Artificial Intelligence
Build end-to-end document processing pipelines with Amazon Textract IDP CDK Constructs
September 2023: This post was reviewed and updated.
Intelligent document processing (IDP) with AWS helps automate information extraction from documents of different types and formats, quickly and with high accuracy, without the need for machine learning (ML) skills. Faster information extraction with high accuracy can help you make quality business decisions on time, while reducing overall costs. For more information, refer to Intelligent document processing with AWS AI services: Part 1.
However, complexity arises when implementing real-world scenarios. Many times, documents may be sent out of order, or they may be sent as a combined package with multiple form types. Orchestration pipelines need to be created to introduce business logic, and also account for different processing techniques depending on the type of form inputted. These challenges are only magnified as teams deal with large document volumes.
To solve these challenges in this blog we will be demonstrating how teams can use the AWS Intelligent Document Processing CDK Constructs; a set of pre-built IDP constructs, to accelerate the development of real-world document processing pipelines. The problem space we will be tackling in this blog is insurance document processing to enable Straight through processing (STP), however this solution can be extended to any use-case and we will discuss how to in this blog.
Document processing at scale
Straight through processing (STP) is a term used in the financial industry to describe the automation of a transaction from start to finish without the need for manual intervention. In the medical industry, STP is used to streamline the billing and claims process. This involves the automatic extraction of data from medical documents such as prescriptions, policy documents, and claims forms. Implementing STP can be challenging due to the large amount of data and the variety of document formats involved. Medical documents are inherently varied. Traditionally, this process involves manually reviewing each document and entering the data into a system, which is time-consuming and prone to errors. This manual approach is not only inefficient but can also lead to errors that can have a significant impact on the underwriting and claims process. This is where IDP on AWS comes in.
By integrating IDP on AWS into the billing process, insurance carriers can achieve a more efficient and accurate workflow. With Amazon Textract and Amazon Comprehend, insurers can read handwriting and different form formats, making it easier to extract information from various types of medical documents. By implementing IDP on AWS into the process, STP becomes easier to achieve, reducing the need for manual intervention, and speeding up the overall process.
This pipeline will allow insurance carriers to easily and efficiently process their medical claims transactions, reducing the need for manual intervention and improving the overall customer experience. We will demonstrate how to use Amazon Textract and Comprehend to automatically extract data from medical documents, such as a discharge summary form, a prescription form and a HICFA form, and analyze the extracted data to facilitate the underwriting process. By leveraging the power of these services, insurance carriers can improve the accuracy and speed of their STP processes, ultimately providing a better experience for their customers.
Solution overview
The solution is built using the AWS Cloud Development Kit (AWS CDK), and consists of Amazon Comprehend for document classification, Amazon Textract for document extraction, Amazon DynamoDB for storage, AWS Lambda for application logic, and AWS Step Functions for workflow pipeline orchestration.
