Artificial Intelligence
Category: Artificial Intelligence

Amazon SageMaker HyperPod enhances ML infrastructure with scalability and customizability
In this post, we introduced three features in SageMaker HyperPod that enhance scalability and customizability for ML infrastructure. Continuous provisioning offers flexible resource provisioning to help you start training and deploying your models faster and manage your cluster more efficiently. With custom AMIs, you can align your ML environments with organizational security standards and software requirements.

Fine-tune OpenAI GPT-OSS models using Amazon SageMaker HyperPod recipes
This post is the second part of the GPT-OSS series focusing on model customization with Amazon SageMaker AI. In Part 1, we demonstrated fine-tuning GPT-OSS models using open source Hugging Face libraries with SageMaker training jobs, which supports distributed multi-GPU and multi-node configurations, so you can spin up high-performance clusters on demand. In this post, […]
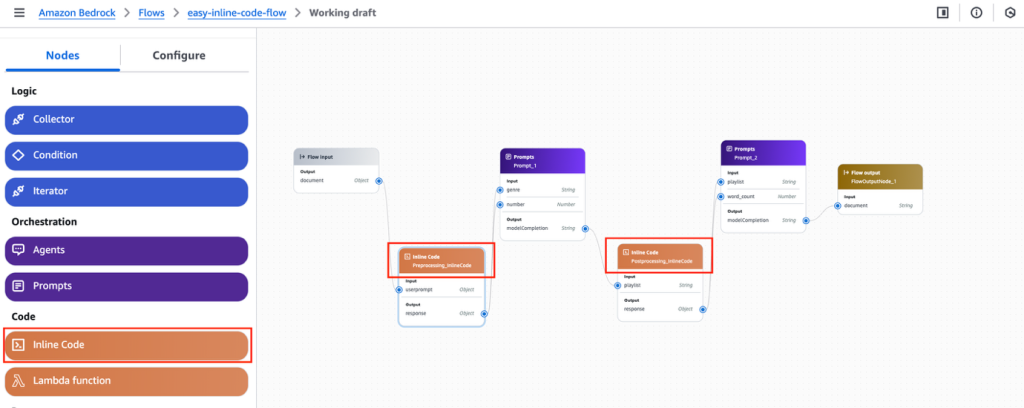
Inline code nodes now supported in Amazon Bedrock Flows in public preview
We are excited to announce the public preview of support for inline code nodes in Amazon Bedrock Flows. With this powerful new capability, you can write Python scripts directly within your workflow, alleviating the need for separate AWS Lambda functions for simple logic. This feature streamlines preprocessing and postprocessing tasks (like data normalization and response formatting), simplifying generative AI application development and making it more accessible across organizations.
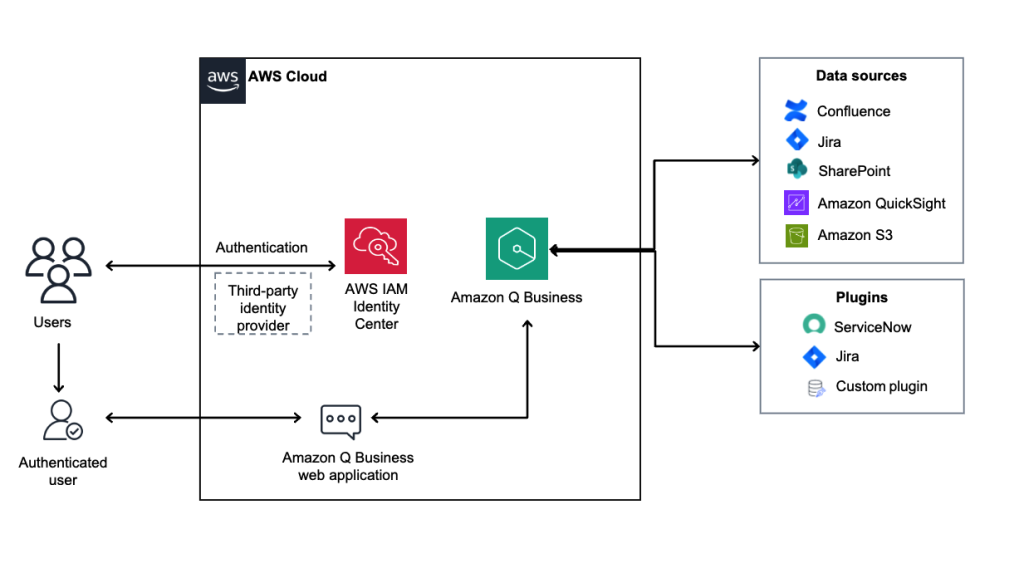
Accelerate enterprise AI implementations with Amazon Q Business
