Artificial Intelligence
Category: Artificial Intelligence
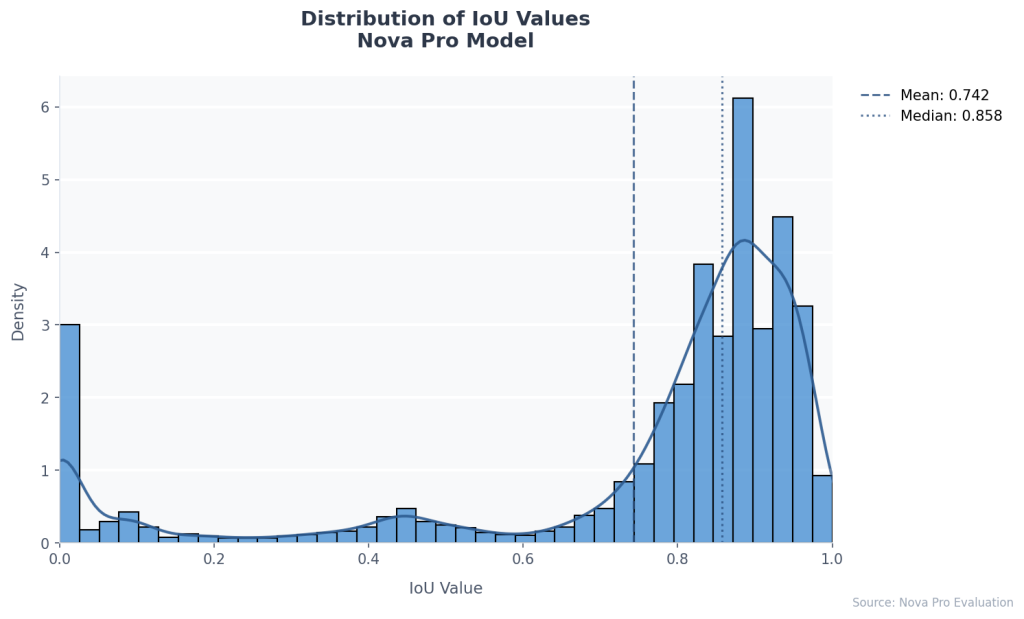
Benchmarking document information localization with Amazon Nova
This post demonstrates how to use foundation models (FMs) in Amazon Bedrock, specifically Amazon Nova Pro, to achieve high-accuracy document field localization while dramatically simplifying implementation. We show how these models can precisely locate and interpret document fields with minimal frontend effort, reducing processing errors and manual intervention.
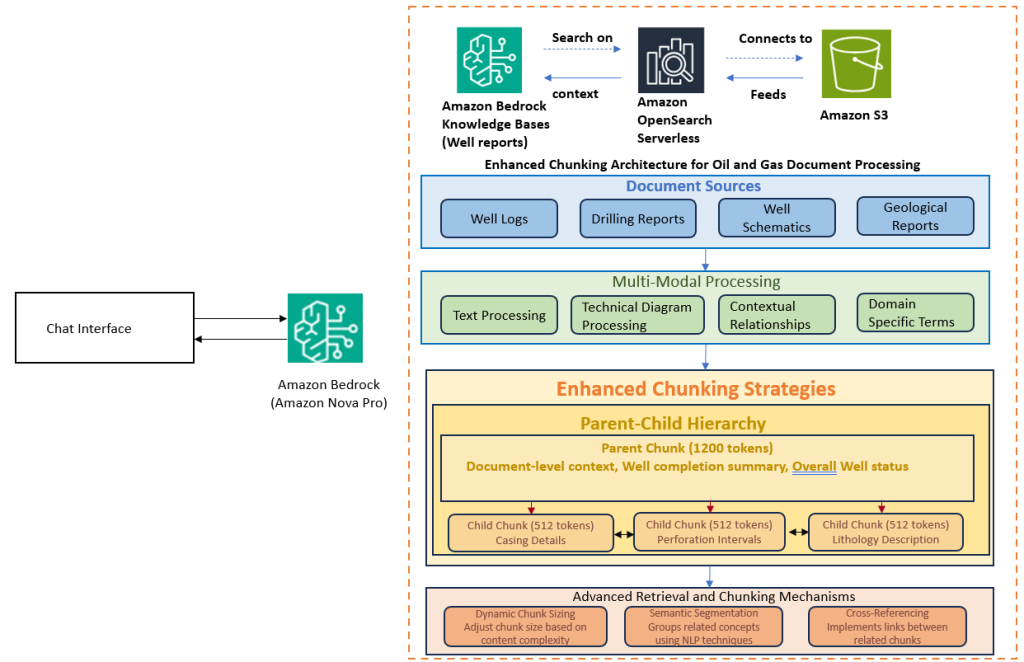
How Infosys built a generative AI solution to process oil and gas drilling data with Amazon Bedrock
We built an advanced RAG solution using Amazon Bedrock leveraging Infosys Topaz™ AI capabilities, tailored for the oil and gas sector. This solution excels in handling multimodal data sources, seamlessly processing text, diagrams, and numerical data while maintaining context and relationships between different data elements. In this post, we provide insights on the solution and walk you through different approaches and architecture patterns explored, like different chunking, multi-vector retrieval, and hybrid search during the development.