The pipeline consists of the following phases:
- Splitting of document packages and classification of each form type using Amazon Comprehend.
- Processing pipelines for each for each form type or page of form with the appropriate Amazon Textract API (Signature Detection, Table Extraction, Forms Extraction and/or Queries) .
- Post-processing of the Amazon Textract output into machine readable format.
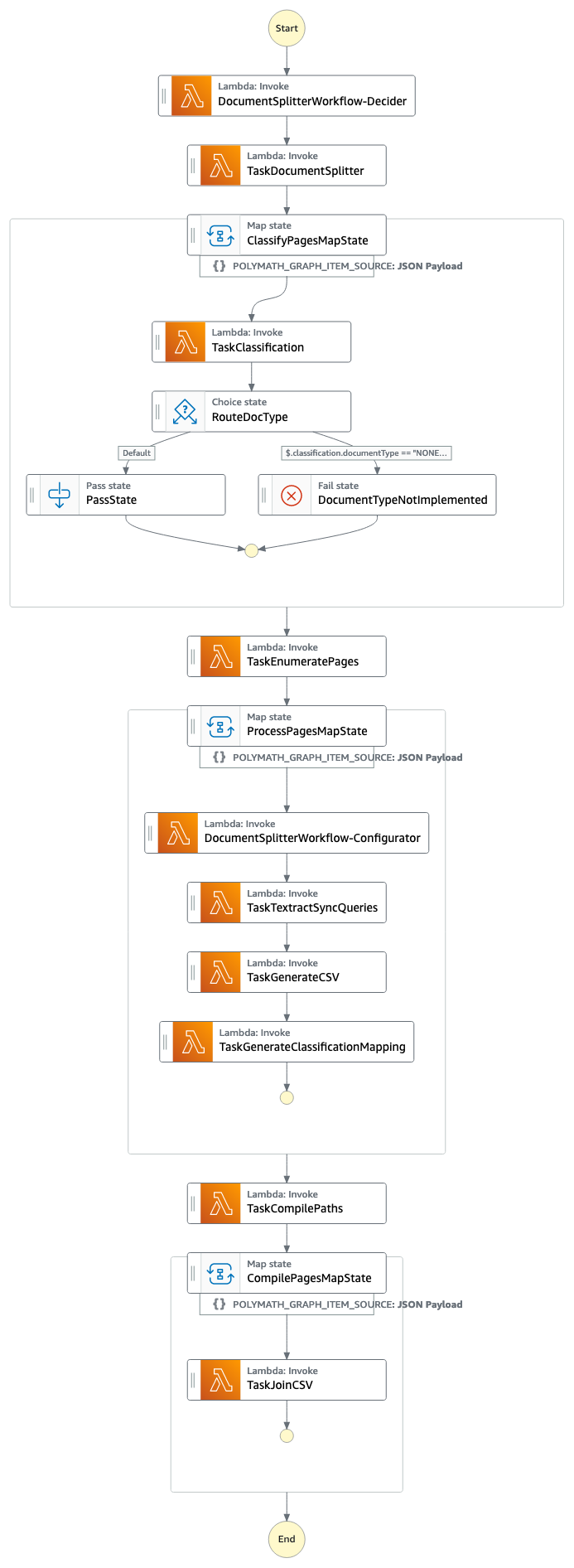
This is demonstrated by the following step-functions workflow:
Prerequisites
To get started with the solution, ensure you have the following:
- AWS CDK version 2 installed
- Docker installed and running on your machine
- Appropriate access to Step Functions, DynamoDB, Lambda, Amazon Simple Queue Service (Amazon SQS), Amazon Textract, and Amazon Comprehend
Clone the GitHub repo
Start by cloning the GitHub repository:
Create an Amazon Comprehend classification endpoint
We first need to provide an Amazon Comprehend classification endpoint.
For this post, the endpoint detects the following document classes (ensure naming is consistent):
claimformdoctorsnotedischargesummary
You can create one by using the comprehend_claims_dataset.csv sample dataset in the repository. To train and create a custom classification endpoint using the sample dataset provided, follow the instructions in Train custom classifiers. If you would like to use your own PDF files, refer to the first workflow in the post Intelligently split multi-form document packages with Amazon Textract and Amazon Comprehend.
After training your classifier and creating an endpoint, you should have an Amazon Comprehend custom classification endpoint ARN that looks like the following code:
Navigate to docsplitter/document_split_workflow.py and modify lines 27–28, which contain comprehend_classifier_endpoint. Enter your endpoint ARN in line 28.
Install dependencies
Now you install the project dependencies:
Initialize the account and Region for the AWS CDK. This will create the Amazon Simple Storage Service (Amazon S3) buckets and roles for the AWS CDK tool to store artifacts and be able to deploy infrastructure. See the following code:
Deploy the AWS CDK stack
When the Amazon Comprehend classifier and document configuration table are ready, deploy the stack using the following code:
Upload the document
Verify that the stack is fully deployed.
Then in the terminal window, run the aws s3 cp command to upload the document to the DocumentUploadLocation for the DocumentSplitterWorkflow:
We have created a sample 3-page document package which contains the HCFA forms, doctor’s note, and discharge summary. Below is a sample of each document.
All data in the forms is synthetic and are used here for demonstration only.
 |
 |
 |
 |
Run the Step Functions workflow
Now open the Step Function workflow. You can get the Step Function workflow link from the document_splitter_outputs.json file, the Step Functions console, or by using the following command:
Depending on the size of the document package, the workflow time will vary. The sample document should take 1–2 minutes to process. The following diagram illustrates the Step Functions workflow.

When your job is complete, navigate to the input and output code. From here you will see the machine-readable CSV files for each of the respective forms.
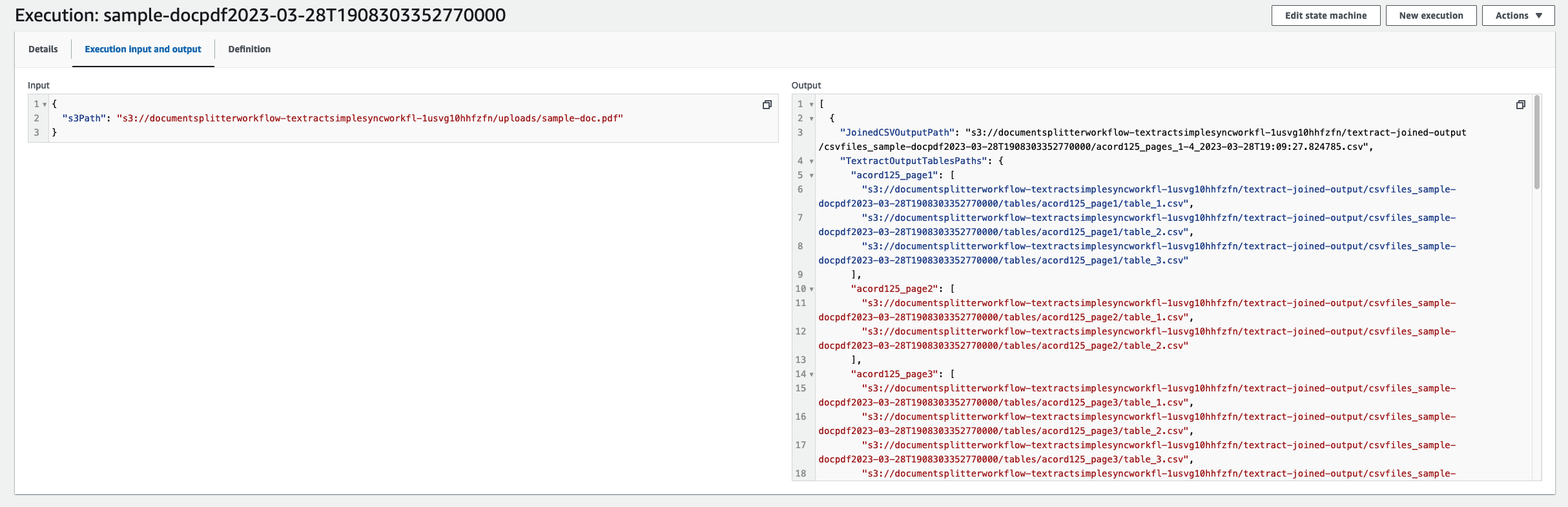
To download these files, open getfiles.py. Set files to be the list outputted by the state machine run. You can run this function by running python3 getfiles.py. This will generate the csvfiles_<TIMESTAMP> folder, as shown in the following screenshot.