Amazon Q Business offers AWS customers a scalable and comprehensive solution for enhancing business processes across their organization. By carefully evaluating your use cases, following implementation best practices, and using the architectural guidance provided in this post, you can deploy Amazon Q Business to transform your enterprise productivity. The key to success lies in starting small, proving value quickly, and scaling systematically across your organization.

Speed up delivery of ML workloads using Code Editor in Amazon SageMaker Unified Studio
In this post, we walk through how you can use the new Code Editor and multiple spaces support in SageMaker Unified Studio. The sample solution shows how to develop an ML pipeline that automates the typical end-to-end ML activities to build, train, evaluate, and (optionally) deploy an ML model.
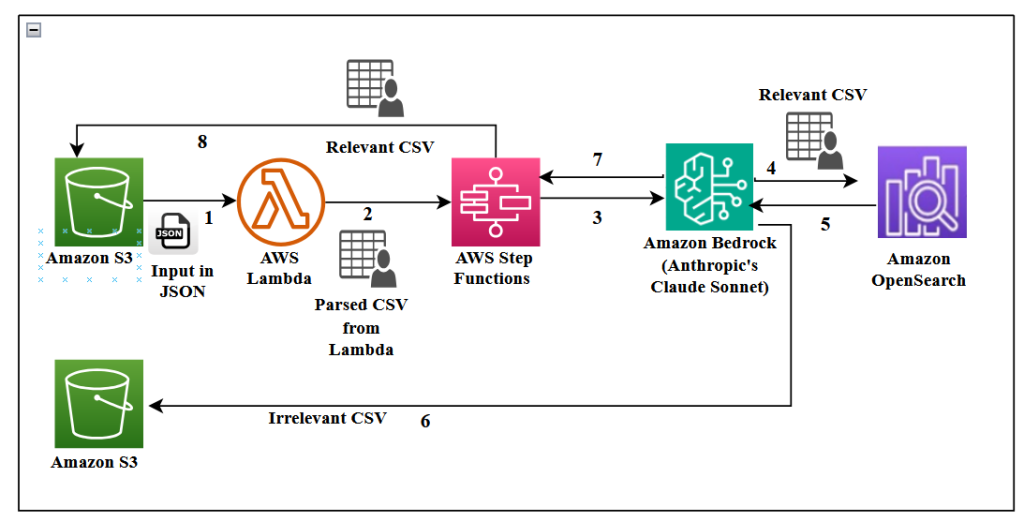
How Infosys Topaz leverages Amazon Bedrock to transform technical help desk operations
In this blog, we examine the use case of a large energy supplier whose technical help desk agents answer customer calls and support field agents. We use Amazon Bedrock along with capabilities from Infosys Topaz™ to build a generative AI application that can reduce call handling times, automate tasks, and improve the overall quality of technical support.

Create personalized products and marketing campaigns using Amazon Nova in Amazon Bedrock
Built using Amazon Nova in Amazon Bedrock, The Fragrance Lab represents a comprehensive end-to-end application that illustrates the transformative power of generative AI in retail, consumer goods, advertising, and marketing. In this post, we explore the development of The Fragrance Lab. Our vision was to craft a unique blend of physical and digital experiences that would celebrate creativity, advertising, and consumer goods while capturing the spirit of the French Riviera.