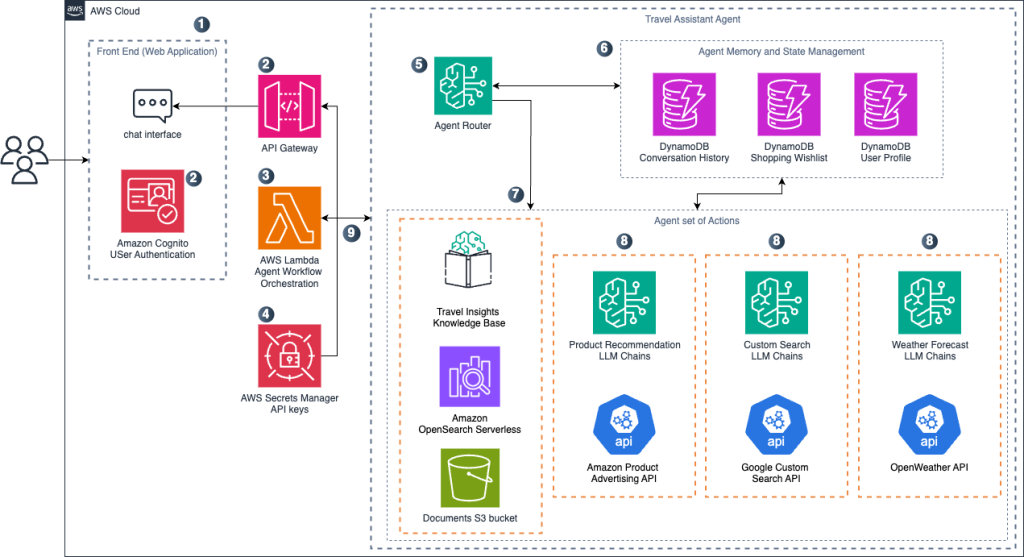
Create a travel planning agentic workflow with Amazon Nova
In this post, we explore how to build a travel planning solution using AI agents. The agent uses Amazon Nova, which offers an optimal balance of performance and cost compared to other commercial LLMs. By combining accurate but cost-efficient Amazon Nova models with LangGraph orchestration capabilities, we create a practical travel assistant that can handle complex planning tasks while keeping operational costs manageable for production deployments.
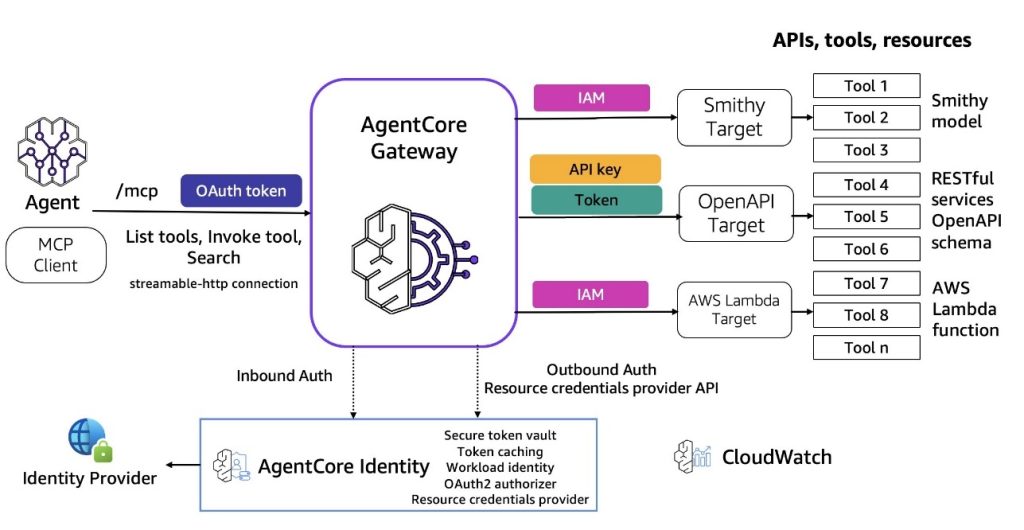
Introducing Amazon Bedrock AgentCore Gateway: Transforming enterprise AI agent tool development
In this post, we discuss Amazon Bedrock AgentCore Gateway, a fully managed service that revolutionizes how enterprises connect AI agents with tools and services by providing a centralized tool server with unified interface for agent-tool communication. The service offers key capabilities including Security Guard, Translation, Composition, Target extensibility, Infrastructure Manager, and Semantic Tool Selection, while implementing sophisticated dual-sided security architecture for both inbound and outbound connections.
