency requirements. Asynchronous inference also enables you to save on costs by auto scaling the instance count to zero when there are no requests to process, so you only pay when your endpoint is processing requests.
You can create a SageMaker asynchronous inference endpoint similar to how you create a real-time inference endpoint and additionally specify the AsyncInferenceConfig object, while creating your endpoint configuration with the EndpointConfig field in the CreateEndpointConfig API. The following diagram shows the inference workflow and how an asynchronous inference endpoint generates an inference.
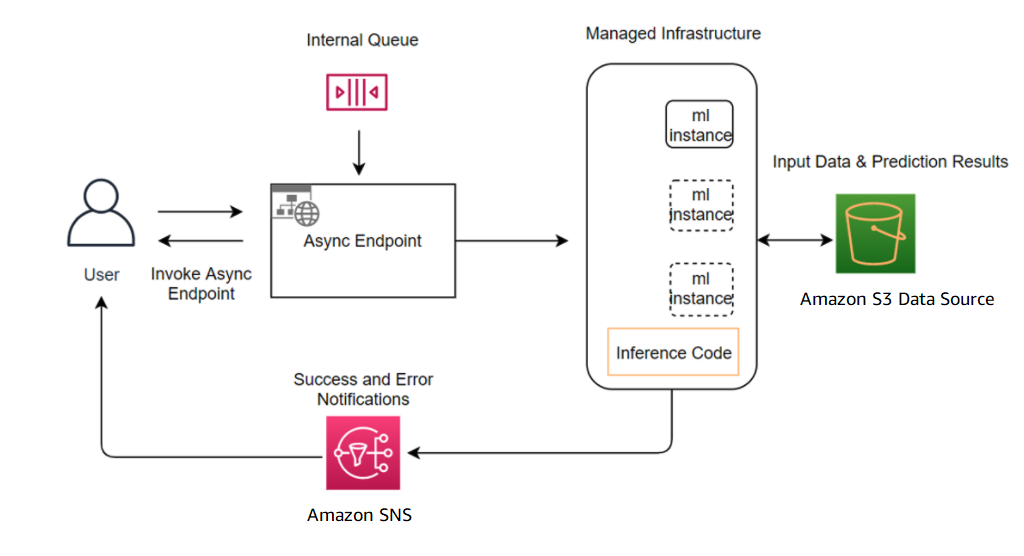
To invoke the asynchronous inference endpoint, the request payload should be stored in Amazon S3 and reference to this payload needs to be provided as part of the InvokeEndpointAsync request. Upon invocation, SageMaker queues the request for processing and returns an identifier and output location as a response. Upon processing, SageMaker places the result in the Amazon S3 location. You can optionally choose to receive success or error notifications with Amazon Simple Notification Service (Amazon SNS).
Test the end-to-end solution
To test the solution, complete the following steps:
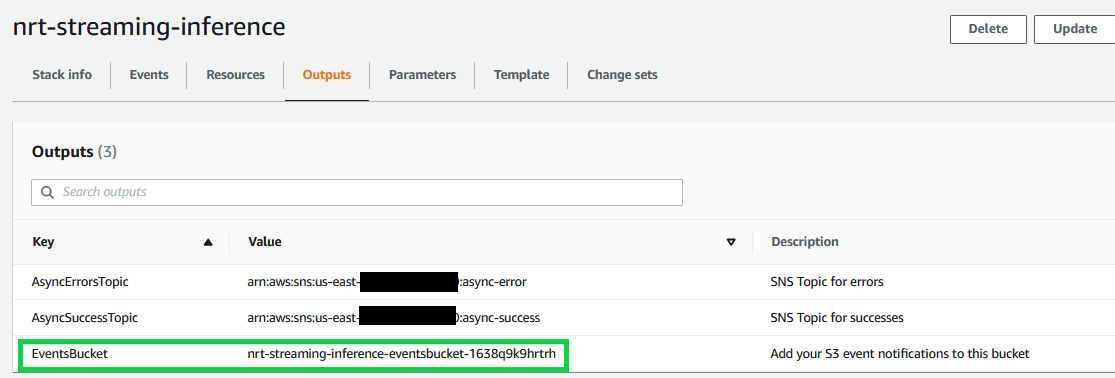
- On the AWS CloudFormation console, open the stack you created earlier (
nrt-streaming-inference). - On the Outputs tab, copy the name of the S3 bucket (
EventsBucket).
This is the S3 bucket to which our AWS Glue streaming job writes features after reading and processing from the Kinesis data stream.
Next, we set up event notifications for this S3 bucket.
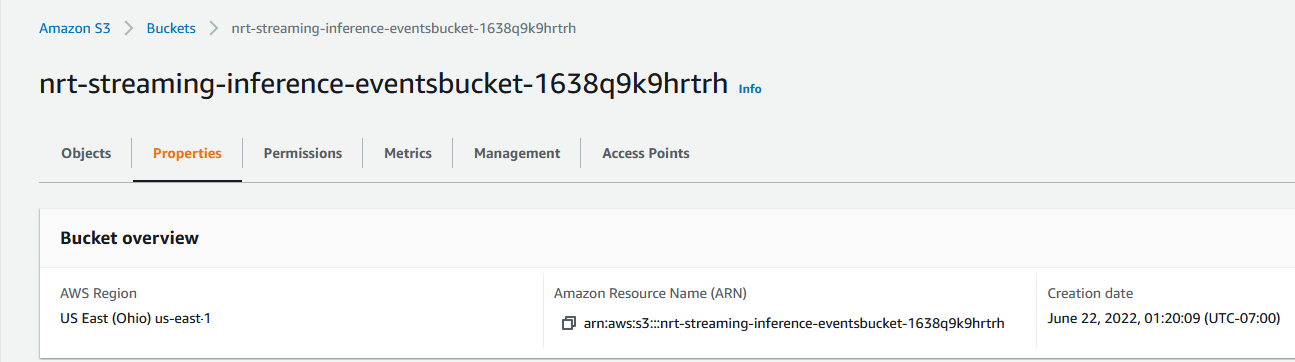
- On the Amazon S3 console, navigate to the bucket
EventsBucket. - On the Properties tab, in the Event notifications section, choose Create event notification.

