Artificial Intelligence
Operationalizing Generative AI: How It Differs from MLOps
December 2025: This post was reviewed and updated for accuracy.
While many organizations recognize the transformative potential of Generative AI for their business operations, successfully integrating these capabilities into production environments presents unique challenges that differ from traditional machine learning operationalization. This post explores how to effectively operationalize generative AI solutions, examining the distinct processes and team structures required, and addressing the varying implementation approaches across different user types, from those leveraging out-of-the-box solutions to organizations building custom foundation models or fine-tuning existing ones.
What MLOps Delivers
As defined in MLOps foundation roadmap for enterprises with Amazon SageMaker, machine learning (ML) and operations (or MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently. To achieve this, a combination of teams and personas need to collaborate, as illustrated in the following figure.
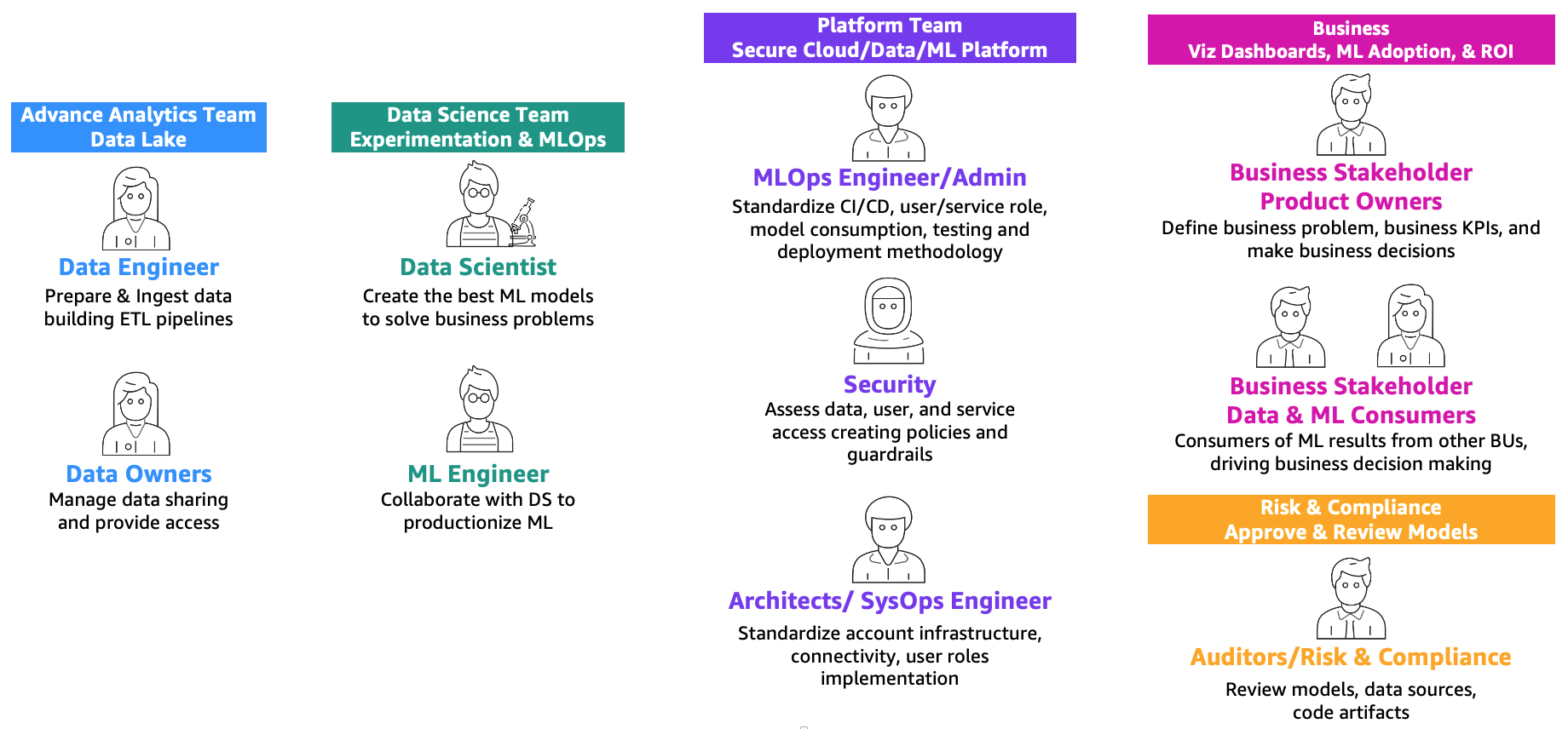
These teams are as follows:
- Advanced analytics team: Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases. These data owners are focused on providing access to their data to multiple business units or teams.
- Data science team: Data scientists need to focus on creating the best model based on predefined key performance indicators (KPIs) working in notebooks. After the completion of the research phase, the data scientists need to collaborate with ML engineers to create automations for building (ML pipelines) and deploying models into production using CI/CD pipelines.
- Business team: A product owner is responsible for defining the business case, requirements, and KPIs to be used to evaluate model performance. The ML consumers are other business stakeholders who use the inference results (predictions) to drive decisions.
- Platform team: Architects are responsible for the overall cloud architecture of the business and how all the different services are connected together. Security SMEs review the architecture based on business security policies and needs. MLOps engineers are responsible for providing a secure environment for data scientists and ML engineers to productionize the ML use cases. Specifically, they are responsible for standardizing CI/CD pipelines, user and service roles and container creation, model consumption, testing, and deployment methodology based on business and security requirements.
- Risk and compliance team: For more restrictive environments, auditors are responsible for assessing the data, code, and model artifacts and making sure that the business is compliant with regulations, such as data privacy.
Note that multiple personas can be covered by the same person depending on the scaling and MLOps maturity of the business.
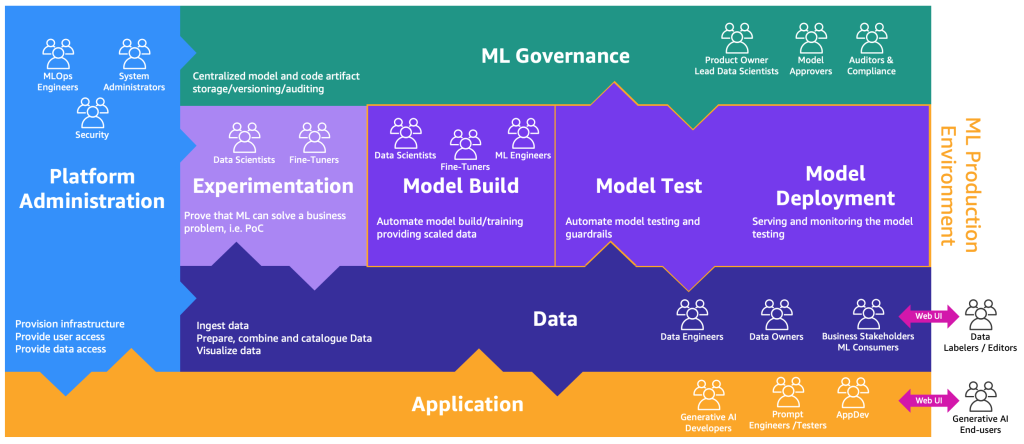
These personas need dedicated environments to perform the different processes, as illustrated in the following figure.