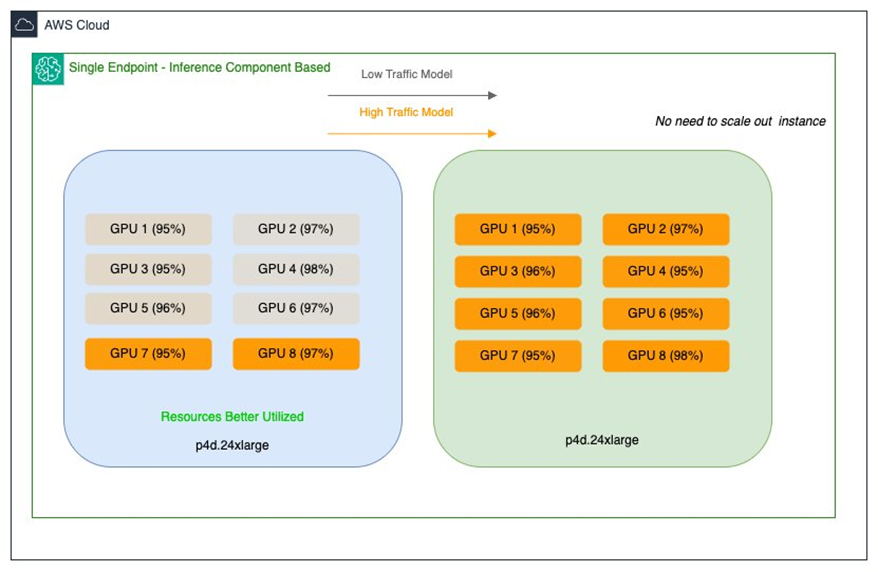
Optimizing Salesforce’s model endpoints with Amazon SageMaker AI inference components
In this post, we share how the Salesforce AI Platform team optimized GPU utilization, improved resource efficiency and achieved cost savings using Amazon SageMaker AI, specifically inference components.
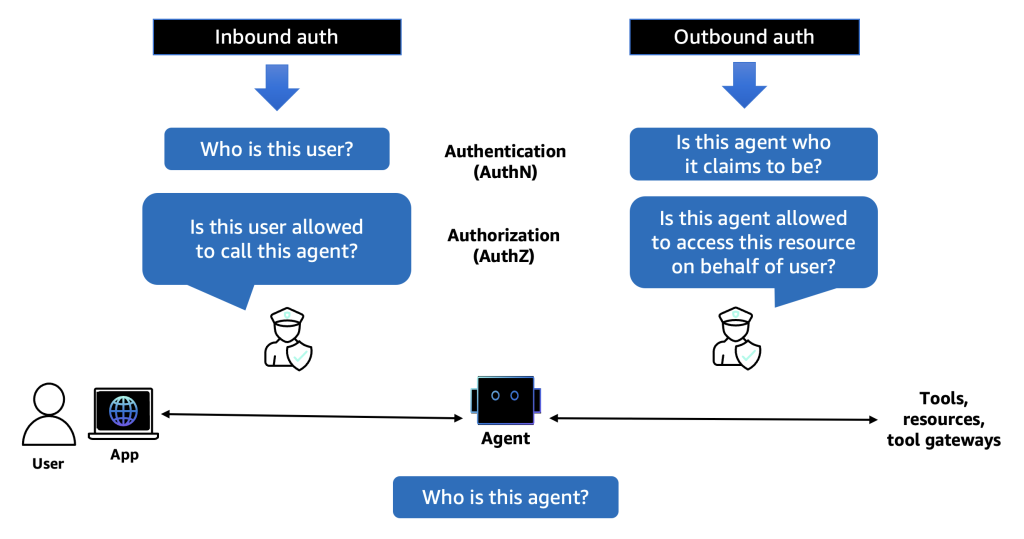
Introducing Amazon Bedrock AgentCore Identity: Securing agentic AI at scale
In this post, we explore Amazon Bedrock AgentCore Identity, a comprehensive identity and access management service purpose-built for AI agents that enables secure access to AWS resources and third-party tools. The service provides robust identity management features including agent identity directory, agent authorizer, resource credential provider, and resource token vault to help organizations deploy AI agents securely at scale.
