Artificial Intelligence
Category: Artificial Intelligence
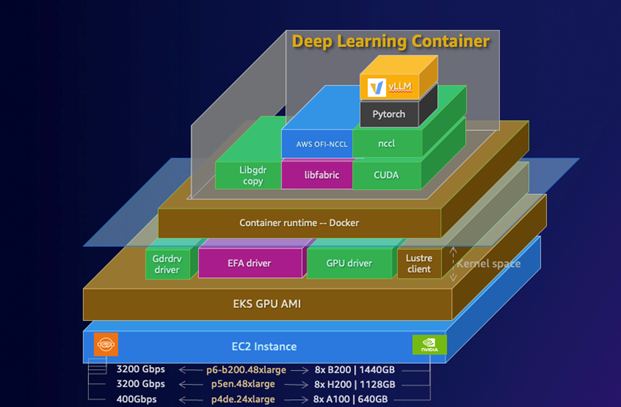
Deploy LLMs on Amazon EKS using vLLM Deep Learning Containers
In this post, we demonstrate how to deploy the DeepSeek-R1-Distill-Qwen-32B model using AWS DLCs for vLLMs on Amazon EKS, showcasing how these purpose-built containers simplify deployment of this powerful inference engine. This solution can help you solve the complex infrastructure challenges of deploying LLMs while maintaining performance and cost-efficiency.

Citations with Amazon Nova understanding models
In this post, we demonstrate how to prompt Amazon Nova understanding models to cite sources in responses. Further, we will also walk through how we can evaluate the responses (and citations) for accuracy.

Securely launch and scale your agents and tools on Amazon Bedrock AgentCore Runtime
In this post, we explore how Amazon Bedrock AgentCore Runtime simplifies the deployment and management of AI agents.

PwC and AWS Build Responsible AI with Automated Reasoning on Amazon Bedrock
This post presents how AWS and PwC are developing new reasoning checks that combine deep industry expertise with Automated Reasoning checks in Amazon Bedrock Guardrails to support innovation.

How Amazon scaled Rufus by building multi-node inference using AWS Trainium chips and vLLM
In this post, Amazon shares how they developed a multi-node inference solution for Rufus, their generative AI shopping assistant, using Amazon Trainium chips and vLLM to serve large language models at scale. The solution combines a leader/follower orchestration model, hybrid parallelism strategies, and a multi-node inference unit abstraction layer built on Amazon ECS to deploy models across multiple nodes while maintaining high performance and reliability.
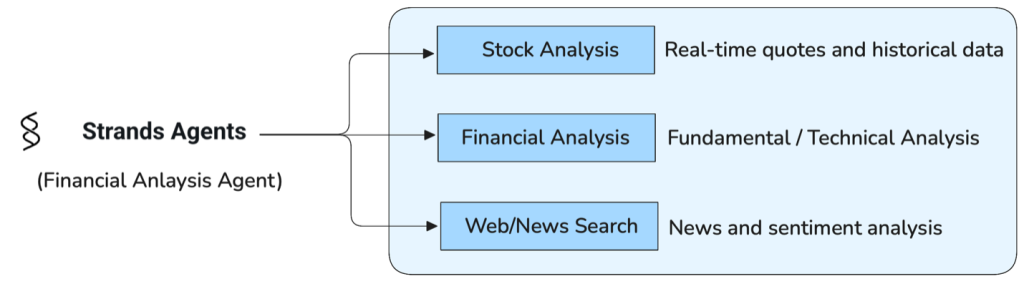
Build an intelligent financial analysis agent with LangGraph and Strands Agents
This post describes an approach of combining three powerful technologies to illustrate an architecture that you can adapt and build upon for your specific financial analysis needs: LangGraph for workflow orchestration, Strands Agents for structured reasoning, and Model Context Protocol (MCP) for tool integration.

Amazon Bedrock AgentCore Memory: Building context-aware agents
In this post, we explore Amazon Bedrock AgentCore Memory, a fully managed service that enables AI agents to maintain both immediate and long-term knowledge, transforming one-off conversations into continuous, evolving relationships between users and AI agents. The service eliminates complex memory infrastructure management while providing full control over what AI agents remember, offering powerful capabilities for maintaining both short-term working memory and long-term intelligent memory across sessions.

Build a conversational natural language interface for Amazon Athena queries using Amazon Nova
In this post, we explore an innovative solution that uses Amazon Bedrock Agents, powered by Amazon Nova Lite, to create a conversational interface for Athena queries. We use AWS Cost and Usage Reports (AWS CUR) as an example, but this solution can be adapted for other databases you query using Athena. This approach democratizes data access while preserving the powerful analytical capabilities of Athena, so you can interact with your data using natural language.

Train and deploy AI models at trillion-parameter scale with Amazon SageMaker HyperPod support for P6e-GB200 UltraServers
In this post, we review the technical specifications of P6e-GB200 UltraServers, discuss their performance benefits, and highlight key use cases. We then walk though how to purchase UltraServer capacity through flexible training plans and get started using UltraServers with SageMaker HyperPod.

How Indegene’s AI-powered social intelligence for life sciences turns social media conversations into insights
This post explores how Indegene’s Social Intelligence Solution uses advanced AI to help life sciences companies extract valuable insights from digital healthcare conversations. Built on AWS technology, the solution addresses the growing preference of HCPs for digital channels while overcoming the challenges of analyzing complex medical discussions on a scale.