Artificial Intelligence
Category: Analytics

Smart city traffic anomaly detection using Amazon Lookout for Metrics and Amazon Kinesis Data Analytics Studio
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Cities across the world are transforming their public services infrastructure with the mission of enhancing the quality of life of its residents. Roads and traffic management systems […]
Use contextual information and third party data to improve your recommendations
Have you noticed that your shopping preferences are influenced by the weather? For example, on hot days would you rather drink a lemonade vs. a hot coffee? Customers from consumer-packaged goods (CPG) and retail industries wanted to better understand how weather conditions like temperature and rain can be used to provide better purchase suggestions to […]

Build XGBoost models with Amazon Redshift ML
Amazon Redshift ML allows data analysts, developers, and data scientists to train machine learning (ML) models using SQL. In previous posts, we demonstrated how customers can use the automatic model training capability of Amazon Redshift to train their classification and regression models. Redshift ML provides several capabilities for data scientists. It allows you to create […]
Build multi-class classification models with Amazon Redshift ML
July 2024: This post was reviewed and updated for accuracy. Amazon Redshift ML simplifies the use of machine learning (ML) by using simple SQL statements to create and train ML models from data in Amazon Redshift. You can use Amazon Redshift ML to solve binary classification, multi-class classification, and regression problems and can use either AutoML or […]

Prepare data from Snowflake for machine learning with Amazon SageMaker Data Wrangler
Data preparation remains a major challenge in the machine learning (ML) space. Data scientists and engineers need to write queries and code to get data from source data stores, and then write the queries to transform this data, to create features to be used in model development and training. All of this data pipeline development […]
Build regression models with Amazon Redshift ML
June 2023: This post was reviewed and updated for accuracy. With the rapid growth of data, many organizations are finding it difficult to analyze their large datasets to gain insights. As businesses rely more and more on automation algorithms, machine learning (ML) has become a necessity to stay ahead of the competition. Amazon Redshift, a […]

Build BI dashboards for your Amazon SageMaker Ground Truth labels and worker metadata
This is the second in a two-part series on the Amazon SageMaker Ground Truth hierarchical labeling workflow and dashboards. In Part 1: Automate multi-modality, parallel data labeling workflows with Amazon SageMaker Ground Truth and AWS Step Functions, we looked at how to create multi-step labeling workflows for hierarchical label taxonomies using AWS Step Functions. In […]

How Genworth built a serverless ML pipeline on AWS using Amazon SageMaker and AWS Glue
This post is co-written with Liam Pearson, a Data Scientist at Genworth Mortgage Insurance Australia Limited. Genworth Mortgage Insurance Australia Limited is a leading provider of lenders mortgage insurance (LMI) in Australia; their shares are traded on Australian Stock Exchange as ASX: GMA. Genworth Mortgage Insurance Australia Limited is a lenders mortgage insurer with over […]
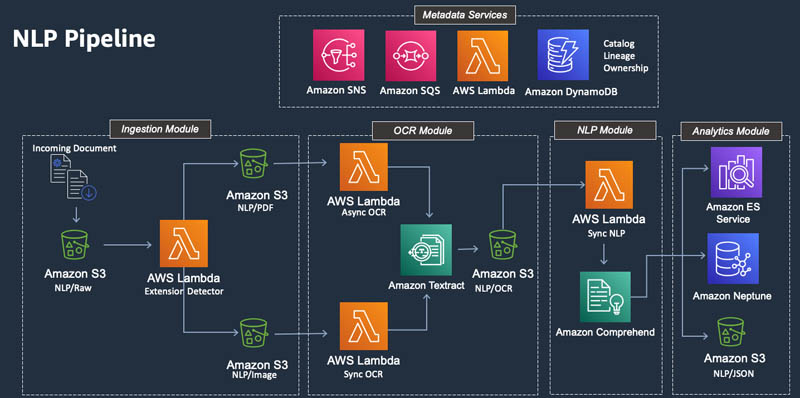
Intelligent governance of document processing pipelines for regulated industries
Processing large documents like PDFs and static images is a cornerstone of today’s highly regulated industries. From healthcare information like doctor-patient visits and bills of health, to financial documents like loan applications, tax filings, research reports, and regulatory filings, these documents are integral to how these industries conduct business. The mechanisms by which these documents […]

Enable cross-account access for Amazon SageMaker Data Wrangler using AWS Lake Formation
Amazon SageMaker Data Wrangler is the fastest and easiest way for data scientists to prepare data for machine learning (ML) applications. With Data Wrangler, you can simplify the process of feature engineering and complete each step of the data preparation workflow, including data selection, cleansing, exploration, and visualization through a single visual interface. Data Wrangler […]