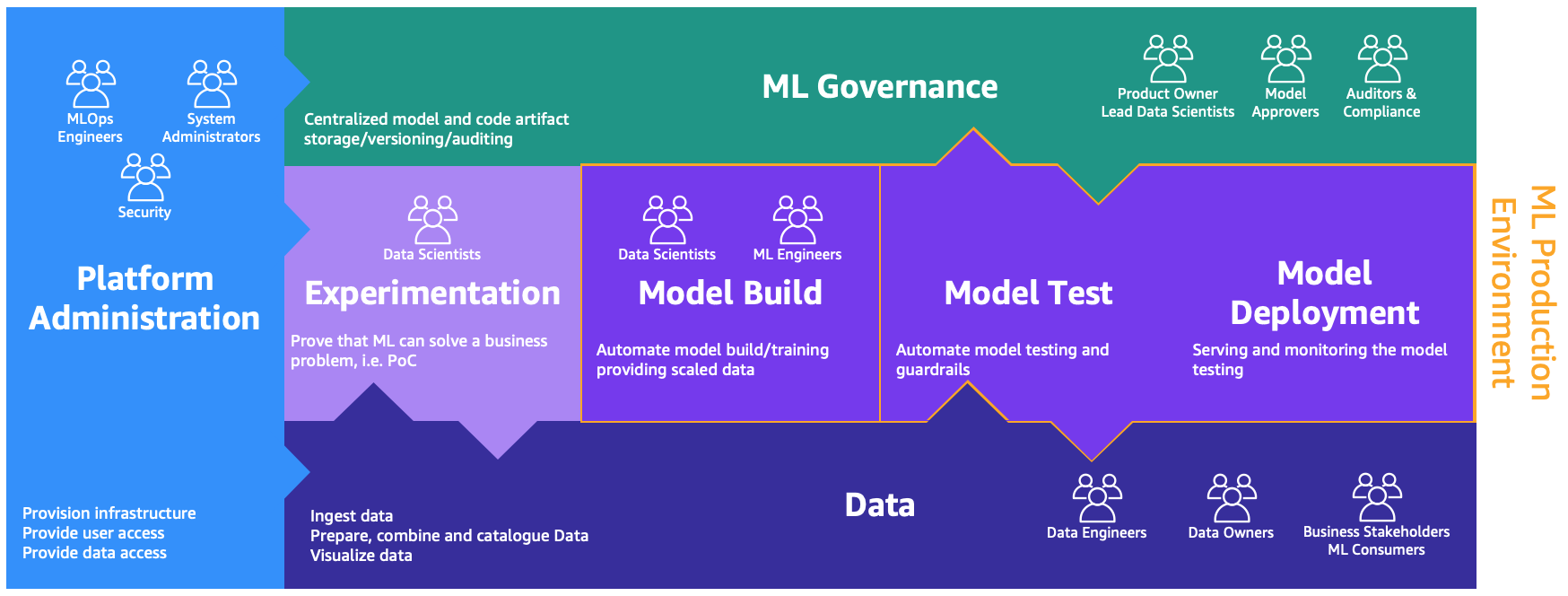
The environments are as follows:
- Platform administration: The platform administration environment is the place where the platform team has access to create AWS accounts and link the right users and data.
- Data: The data layer, often known as the data lake or data mesh, is the environment that data engineers or owners and business stakeholders use to prepare, interact, and visualize with the data.
- Experimentation: The data scientists use a sandbox or experimentation environment to test new libraries and ML techniques to prove that their proof of concept can solve business problems.
- Model build, test, deployment: This MLOps layer provides the environment where data scientists and ML engineers collaborate to automate workflows and transition models from research into production.
- ML governance: The last piece of the puzzle is the ML governance environment, where all the model and code artifacts are stored, reviewed, and audited by the corresponding personas.
Each business unit has each own set of development (automated model training and building), preproduction (automatic testing), and production (model deployment and serving) accounts to productionize ML use cases, which retrieve data from a centralized or decentralized data lake or data mesh, respectively. All the produced models and code automation are stored in a centralized tooling account using the capability of a model registry. The infrastructure code for all these accounts is versioned in a shared service account (advanced analytics governance account) that the platform team can abstract, templatize, maintain, and reuse for the onboarding to the MLOps platform of every new team.
For a deeper dive, the MLOps foundation roadmap for enterprises with Amazon SageMaker provides an illustrative reference architecture, while best practices are outlined in the planning for successful MLOps prescriptive guidance.
Why Generative AI Demands More than MLOps
The Generative AI ecosystem is made up of three user types – providers, fine-tuners, and consumers – each with distinct skillsets and operational requirements. This has been driven by the rise of foundation models (FM) that are are pre‑trained on massive data sets and then adapted to specific tasks through fine‑tuning or prompt engineering. The figure below highlights how these groups relate to one another:
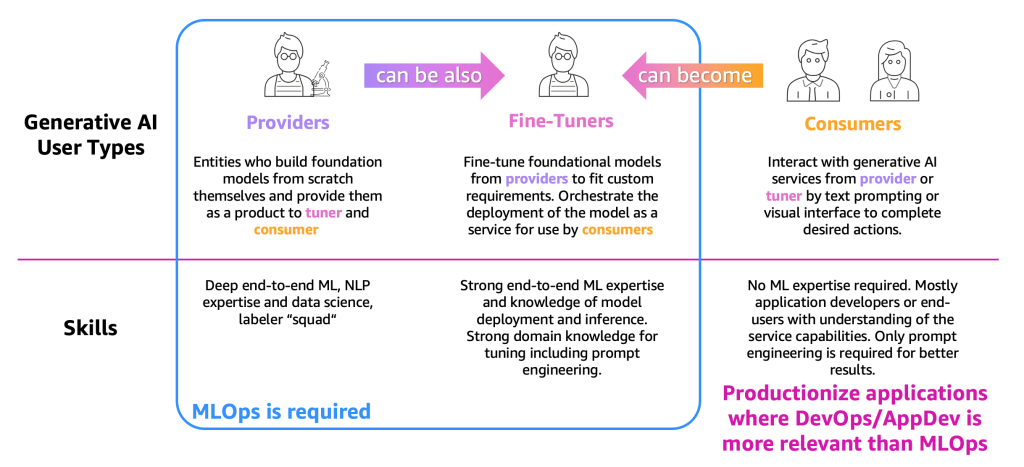
The user types are as follows:
- Providers – Users who build FMs from scratch and offer them as products to other users (fine-tuners and consumers). They require deep end-to-end ML, natural language processing (NLP), and data science expertise and extensive labeling/editing teams.