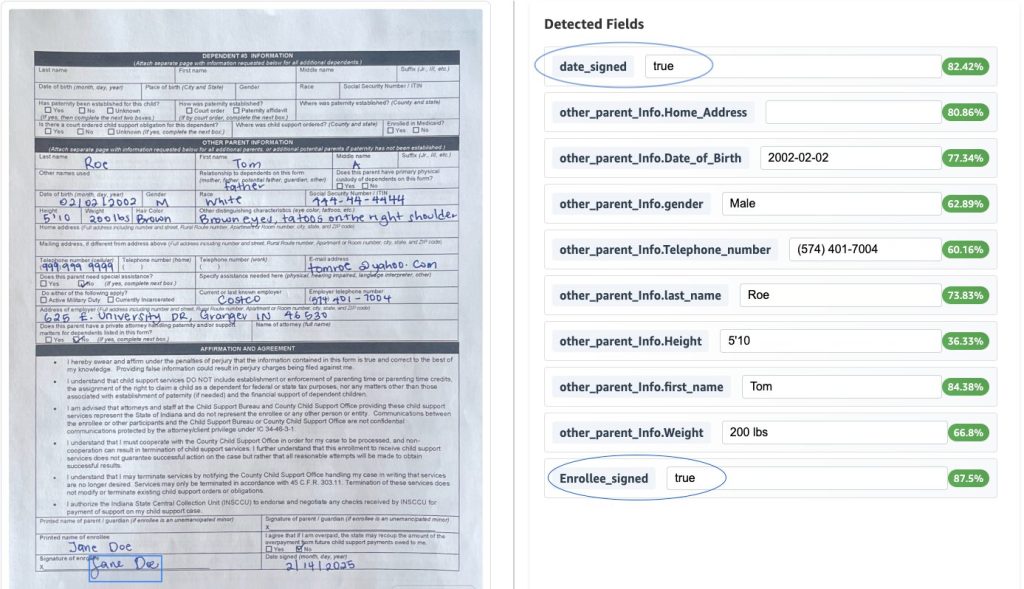
Scalable intelligent document processing using Amazon Bedrock Data Automation
In the blog post Scalable intelligent document processing using Amazon Bedrock, we demonstrated how to build a scalable IDP pipeline using Anthropic foundation models on Amazon Bedrock. Although that approach delivered robust performance, the introduction of Amazon Bedrock Data Automation brings a new level of efficiency and flexibility to IDP solutions. This post explores how Amazon Bedrock Data Automation enhances document processing capabilities and streamlines the automation journey.

Whiteboard to cloud in minutes using Amazon Q, Amazon Bedrock Data Automation, and Model Context Protocol
We’re excited to share the Amazon Bedrock Data Automation Model Context Protocol (MCP) server, for seamless integration between Amazon Q and your enterprise data. In this post, you will learn how to use the Amazon Bedrock Data Automation MCP server to securely integrate with AWS Services, use Bedrock Data Automation operations as callable MCP tools, and build a conversational development experience with Amazon Q.

Bringing agentic Retrieval Augmented Generation to Amazon Q Business
In this blog post, we explore how Amazon Q Business is transforming enterprise data interaction through Agentic Retrieval Augmented Generation (RAG).
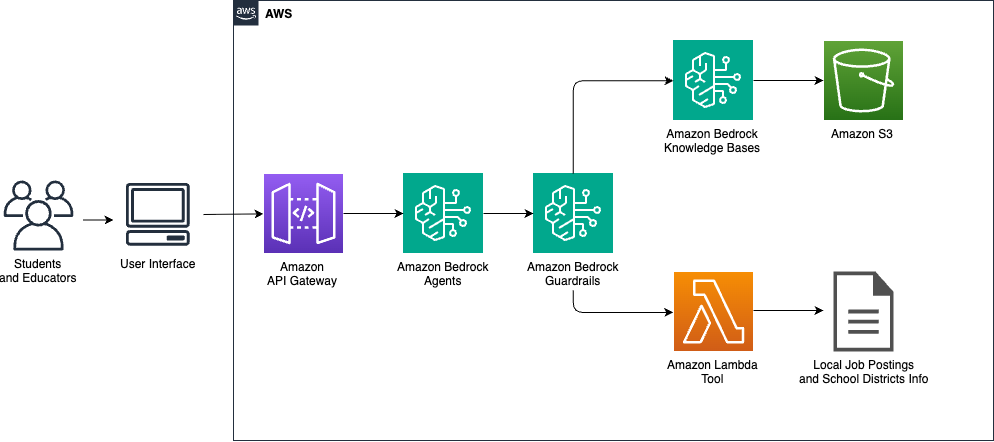
Empowering students with disabilities: University Startups’ generative AI solution for personalized student pathways
University Startups, headquartered in Bethesda, MD, was founded in 2020 to empower high school students to expand their education beyond a traditional curriculum. University Startups is focused on special education and related services in school districts throughout the US. In this post, we explain how University Startups uses generative AI technology on AWS to enable students to design a specific plan for their future either in education or the work force.