- For Event name, enter
invoke-endpoint-lambda. - For Prefix, enter
features/. - For Suffix, enter
.csv. - For Event types, select All object create events.

- For Destination, select Lambda function.
- For Lambda function, and choose the function
invoke-endpoint-asynch. - Choose Save changes.

- On the AWS Glue console, open the job
GlueStreaming-Kinesis-S3. - Choose Run job.
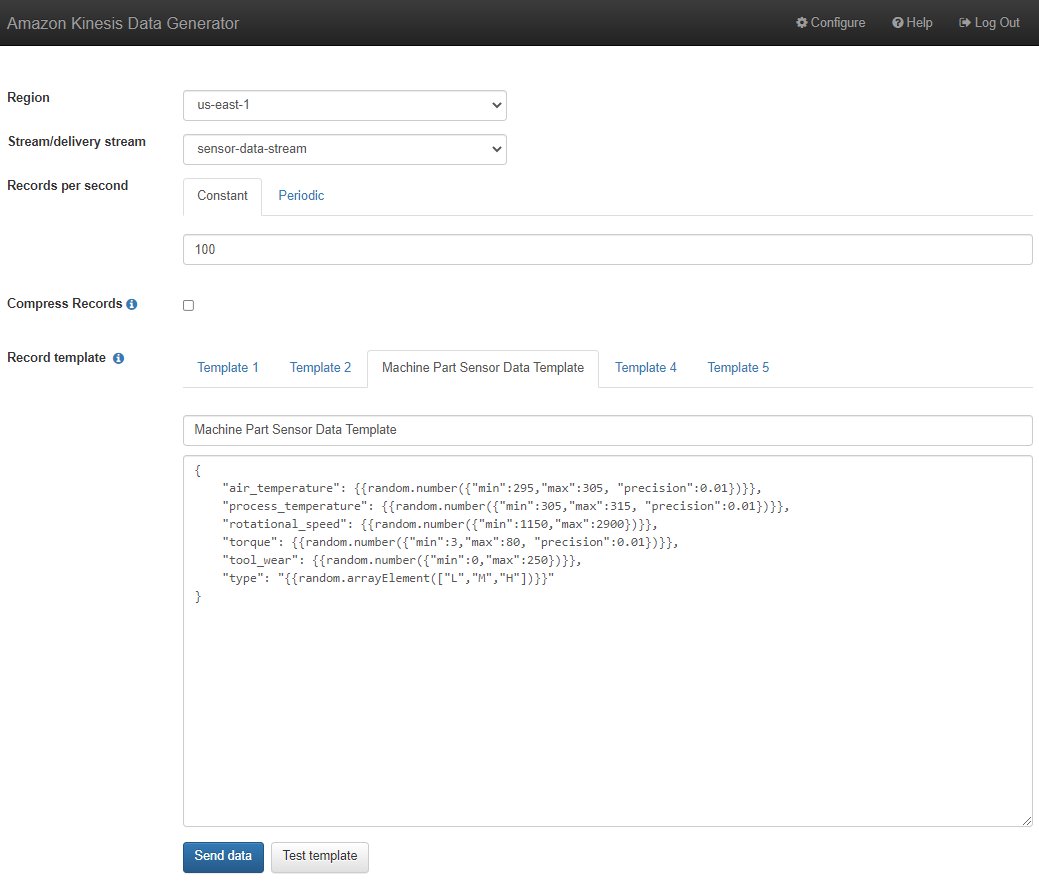
Next we use the Kinesis Data Generator (KDG) to simulate sensors sending data to our Kinesis data stream. If this is your first time using the KDG, refer to Overview for the initial setup. The KDG provides a CloudFormation template to create the user and assign just enough permissions to use the KDG for sending events to Kinesis. Run the CloudFormation template within the AWS account that you’re using to build the solution in this post. After the KDG is set up, log in and access the KDG to send test events to our Kinesis data stream.
- Use the Region in which you created the Kinesis data stream (us-east-1).
- On the drop-down menu, choose the data stream
sensor-data-stream. - In the Records per second section, select Constant and enter 100.
- Unselect Compress Records.
- For Record template, use the following template:
- Click Send data to start sending data to the Kinesis data stream.
The AWS Glue streaming job reads and extracts a micro-batch of data (representing sensor readings) from the Kinesis data stream based on the window size provided. The streaming job then processes and performs feature engineering on this micro-batch before partitioning and writing it to the prefix features within the S3 bucket.
As new features created by the AWS Glue streaming job are written to the S3 bucket, a Lambda function (invoke-endpoint-asynch) is triggered, which invokes a SageMaker asynchronous inference endpoint by sending an invocation request to get inferences from our deployed ML model. The asynchronous inference endpoint queues the request for asynchronous invocation. When the processing is complete, SageMaker stores the inference results in the Amazon S3 location (S3OutputPath) that was specified during the asynchronous inference endpoint configuration.
For our use case, the inference results indicate if a machine part is likely to fail or not, based on the sensor readings.