- Fine-tuners – Users who adapt FMs from providers to meet specific needs and deploy them as services for consumers. They require strong ML and data science expertise, proficiency in model deployment and inference, and domain knowledge for effective tuning, including prompt engineering.
- Consumers – Users who access generative AI through prompts or visual interfaces to accomplish tasks. They do not need ML expertise, as they are typically application developers or end-users who understand the service’s capabilities. Effective use relies mainly on prompt engineering to achieve better outcomes.
MLOps practices are most relevant for providers and fine-tuners, who manage the end-to-end lifecycle of model training, adaptation, deployment, and monitoring. For consumers, by contrast, additional challenges exist. While they can rely on DevOps and AppDev principles to integrate generative AI into their products, they also encounter issues that MLOps, or traditional software operations do not address.
This is because generative AI solutions differ fundamentally from classical predictive models. Instead of returning a fixed value or label, they generate human-like text, images, video, or code in a non-deterministic fashion. These models are typically pre-trained on massive datasets and then adapted through fine-tuning or prompt engineering. Building on this, FMs can be incorporated with knowledge bases through retrieval-augmented generation (RAG) workflows, or into Agentic AI that combines tools, memory, and reasoning loops to deliver more autonomous, task-oriented work.
Such capabilities introduce new operational challenges that extend beyond MLOps:
- Bias and data quality: training data can introduce harmful biases or inappropriate outputs.
- Security risks: prompts or injection attacks may trigger data leaks or malicious content.
- System complexity: solutions often combine foundation models with retrieval, prompts, chain logic, and agents.
- Unpredictable outputs: models can hallucinate or drift in style; testing is non-deterministic.
- High costs: fine-tuning and serving large models are resource-intensive, often requiring hosted APIs.
For consumers, GenAIOps is especially important. Unlike traditional DevOps or AppDev, it provides operational frameworks for managing prompts, testing non-deterministic outputs, and coordinating multi-component systems. These capabilities are essential for embedding generative AI into applications but are not fully addressed by existing practices. At the other end of the spectrum, providers focus on MLOps: training models, labeling data, and scaling infrastructure. Fine-tuners occupy the middle ground, blending MLOps with GenAIOps as they adapt foundation models to domain-specific needs through tuning, evaluation, and structured prompting. Over time, these user roles are likely to evolve: providers may fine-tune for industry verticals like finance, while consume may adopt fine-tuning themselves to achieve more accurate and reliable results.
Introducing GenAIOps
Generative AI Operations (GenAIOps) extends MLOps by focusing on the processes and techniques required to manage and operationalize foundation models in production environments, helping organizations reduce risks and optimize deployments. It covers both model consumption and training, addressing CI/CD, prompt management, versioning, upgrades, evaluation, and monitoring. With GenAIOps, organizations gain a robust, automated framework for the full lifecycle of generative AI workloads.
Beyond extending MLOps processes, GenAIOps also expands the range of roles involved. Building on the aforementioned user types of consumers, providers, and fine-tuners, it introduces new personas with specialized skills, as shown in the following figure.
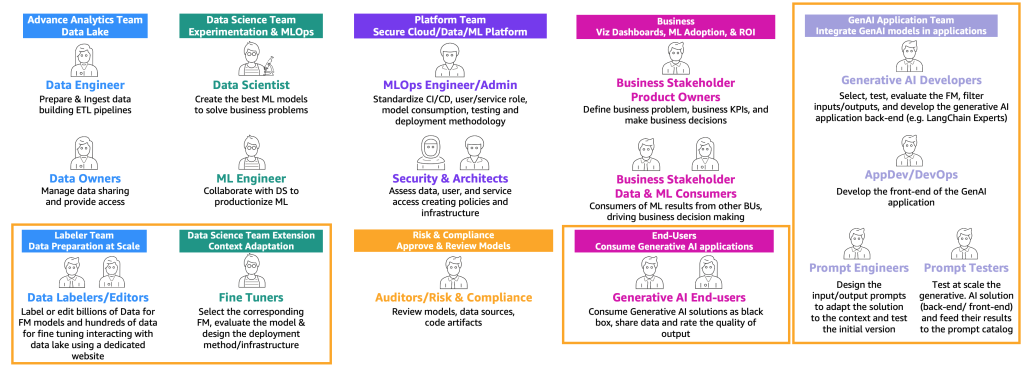
The new personas are as follows:
- Data labelers and editors: These users label data (for example <text, image> pairs) or prepare unlabeled data, such as free text, and extend the advanced analytics team and data lake environments.
- Fine-tuners: These users have deep knowledge on FMs and know to tune them, extending the data science team that will focus on classic ML.
- Generative AI developers: They have deep knowledge on selecting FMs, chaining prompts and applications, and filtering input and outputs. They belong a new team—the generative AI application team.
- Prompt engineers: These users design the input and output prompts to adapt the solution to the context and test and create the initial version of prompt catalog. Their team is the generative AI application team.
- Prompt testers: They test at scale the generative AI solution (backend and frontend) and feed their results to augment the prompt catalog and evaluation dataset. Their team is the generative AI application team.
- AppDev and DevOps: They develop the front end (such as a website) of the generative AI application. Their team is the generative AI application team.
- Generative AI end-users: These users consume generative AI applications as black boxes, share data, and rate the quality of the output.
The extended version of the MLOps process map to incorporate generative AI can be illustrated with the following figure.
A new application layer is the environment where generative AI developers, prompt engineers, and testers, and AppDevs created the backend and front end of generative AI applications. The generative AI end-users interact with the generative AI applications front end via the internet (such as a web UI). On the other side, data labelers and editors need to preprocess the data without accessing the backend of the data lake or data mesh. Therefore, a web UI (website) with an editor is necessary for interacting securely with the data. SageMaker Ground Truth provides this functionality out of the box.
For a deeper dive, the Generative AI Lens provides guidance and best practices for designing, deploying, and operating well-architected generative AI applications on AWS.
Operational Lifecycle
The Journey of Providers
For foundation model providers, their path closely follows the end-to-end MLOps lifecycle, but at a much larger scale and with additional requirements.
Their journey begins with data collection and preparation. In classical ML, historical data is often created automatically, such as ETL pipelines updating a churn table with customer labels. By contrast, foundation models demand billions of data points, either labeled or unlabeled, across text, images, or other modalities. In text-to-image scenarios, for instance, human labelers may be required to create <text, image> pairs—an effort that is both costly and resource-intensive. Services like Amazon SageMaker Ground Truth Plus can provide teams of labelers, while CLIP-like models can be used to partially automate this work. For large language models (LLMs), data is often unlabeled, but it still requires extensive editing and formatting to ensure consistency. Here, data editors play a critical role in cleaning and structuring massive corpora.