Congratulations, you have now implemented an end-to-end processing workflow for a commercial insurance application.
Extend the solution for any type of form
In this post, we demonstrated how we could use the Amazon Textract IDP CDK Constructs for a commercial insurance use case. However, you can extend these constructs for any form type. To do this, we first retrain our Amazon Comprehend classifier to account for the new form type, and adjust the code as we did earlier.
For each of the form types you trained, we must specify its queries and textract_features in the generate_csv.py file. This customizes each form type’s processing pipeline by using the appropriate Amazon Textract API.
Queries is a list of queries. For example, “What is the primary email address?” on page 2 of the sample document. For more information, see Queries.
textract_features is a list of the Amazon Textract features you want to extract from the document. It can be TABLES, FORMS, QUERIES, or SIGNATURES. For more information, see FeatureTypes.
Navigate to generate_csv.py. Each document type needs its classification, queries, and textract_features configured by creating CSVRow instances.
If you want to customize the queries and/or textract_features for a specific page in the document, include the page number when configuring its CSVRow. Otherwise, exclude the page number argument to create a “default” configuration for the specified classification. Each document type must be configured according to one of the following criteria:
- Only a default configuration is specified (see the
claimformexamplein py). - A default configuration is specified, in addition to one or more configurations for specific pages (see the
doctorsnoteexamplein py) - Each page has a custom configuration—there is not a default configuration (see the
dischargesummaryexamplein py).
For example, if an 8-page document has its first, second, and fourth pages’ CSVRow instances configured, for all the remaining pages, the “default” configuration will apply according to the 2nd criteria.
Clean up
To remove the solution, run the cdk destroy command. You will then be prompted to confirm the deletion of the workflow. Deleting the workflow will delete all the generated resources.
Conclusion
In this post, we demonstrated how you can get started with Amazon Textract IDP CDK Constructs by implementing a straight through processing scenario for a set of medical claims forms. We also demonstrated how you can extend the solution to any form type with simple configuration changes. We encourage you to try the solution with your respective documents. Please raise a pull request to the GitHub repo for any feature requests you may have. To learn more about IDP on AWS, refer to our documentation.
About the Authors
 Raj Pathak is a Senior Solutions Architect and Technologist specializing in Financial Services (Insurance, Banking, Capital Markets) and Machine Learning. He specializes in Natural Language Processing (NLP), Large Language Models (LLM) and Machine Learning infrastructure and operations projects (MLOps).
Raj Pathak is a Senior Solutions Architect and Technologist specializing in Financial Services (Insurance, Banking, Capital Markets) and Machine Learning. He specializes in Natural Language Processing (NLP), Large Language Models (LLM) and Machine Learning infrastructure and operations projects (MLOps).
 Aditi Rajnish is a Second-year software engineering student at University of Waterloo. Her interests include computer vision, natural language processing, and edge computing. She is also passionate about community-based STEM outreach and advocacy. In her spare time, she can be found rock climbing, playing the piano, or learning how to bake the perfect scone.
Aditi Rajnish is a Second-year software engineering student at University of Waterloo. Her interests include computer vision, natural language processing, and edge computing. She is also passionate about community-based STEM outreach and advocacy. In her spare time, she can be found rock climbing, playing the piano, or learning how to bake the perfect scone.
 Enzo Staton is a Solutions Architect with a passion for working with companies to increase their cloud knowledge. He works closely as a trusted advisor and industry specialist with customers around the country.
Enzo Staton is a Solutions Architect with a passion for working with companies to increase their cloud knowledge. He works closely as a trusted advisor and industry specialist with customers around the country.