SageMaker also sends a success or error notification with Amazon SNS. For example, if you set up an email subscription for the success and error SNS topics (specified within the asynchronous SageMaker inference endpoint configuration), an email can be sent every time an inference request is processed. The following screenshot shows a sample email from the SNS success topic.

For real-world applications, you can integrate SNS notifications with other services such as Amazon Simple Queue Service (Amazon SQS) and Lambda for additional postprocessing of the generated inferences or integration with other downstream applications, based on your requirements. For example, for our predictive maintenance use case, you can invoke a Lambda function based on an SNS notification to read the generated inference from Amazon S3, further process it (such as aggregation or filtering), and initiate workflows such as sending work orders for equipment repair to technicians.
Clean up
When you’re done testing the stack, delete the resources (especially the Kinesis data stream, Glue streaming job, and SNS topics) to avoid unexpected charges.
Run the following code to delete your stack:
Also delete the resources such as SageMaker endpoints by following the cleanup section in the ModelTraining-Evaluation-and-Deployment notebook.
Conclusion
In this post, we used a predictive maintenance use case to demonstrate how to use various services such as Kinesis, AWS Glue, and SageMaker to build a near-real-time inference pipeline. We encourage you to try this solution and let us know what you think.
If you have any questions, share them in the comments.
About the authors
 Rahul Sharma is a Solutions Architect at AWS Data Lab, helping AWS customers design and build AI/ML solutions. Prior to joining AWS, Rahul has spent several years in the finance and insurance sector, helping customers build data and analytical platforms.
Rahul Sharma is a Solutions Architect at AWS Data Lab, helping AWS customers design and build AI/ML solutions. Prior to joining AWS, Rahul has spent several years in the finance and insurance sector, helping customers build data and analytical platforms.
 Pat Reilly is an Architect in the AWS Data Lab, where he helps customers design and build data workloads to support their business. Prior to AWS, Pat consulted at an AWS Partner, building AWS data workloads across a variety of industries.
Pat Reilly is an Architect in the AWS Data Lab, where he helps customers design and build data workloads to support their business. Prior to AWS, Pat consulted at an AWS Partner, building AWS data workloads across a variety of industries.