Once data is prepared, providers shift to training large-scale deep learning models on distributed infrastructure powered by GPUs, a process that is highly iterative, resource-intensive, and dependent on continuous refinement of both algorithms and systems. Following training, the focus moves to evaluation and validation, combining automated benchmarks (e.g., perplexity for text, FID for images) with human-in-the-loop reviews to assess realism, safety, and alignment. Successful models are then deployed and productionized. Providers typically make their models accessible through APIs or hosted platforms, requiring robust MLOps practices for CI/CD pipelines, containerization, scaling, and automated rollouts. These capabilities ensure that models can be delivered reliably to millions of downstream fine-tuners and consumers.
Finally, deployed models must be continuously monitored. Providers track not just system performance, but also usage patterns, cost efficiency, and evidence of model drift or degradation. Insights from monitoring feed back into data collection and training, restarting the lifecycle and enabling ongoing improvement.
The Journey of Fine-Tuners
Fine-tuners aim to adapt an existing FM to their specific context. For example, an FM model can summarize a general-purpose text but not a financial report accurately or can’t generate source code for a niche programming language. In those cases, the fine-tuners need to label data, fine-tune a model by running a training job, deploy the model, test it based on the consumer processes, and monitor the model. The following diagram illustrates this process.
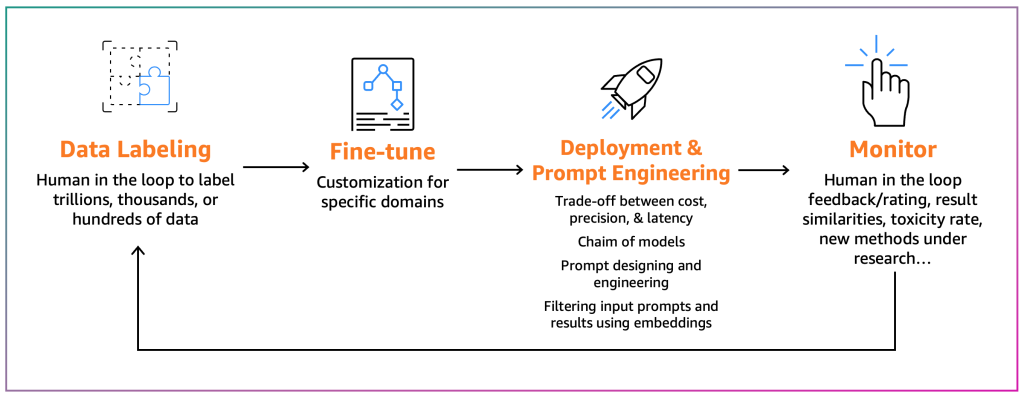
Currently, there are two main approaches to fine-tuning:
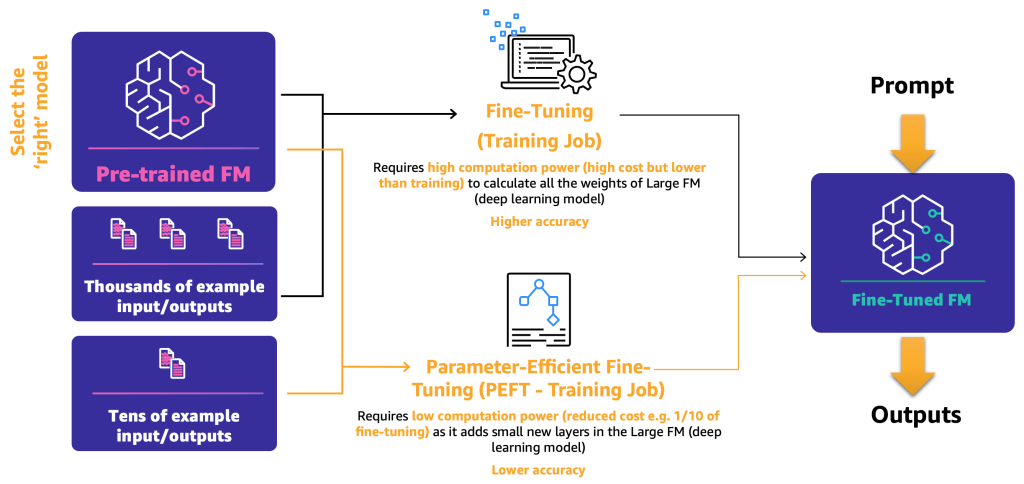
- Fine-tuning: By using an FM and labeled data, a training job recalculates the weights and biases of the deep learning model layers. This process can be computationally intensive and requires a representative amount of data but can generate accurate results.
- Parameter-efficient fine-tuning (PEFT): Instead of recalculating all the weights and biases, researchers have shown that by adding additional small layers to the deep learning models, they can achieve satisfactory results (for example, LoRA). PEFT requires lower computational power than deep fine-tuning and a training job with less input data. The drawback is potential lower accuracy.
The following diagram illustrates these mechanisms.
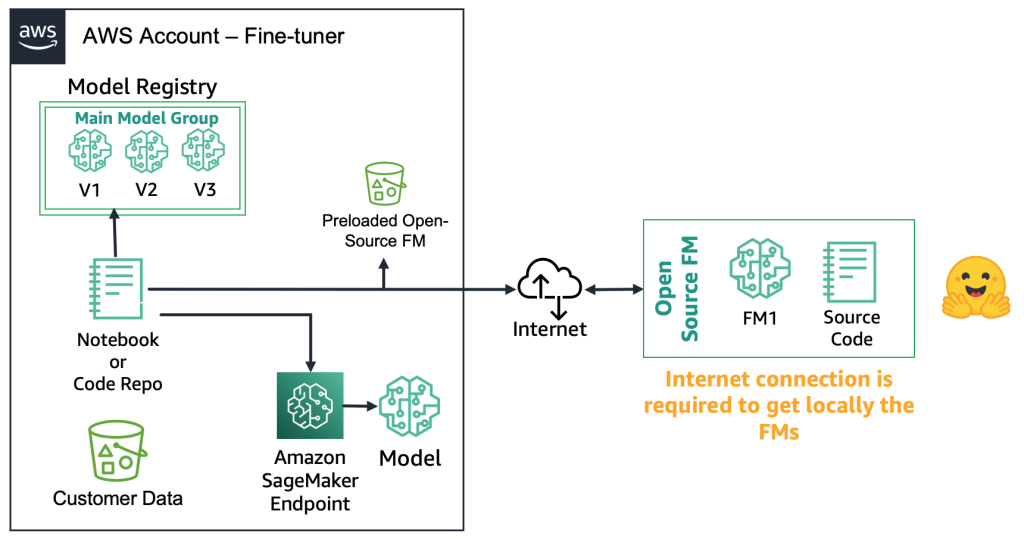
With the two primary fine-tuning methods defined, the next step is to explore how open-source and proprietary foundation models can be deployed and deployed.