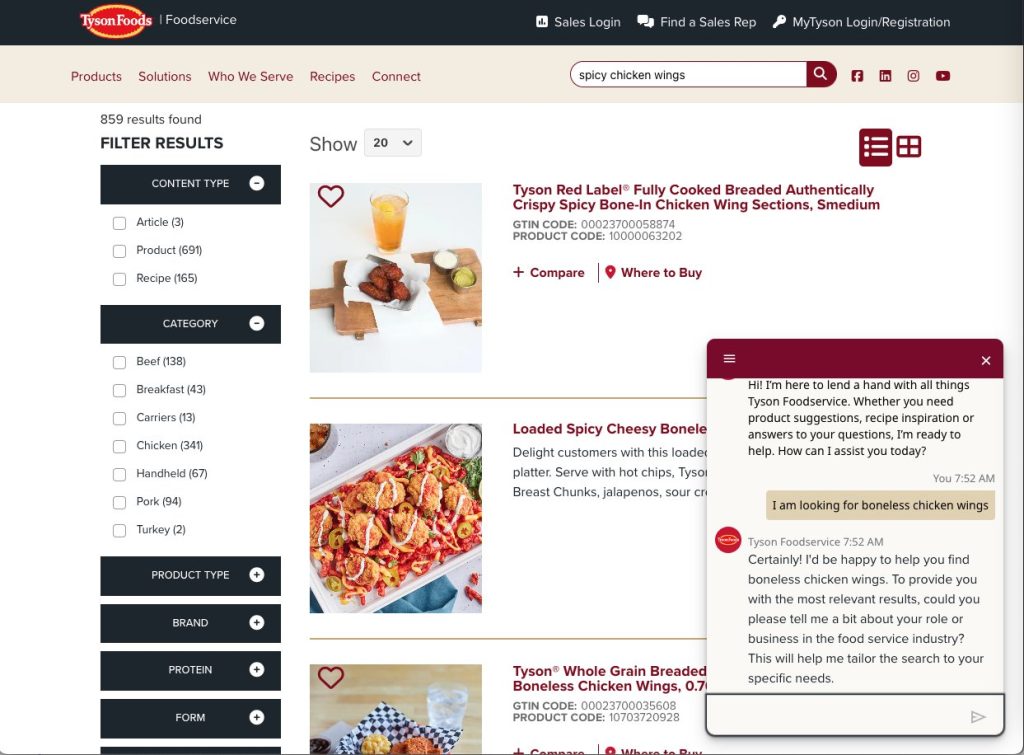
Tyson Foods elevates customer search experience with an AI-powered conversational assistant
In this post, we explore how Tyson Foods collaborated with the AWS Generative AI Innovation Center to revolutionize their customer interaction through an intuitive AI assistant integrated into their website. The AI assistant was built using Amazon Bedrock,
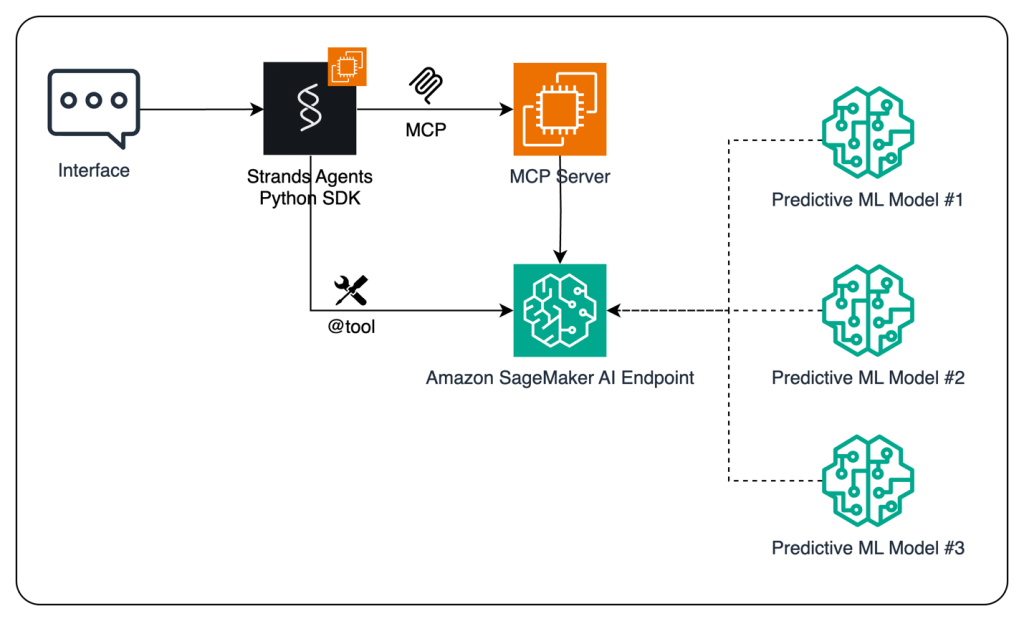
Enhance AI agents using predictive ML models with Amazon SageMaker AI and Model Context Protocol (MCP)
In this post, we demonstrate how to enhance AI agents’ capabilities by integrating predictive ML models using Amazon SageMaker AI and the MCP. By using the open source Strands Agents SDK and the flexible deployment options