With open-source FMs, fine-tuners can download the model artifact and source code from repositories such as Hugging Face Model Hub. This enables them to fine-tune the model, register it locally, and deploy it to an Amazon SageMaker endpoint (requires internet connection). For secure environments like financial services, the model can instead be downloaded on premises, scanned for security, and uploaded to a local AWS bucket. Fine-tuners then work from the local copy without internet connectivity, ensuring data privacy and compliance. The following diagram illustrates this method.
With proprietary FMs, the deployment process is different because the fine-tuners don’t have access to the model artifact or source code. The models are stored in proprietary FM provider AWS accounts and model registries. To deploy such a model to a SageMaker endpoint, the fine-tuners can request only the model package that will be deployed directly to an endpoint. This process requires customer data to be used in the proprietary FM providers’ accounts, which raises questions regarding customer-sensitive data being used in a remote account to perform fine-tuning, and models being hosted in a model registry that is shared among multiple customers. This leads to a multi-tenancy problem that becomes more challenging if the proprietary FM providers need to serve these models. If the fine-tuners use Amazon Bedrock, these challenges are resolved—the data doesn’t travel over the internet and the FM providers don’t have access to fine-tuners’ data. The same challenges hold for the open-source models if the fine-tuners want to serve models from multiple customers, such as the example we gave earlier with the website that thousands of customers will upload personalized images to. However, these scenarios can be considered controllable because only the fine-tuner is involved. The following diagram illustrates this method.
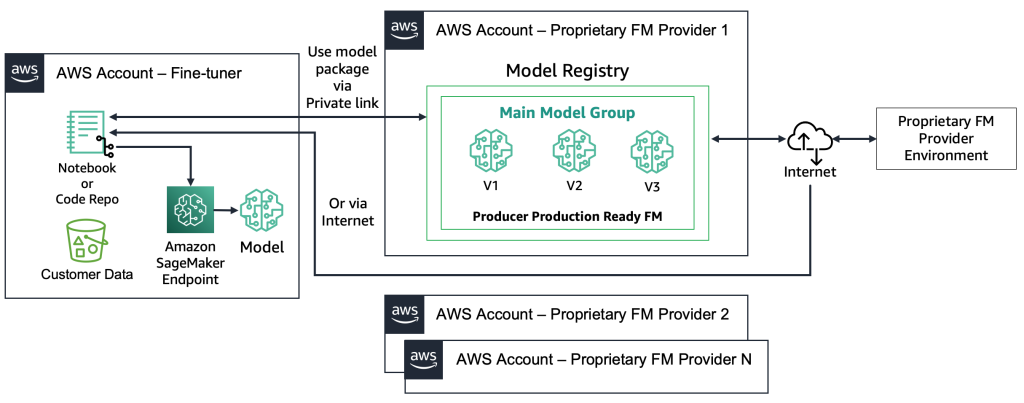
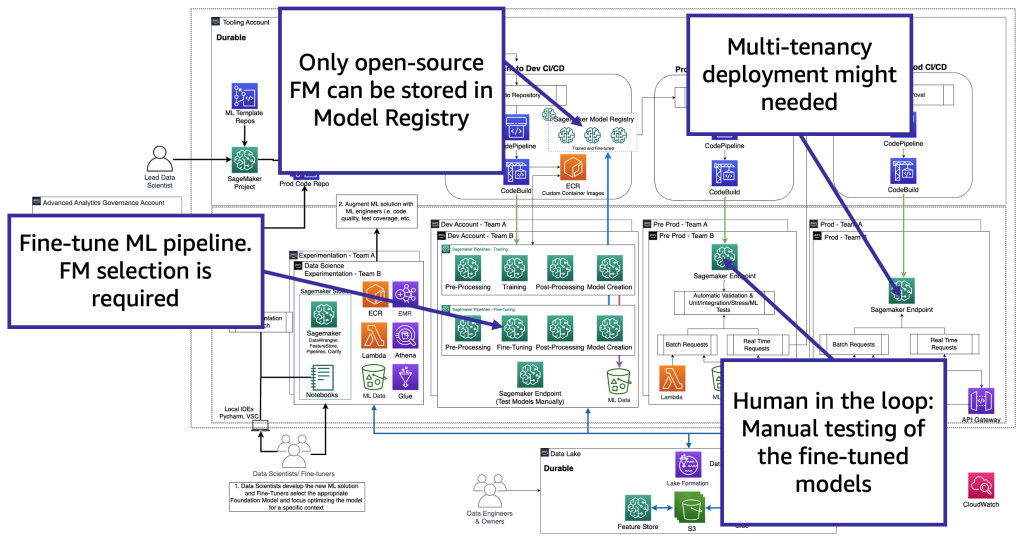
From a technology perspective, the architecture that a fine-tuner needs to support is like the one for MLOps (see the below figure). In development, ML pipelines (e.g., Amazon SageMaker Pipelines) handle preprocessing, fine-tuning, and post-processing, with models stored either in a local registry (open-source) or the provider’s environment (proprietary). In pre-production, models are tested as in the consumer workflow, and in production they are deployed and monitored on GPU endpoints. Since hosting hundreds of separate endpoints is costly, fine-tuners often rely on multi-model endpoints to manage scale and multi-tenancy.
Fine-tuners adapt foundation models to specific business contexts, often acting as consumers too, requiring them to manage all layers – from generative AI app development to data lakes, data meshes, and MLOps. The following figure illustrates the complete FM fine-tuning lifecycle that the fine-tuners need to provide the generative AI end-user.

The following figure highlights the key steps a fine-tuner takes, layered onto the previous diagram.
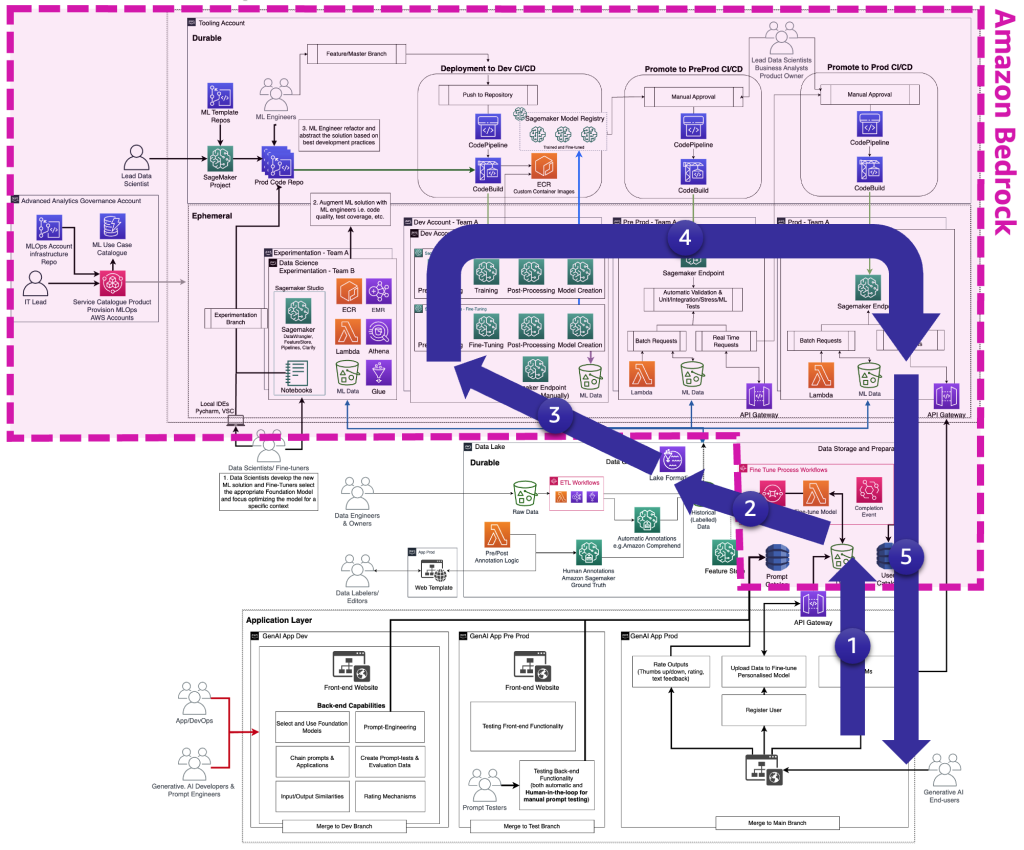
The key steps are the following:
- The end-user creates a personal account and uploads private data.
- The data is stored in the data lake and is preprocessed to follow the format that the FM expects.
- This triggers a fine-tuning ML pipeline that adds the model to the model registry,
- From there, either the model is deployed to production with minimum testing or the model pushes extensive testing with HIL and manual approval gates.
- The fine-tuned model is made available for end-users.
To simplify this complexity, AWS offers Amazon Bedrock, which streamlines deployment and brings fine-tuned foundation models closer to production.
The journey of consumers
Consumers must choose, test, and interact with a FM by providing prompts. These are specific inputs such as text, commands, or questions that guide the model’s response. The FM then generates outputs that end-users can use and evaluate. By rating these outputs, users help improve the model’s future performance. Some consumers seek deeper customization, tapping into fine-tuner capabilities via API backends to deliver personalized generative experiences. The following figure illustrates the consumer journey.
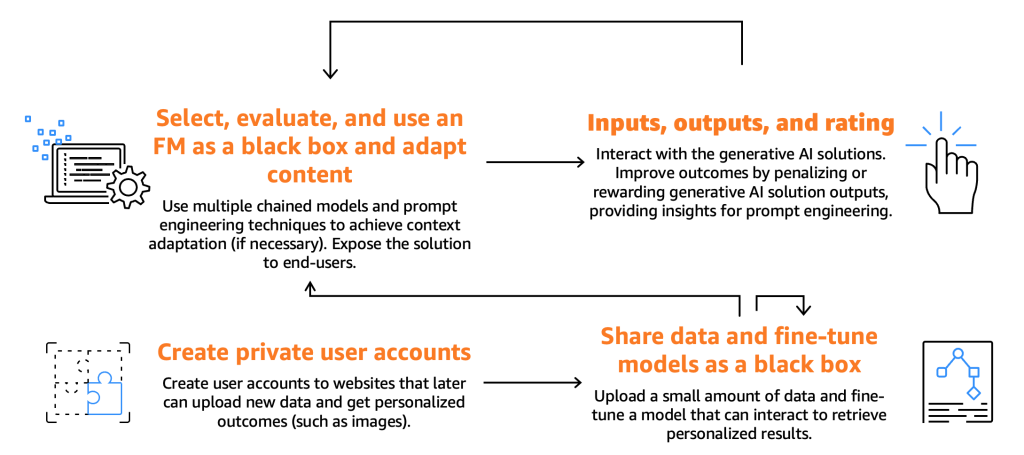
The rest of this section explores the consumer journey through the Generative AI lifecycle, showing how tasks like output evaluation, prompt management, and integration with agents or retrieval systems fit into GenAIOps and support moving from experimentation to production.
Step 1: Foundation Model Selection
Selecting the right model is the first and most foundational step in building a Generative AI solution. Model selection depends on factors like use case, data, and regulatory requirements. A useful, though not exhaustive, checklist includes:
- Functional requirements: Identify essential capabilities early, such as multi-modal support for document image analysis or function-calling for API orchestration, with domain-specific pre-trained models reducing prompt engineering needs.
- Performance-Cost: Balance model capability against operational expenses by testing both high-performance and smaller variants to understand the quality-cost curve and identify acceptable accuracy thresholds for your use case.
- Latency: Match model response times to application requirements, with real-time uses needing sub-second responses while analytical tasks can tolerate multi-second delays, including all processing overhead in your testing.
- Licensing and control: Proprietary models typically offer superior performance and reliability but come with licensing costs, while open-source models provide flexibility and fine-tuning capabilities at no cost, though some may have commercial licensing restrictions despite being freely available.
After you have compiled an overview of 10–20 potential candidate models, the focus shifts to refining it. The swift mechanism is one such approach outlined below to narrow the list of viable candidate models before commencing testing and evaluation.
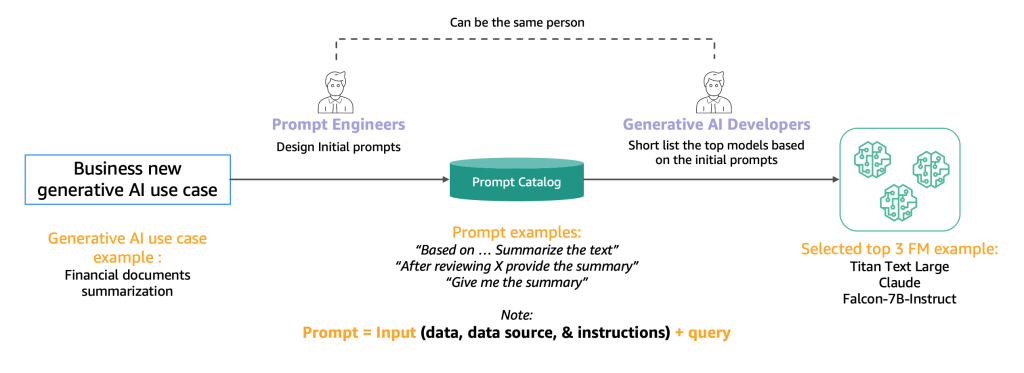
Prompt engineers systematically develop and test various prompts for specific tasks using a centralized prompt catalog—similar to a Git repository—that enables version control, prevents duplication, and ensures consistency across development teams. Generative AI developers then evaluate the outputs from these standardized prompts to determine model suitability for their applications.
Step 2. Testing and evaluation
Once the shortlist is narrowed to around 3 FMs, we recommend conducting an evaluation to assess their performance and fit for the use case. The choice of evaluation method depends on the data available, as shown in the following figure.