of SageMaker AI, developers can create sophisticated AI applications that combine conversational AI with powerful predictive analytics capabilities.
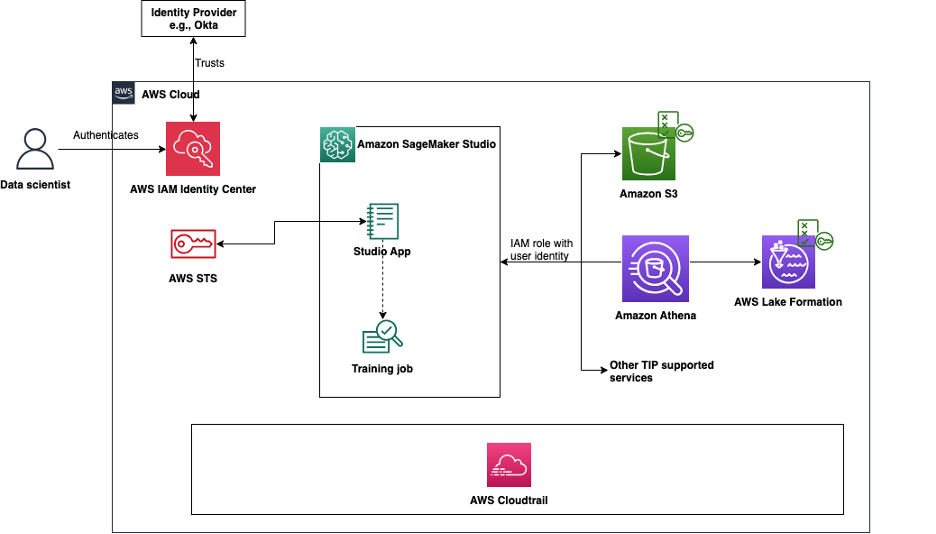
Simplify access control and auditing for Amazon SageMaker Studio using trusted identity propagation
In this post, we explore how to enable and use trusted identity propagation in Amazon SageMaker Studio, which allows organizations to simplify access management by granting permissions to existing AWS IAM Identity Center identities. The solution demonstrates how to implement fine-grained access controls based on a physical user’s identity, maintain detailed audit logs across supported AWS services, and support long-running user background sessions for training jobs.