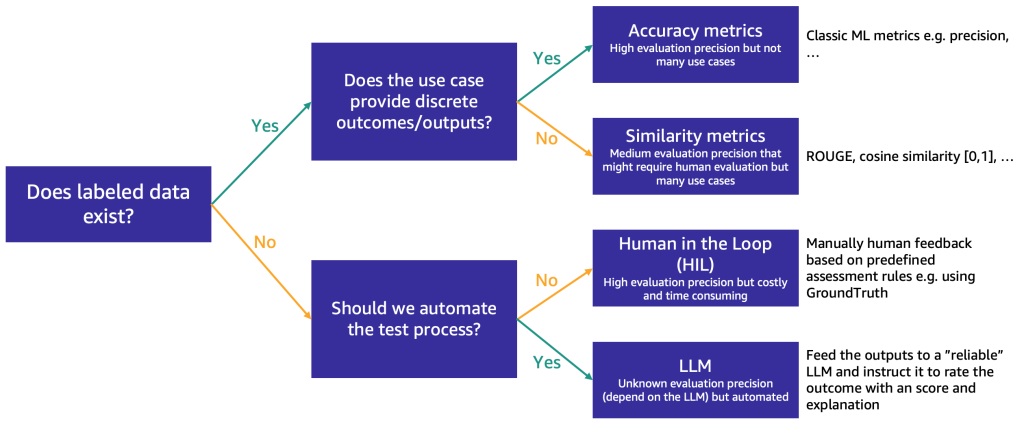
If you have labeled data, you can use it to conduct a model evaluation, as we do with the traditional ML models (input some samples and compare the output with the labels). Depending on whether the test data has discrete labels (such as positive, negative, or neutral sentiment analysis) or is unstructured text (such as summarization), we propose different methods for evaluation:
- Accuracy metrics: In case of discrete outputs (such as sentiment analysis), we can use standard accuracy metrics such as precision, recall, and F1 score
- Similarity metrics: If the output is unstructured (such as a summary), we suggest similarity metrics like ROUGE and cosine similarity
Some use cases don’t lend themselves to having one true answer (for example, “Create a short children’s story for my 5-year-old daughter”). In such cases, it becomes more challenging to evaluate the models because you don’t have labeled test data. We propose two approaches, depending on the importance of human review of the model versus automated evaluation:
- Human-in-the-Loop (HIL): In this case, a team of prompt testers will review the responses from a model. Depending on how critical the application is, the prompt testers might review 100% of the model outputs or just a sample.
- LLM-as-a-judge: In this scenario, the prompt testers are replaced by an LLM, ideally one that is more powerful (although perhaps slower and most costly) than the ones being tested. The LLM will review all model-generated responses and score them. This method may result in lower quality, but it’s a cheaper and faster evaluation option that might provide a good initial gauge on the models’ performance.
The following figure illustrates the end-to-end evaluation process.
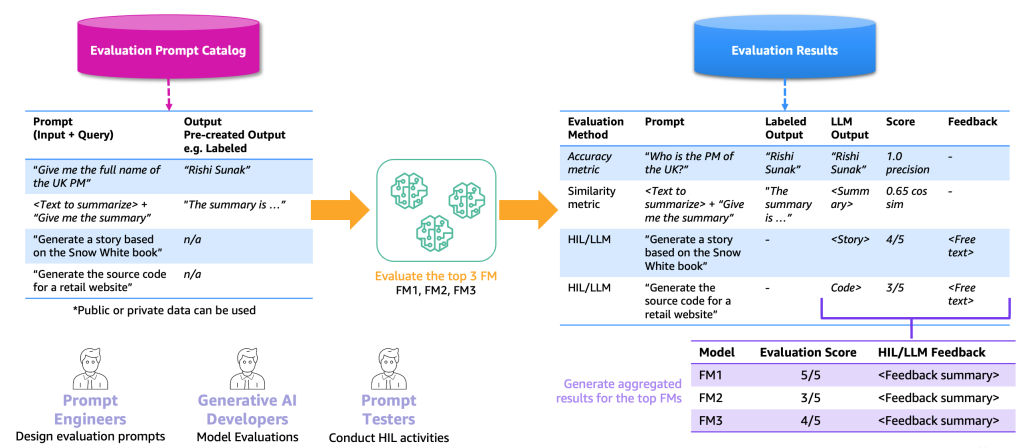
Model evaluation requires combining prompts from the catalog with either labeled datasets (containing expected outputs like “Rishi Sunak” for “Who was UK PM in 2023?”) or unlabeled datasets (containing only instructions like “Generate retail website code”). This combination forms an evaluation prompt catalog, which differs from the general prompt catalog by being tailored to specific use cases rather than containing generic, reusable prompts.
The evaluation prompts are fed to selected foundation models, generating results that include prompts, model outputs, and scores. For unlabelled datasets, human-in-the-loop or LLM-as-a-judge reviews provide scoring and feedback. Final aggregated results calculate average precision or human ratings to benchmark model quality across all outputs.
After gathering the evaluation results, select the model using several key dimensions – typically precision, speed, and cost. The following figure provides an example.
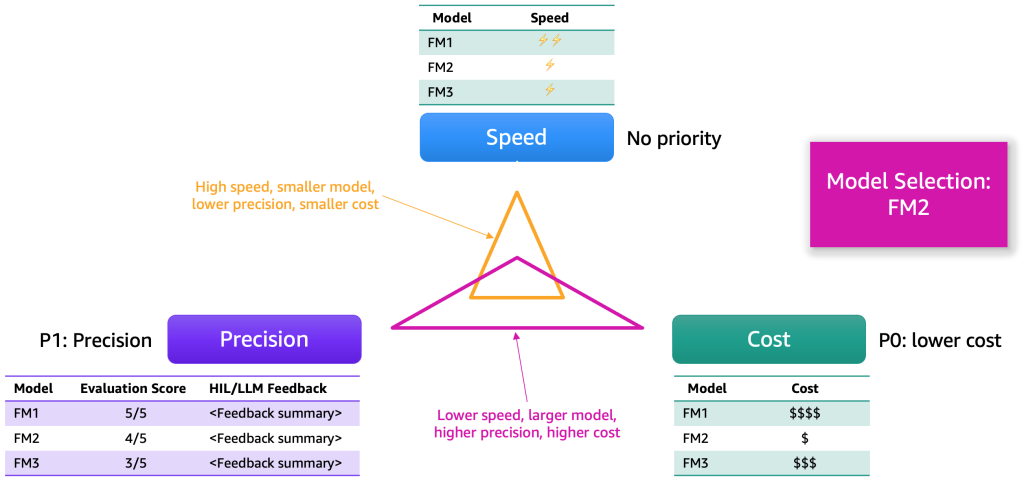
Each model offers distinct strengths and trade-offs across these dimensions. The relative importance of each depends on the use case. In the example above, cost was prioritized first, followed by precision and speed. Although FM2 is slower and less efficient than FM1, it delivers adequate performance at a much lower cost—making it the preferred option.
Step 3. Application integration
With the foundation model selected through collaboration between generative AI developers, prompt engineers, and testers, the next step involves integrating the generative AI capabilities into the application using a two-layer architecture comprising backend and frontend components, as illustrated in the following figure.
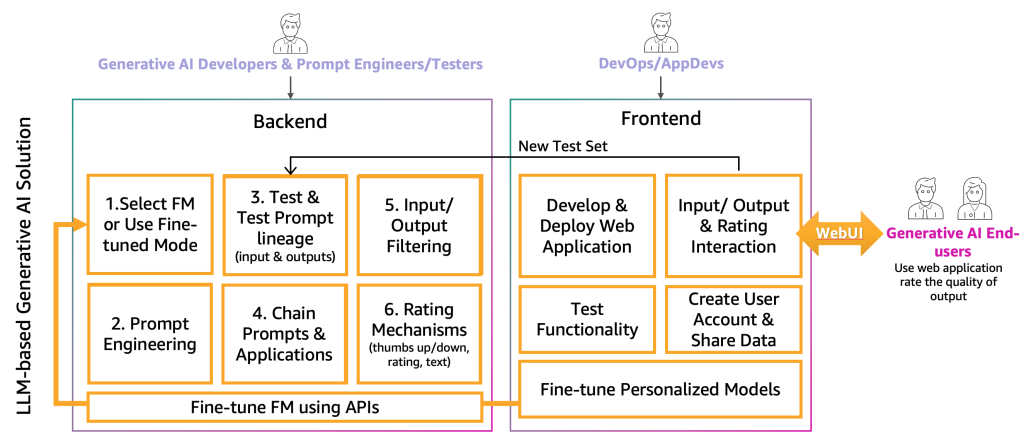
On the backend, the generative AI developers incorporate the selected FM into the solution and closely with prompt engineers to create automation that transforms end-user inputs into appropriate model prompts. Prompt testers contribute by creating necessary entries in the prompt catalog for both automatic and manual testing processes. The developers then implement prompt chaining, which is a technique that breaks complex tasks into manageable sub-tasks where each prompt builds upon previous responses, along with application mechanisms to deliver final outputs. To maintain quality standards, developers must also create monitoring and filtering systems for both inputs and outputs, such as toxicity detectors for applications that need to avoid harmful content. Additionally, they implement rating mechanisms that capture user feedback to continuously augment the evaluation prompt catalog with positive and negative examples.
To deliver functionality to end-users, a frontend web application is usually developed to interface with the backend services. DevOps teams and application developers follow established development best practices to implement user input/output functionality and rating systems. This frontend layer serves as the bridge between the sophisticated backend AI capabilities and the generative AI end-users, enabling seamless interaction and feedback collection that feeds back into the overall solution improvement cycle.
The application follows standard CI/CD practices across multiple environments to ensure quality and reliability, progressing from development to preproduction for extensive prompt testing, then to production through automated deployments triggered by branch merges. All artifacts including prompt catalogs, evaluation data, user interactions, and model metadata are stored in a centralized location (e.g. data lake), with CI/CD pipelines and repositories maintained in separate tooling accounts following MLOps best practices.
Conclusion
MLOps has proven effective for productionizing traditional ML models, but generative AI applications demand more. Beyond data pipelines and model training, they require new skills, processes, and technologies. These range from prompt management and evaluation of non-deterministic outputs to orchestration of agents and cost governance. This is where GenAIOps emerges: an operational discipline that extends MLOps and DevOps to meet the unique needs of generative AI.
In this post, we explored how GenAIOps differs from MLOps across people, processes, and platforms. We highlighted the distinct roles of providers, fine-tuners, and consumers, and showed how their operational challenges vary. Finally, we walked through the lifecycle of building generative AI applications, illustrating why a GenAIOps mindset is essential to move from experimentation to reliable, production-grade systems.
About the Authors
 Dr. Sokratis Kartakis is a Senior Machine Learning and Operations Specialist Solutions Architect for Amazon Web Services. Sokratis focuses on enabling enterprise customers to industrialize their Machine Learning (ML) solutions by exploiting AWS services and shaping their operating model, i.e. MLOps foundation, and transformation roadmap leveraging best development practices. He has spent 15+ years on inventing, designing, leading, and implementing innovative end-to-end production-level ML and Internet of Things (IoT) solutions in the domains of energy, retail, health, finance/banking, motorsports etc. Sokratis likes to spend his spare time with family and friends, or riding motorbikes.
Dr. Sokratis Kartakis is a Senior Machine Learning and Operations Specialist Solutions Architect for Amazon Web Services. Sokratis focuses on enabling enterprise customers to industrialize their Machine Learning (ML) solutions by exploiting AWS services and shaping their operating model, i.e. MLOps foundation, and transformation roadmap leveraging best development practices. He has spent 15+ years on inventing, designing, leading, and implementing innovative end-to-end production-level ML and Internet of Things (IoT) solutions in the domains of energy, retail, health, finance/banking, motorsports etc. Sokratis likes to spend his spare time with family and friends, or riding motorbikes.
 Heiko Hotz is a Senior Solutions Architect for AI & Machine Learning with a special focus on natural language processing, large language models, and generative AI. Prior to this role, he was the Head of Data Science for Amazon’s EU Customer Service. Heiko helps our customers be successful in their AI/ML journey on AWS and has worked with organizations in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. In his spare time, Heiko travels as much as possible.
Heiko Hotz is a Senior Solutions Architect for AI & Machine Learning with a special focus on natural language processing, large language models, and generative AI. Prior to this role, he was the Head of Data Science for Amazon’s EU Customer Service. Heiko helps our customers be successful in their AI/ML journey on AWS and has worked with organizations in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. In his spare time, Heiko travels as much as possible.
 Nicholas Moore is a Solutions Architect at AWS, helping startups and businesses of all sizes turn ideas into reality. He specializes in cloud solutions with a focus on AI, analytics, and modern application development.
Nicholas Moore is a Solutions Architect at AWS, helping startups and businesses of all sizes turn ideas into reality. He specializes in cloud solutions with a focus on AI, analytics, and modern application development.
 Nishant Dhiman is a Senior Solutions Architect at AWS based in Sydney. He comes with an extensive background in Serverless, Generative AI, Security and Mobile platform offerings. He is a voracious reader and a passionate technologist. He loves to interact with customers and believes in giving back to community by learning and sharing. Outside of work, he likes to keep himself engaged with podcasts, calligraphy and music.
Nishant Dhiman is a Senior Solutions Architect at AWS based in Sydney. He comes with an extensive background in Serverless, Generative AI, Security and Mobile platform offerings. He is a voracious reader and a passionate technologist. He loves to interact with customers and believes in giving back to community by learning and sharing. Outside of work, he likes to keep himself engaged with podcasts, calligraphy and music.
Audit History
Last reviewed and updated in December 2025 by Nicholas Moore and Nishant Dhiman